At least once Streaming: Save up to 70% for Streaming ETL workloads
Slava Chernyak
Technical Lead, Dataflow Streaming
Yuriy Zhovtobryukh
Senior Product Manager, Google
Historically, Dataflow Streaming Engine has offered exactly-once processing for streaming jobs. Recently, we launched at-least-once streaming mode as an alternative for lower latency and cost-of-streaming data ingestion. In this post, we will explain both streaming modes and provide guidance on how to choose the right mode for your streaming use case.
Exactly-once: what it is and why it matters
Applications that react to incoming events sometimes require that each event be reflected in the output exactly once — meaning the event is not lost, nor accepted more than a single time. But as the processing pipeline scales, load-balances, or encounters faults, that deduplication of events imposes a computational cost, affecting overall cost and latency of the system.
Dataflow Streaming provides an exactly-once guarantee, meaning that the effects of data processed in the pipeline are reflected at least and at most once. Let’s unpack that a little bit. For every arriving message, whether it's from an external source or an upstream shuffle, Dataflow ensures that the message will be processed and not lost (at-least-once). Additionally, results of that processing that remain within the pipeline, like state updates and outputs to a subsequent shuffle to the next pipeline stage, are also reflected at-most once. This guarantee enables, among other things, performing exact aggregations, such as exact sums or counts.
Exactly-once inside the pipeline is usually only half the story. As pipeline authors and runners, we really want to get the results of processing out of Dataflow and into a downstream system. Here we run into a common roadblock: no general at-most-once guarantee is made about side-effects of the pipeline. Without further effort, any side-effect, such as output to an external store, may generate duplicates. Careful work must be done to orchestrate the writes in a way that avoids duplicates. The key challenge is that in the general case, it is not possible to implement exactly-once operation in a distributed system without a consensus protocol that involves all the actors. For internal state changes, such as state updates and shuffle, exactly-once is achieved by a careful protocol.
With sufficient support from data sinks, we can thus have exactly-once all the way through the pipeline and to its output. An example is the storage write version of the BigQueryIO.Write implementation, which ensures exactly-once data extraction to BigQuery.
But even without exactly-once semantics at the sink, exactly-once semantics within the pipeline can be useful. Duplicates on the output may be acceptable, as long as they are duplicates of correct results — with exactly-once having been required to achieve this correctness.
At-least once: what it is and why it matters
There are other use cases where duplicates may be acceptable, for example ETL or Map-Only pipelines that are not performing any aggregation but rather only per-message operations. In these cases, duplicates are simple replays of data through the pipeline.
But why wouldn’t you choose to use exactly-once semantics? Aren’t stronger guarantees always better? The reason is that achieving exactly-once adds to pipeline latency and cost. This happens for several reasons, some obvious, and some quite subtle. Let's take a deeper look.
In order to achieve exactly-once, we must store and read exactly-once metadata. In practice, the storage and read costs incurred to do this turn out to be quite expensive, especially in pipelines that otherwise perform very little I/O. Less intuitively, having to perform this metadata-based deduplication dictates how we implement the backend.
For example, in order to deduplicate messages across the shuffle we must ensure that all replays are idempotent — which means we must checkpoint the results of processing before they are sent to shuffle — which again increases cost and latency.
Another example: to de-duplicate the input from Pub/Sub, we must first re-shuffle incoming messages on keys that are deterministically derived from a given message because the deduplication metadata is stored in the per-key state. Performing this shuffle using deterministic keys exposes us to additional cost and latency. In the next section we lay out the reasons for this in more detail.
We cannot assume that at-least-once semantics are acceptable for the user, so we default to the strictest semantics, i.e., exactly-once. If we know beforehand that at-least-once processing is acceptable, and we can relax our constraints, then we can make more cost- and latency-beneficial implementation decisions.
Exactly-once vs. at-least-once when reading from Pub/Sub
Pub/Sub reads’ latency and cost in particular benefit from at-least-once mode. To understand why, let’s look closer at how exactly-once deduplication is implemented.
Pub/Sub reads are implemented in the Dataflow backend workers. To acquire new messages, each Dataflow backend worker makes remote procedure calls (RPCs) internally to the Pub/Sub service. Since RPCs can fail, workers may crash, or other sources of failure are possible, and messages will be replayed until successful processing is acknowledged by the backend worker. Pub/Sub and backend workers are dynamic systems, without static partitioning, meaning that replays of messages from Pub/Sub are not guaranteed to arrive at the same backend worker. This poses a challenge when deduplicating these messages.
In order to perform deduplication, the backend worker puts these messages through a shuffle, attaching a key internally to each message. The key is chosen deterministically based on the message, or a message id attribute if configured, so that a replay of a duplicate message is deterministically shuffled to the same key. Doing so allows deduplicating replays from Pub/Sub in the same manner that shuffle replays are deduplicated between stages in the Dataflow pipeline (see this detailed discussion), as illustrated in the sequence diagram below:
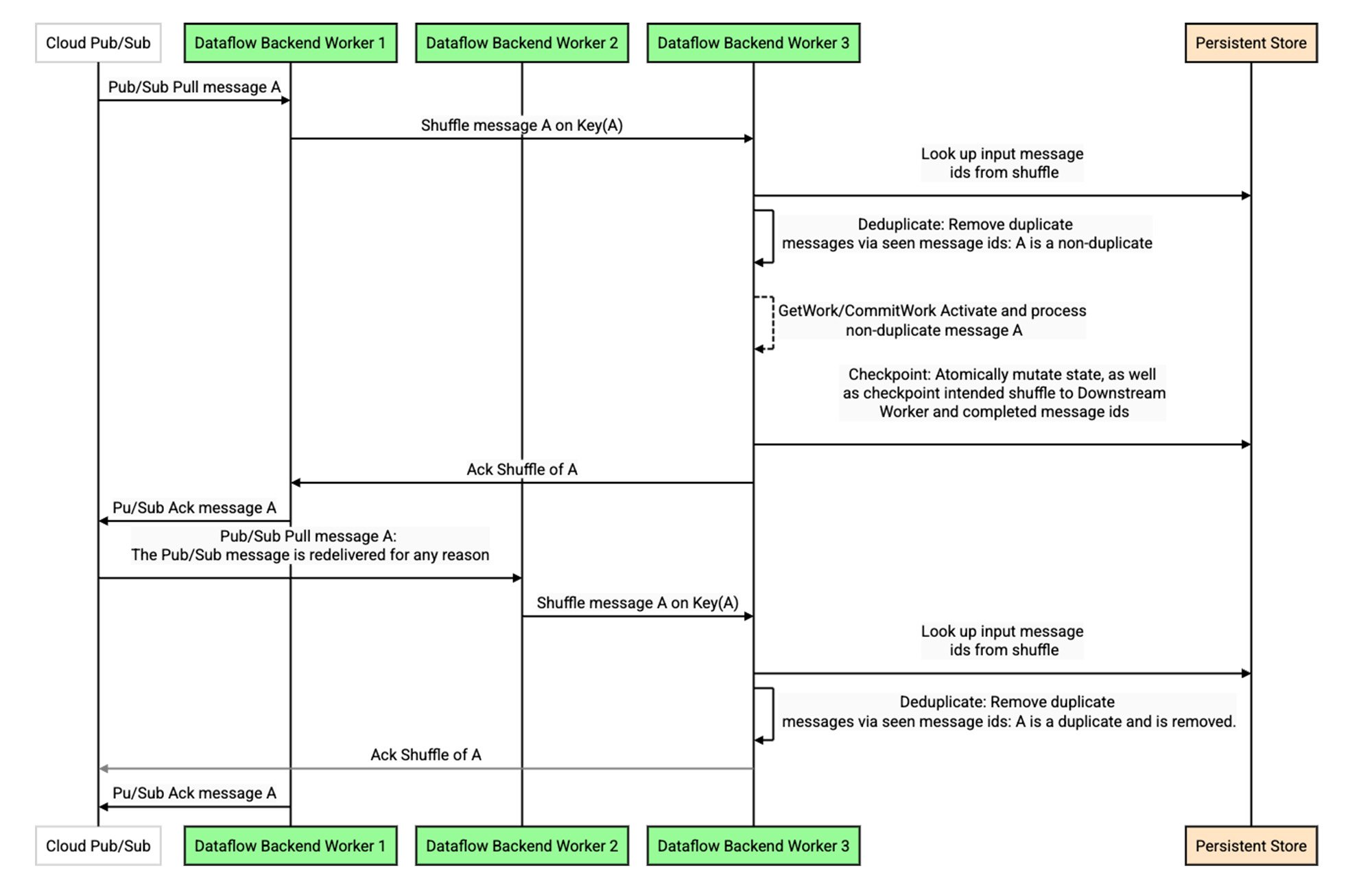
This design contributes to cost and latency in two significant ways. First, as with all deduplication in the Dataflow backend, a read against the persistent store may be required. While heavily optimized with caches and bloom filters, it cannot be completely eliminated. Second, and often even more significant, is the need to shuffle the data on a deterministic key. If a particular key or worker is slow or becomes a bottleneck, this creates head-of-line blocking that prevents other traffic from flowing — an artificial constraint since the messages in the queue are not semantically tied to this key.
When at-least-once processing is acceptable, we can both eliminate the cost associated with reads from the persistent store and the shuffling of messages on a deterministic key. In fact, we can do better — we still shuffle the messages, but the key we pick instead is the current “least-loaded” key, meaning the key that is currently experiencing the least queueing. In this way, we evenly distribute the incoming traffic to maximize throughput, even when some keys or workers are experiencing slowness.
We can see this in action in a benchmark where we simulate stragglers, e.g., slow writes to an external sink, by artificially delaying arbitrary messages at low probability for multi-minute intervals.
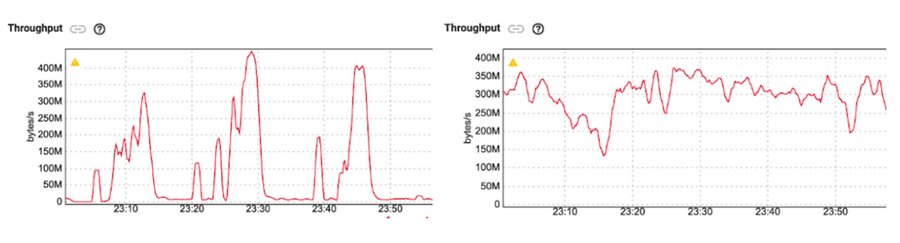
Compare the throughput of the exactly-once pipeline on the left to the throughput of the at-least-once pipeline on the right. The at-least-once pipeline can sustain much more consistent throughput in the presence of such stragglers, dramatically decreasing average latency. In other words, even though both cases still have high tail latency, the latency outliers no longer affect the bulk of the distribution in the at-least-once configuration.
Benchmarks: at-least-once vs. exactly-once
Here are three representative benchmark streaming jobs to evaluate the impact of streaming-mode choice on costs. To maximize the cost benefit, we enabled resource-based billing and aligned I/O to the streaming mode. Here is what we observed:
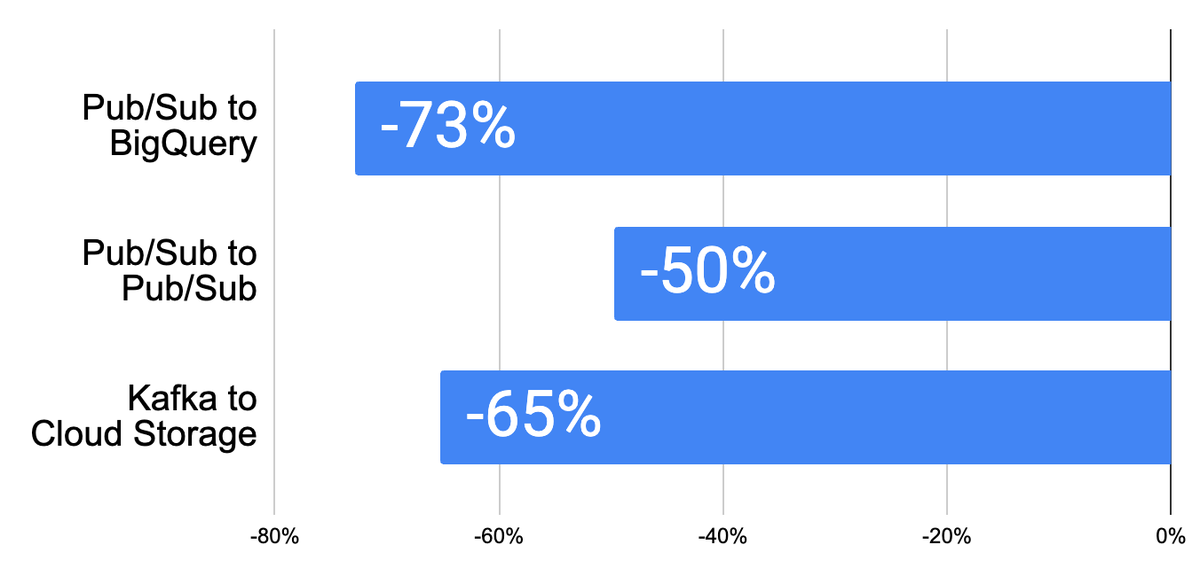
Note that cost depends on multiple factors such as data-load characteristics, the specific pipeline composition, configuration and the I/O used. Therefore, our benchmarking results may differ from what you observe in your test and production pipelines.
Spotify’s own testing supported the Dataflow team’s findings:
"By incorporating at-least-once mode in our platform that is built on Dataflow, Pub/Sub, and Bigtable, we have seen a portion of our Dataflow jobs cut costs by 50%. Since this is used by several consumers, 7 downstream systems are now cheaper overall with this simple change. Because of the way this system works, there has been 0 effects of duplicates! We plan on turning this feature on in more jobs that are compatible to cut down our Dataflow costs even more." - Sahith Nallapareddy, Software Engineer, Spotify
Choose the right streaming mode for your job
When creating streaming pipelines, choosing the right mode is essential. The critical factor is to determine whether the pipeline can tolerate duplicate records in the output or any intermediate processing stages.
At-least-once mode can help optimize cost and performance in the following cases:
-
Map-only pipelines performing idempotent per-message operations, e.g. ETL jobs
-
When deduplication happens in the destination, e.g., in BigQuery or Bigtable
-
Pipelines that already use an at-least-once I/O sink, e.g., Storage API At Least Once or PubSub I/O
Exactly-once mode is preferable in the following cases:
-
Use cases that cannot tolerate duplicates within Dataflow
-
Pipelines that perform exact aggregations as part of stream processing
-
Map-only jobs that perform non-idempotent per-message operations
At-least-once streaming mode is now generally available for Dataflow streaming customers. You can enable at-least-once mode by setting the at-least-once Dataflow service option when starting a new streaming job using the API or gcloud. To get started, we also offer a selection of commonly used Dataflow streaming templates that support the streaming modes.

