Discover, understand and manage your data with Data Catalog, now GA
Shekhar Bapat
Product Manager, Data Catalog
Google Cloud Data Catalog is a fully managed and scalable metadata management service. It can help your organization quickly discover, understand, and manage all your data from one simple interface. Accessible from within the Google Cloud console, Data Catalog allows immediate access to data discovery without requiring any upfront setup.
The Data Catalog service is now generally available, providing regionalized service in 23 different regions globally. In addition to providing higher resilience against potential outages, the regionalized service delivers metadata residency at rest in each of the supported regions while providing a unified view of all data assets distributed across multiple regions.
Most organizations today are dealing with a large and growing number of data assets, and want to open up access to that data so business users can find the right data assets through self-service. Past approaches have failed to scale up, required tedious set up, and did not deliver easy data discovery for all.
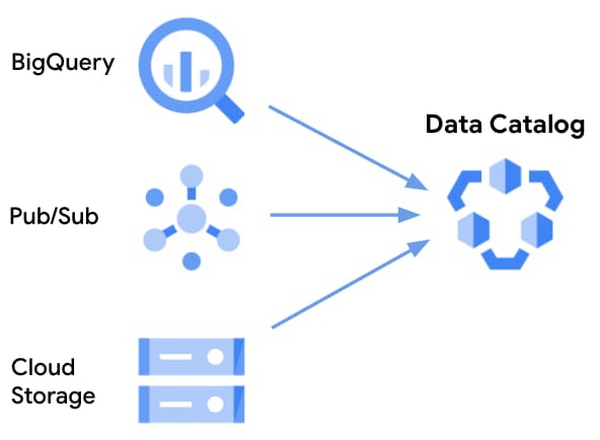
At Google, we also faced this challenge for large and growing data assets, and built an internal data catalog service to help bring comprehensive metadata management to all data users. You can see more about the techniques used to build an effective data catalog in Goods: Organizing Google’s Datasets. Data Catalog builds on that foundation, bringing a scalable managed service to all Google Cloud users for data within BigQuery, Pub/Sub, and Cloud Storage. Here are some details on how Data Catalog works, and how it can help.
Auto-syncing technical metadata
Technical metadata for all Google BigQuery data assets like datasets, tables, and views is synced into Data Catalog on a continuous basis. This means you can start using Data Catalog instantly and don’t need to deal with any tedious setup. Data Catalog also auto-syncs technical metadata from Pub/Sub and user-created filesets from Cloud Storage. These filesets are simple to create—you just need to specify a pattern with wildcards and apply it to a bucket. A fileset groups together all files in the bucket that match the wildcard pattern.
Technical metadata vs. business metadata
Technical metadata refers to metadata that is available in the source system. Technical metadata for a BigQuery table includes table name, table description, column names, column types, column descriptions, creation date, last modification date, and more. For Pub/Sub, technical metadata refers to Pub/Sub topic names and date created. For Cloud Storage filesets, technical metadata refers to the fileset name, the pattern used for creating the fileset, creation date, and modification date.
Business metadata refers to the collection of metadata that is critical for business and operational purposes but is not available in technical metadata. Business metadata might include the person responsible for a particular data asset, whether the data asset contains personally identifiable information (PII), if the data is approved for official use, the data retention policy for the data asset, the life cycle stage of the data asset, the data quality score, any known data quality issues, or data asset freshness. Data Catalog supports structured tags for capturing complex business metadata (more on that below).
Data discovery
Data Catalog can be used from a Google Cloud project by simply enabling it in that project. Data Catalog discovers data assets that are located not only in the project where the API is enabled but across all projects and across all regions. Support for data assets outside of BigQuery, Pub/Sub and Cloud Storage are in the Data Catalog roadmap, while support for non-Google Cloud data sources are available through open-source connectors (see below).
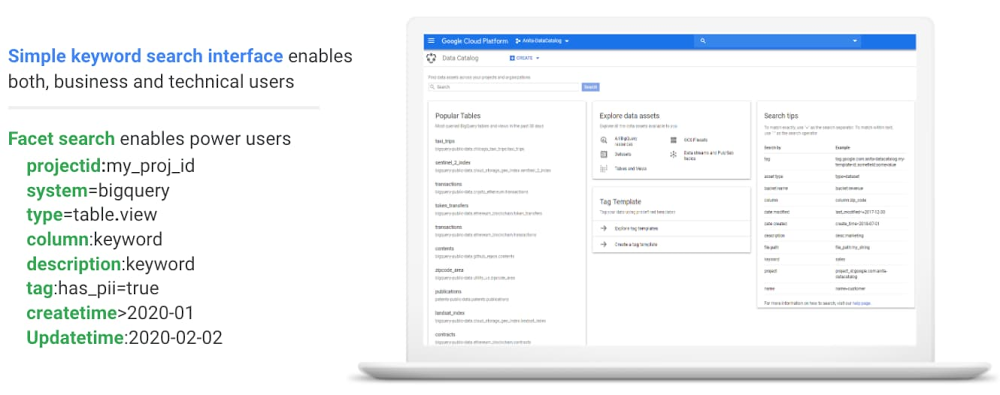
You can use Data Catalog to search for all your data assets by simply typing a keyword and discovering all matching data assets. You can also narrow down your search to locate data assets in specific projects, systems, types of data assets, or data assets created during specific time periods.
Structured tags for business metadata
At Google, we believe that simple string tags, once used widely, are no longer sufficient to capture the richness of business metadata. With Data Catalog, you can create tags with structure such that each tag contains multiple attributes, and each attribute is of one of the types string, double, boolean, enumerated, and datetime. Creating structured tags is a two-step process. First, define the structure of your tag in a tag template, then create tags with metadata that adhere to the template. You can attach each tag to individual data assets like datasets, tables, views, and even columns.
As illustrated below, the structured tags on data assets provide rich business metadata to all data users. You as a data analyst or a data scientist can search for specific tags and better understand your data assets with the business context provided by the collection of tags. You as a data curator or a data governor can better manage data assets by using the metadata on data quality and data governance.

Access control for metadata
Data Catalog is integrated with Cloud Identity and Access Management (Cloud IAM). All operations, including search for data discovery, are serviced in accordance with the applicable access control specifications. If user A has read access to a data asset and user B does not have any access to that data asset, a search carried out by user A reveals the data asset, while the same search carried out by user B does not return the data asset.
Metadata can be sensitive in nature and data governance teams might want certain business metadata tags to be visible only to select groups of users. Data Catalog provides access control on templates, and the access control extends to all tags created using that template.
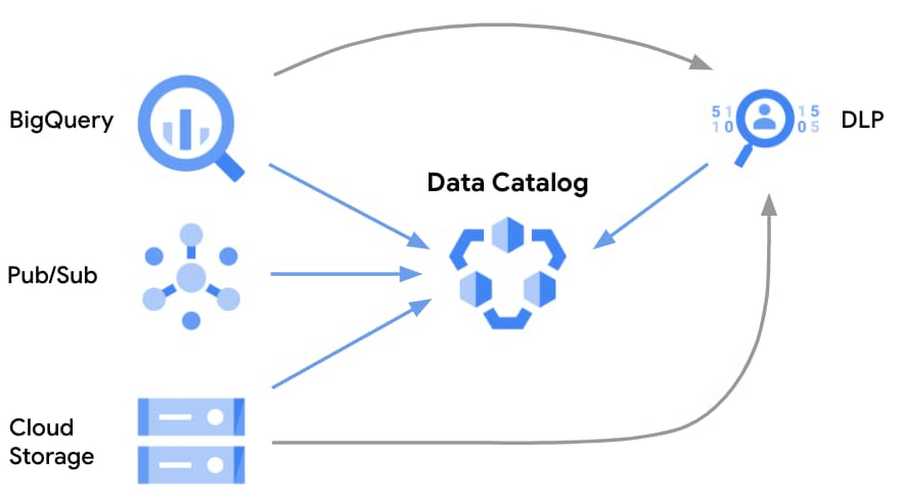
Auto-tagging PII data with Cloud DLP
Data Catalog’s integration with Cloud Data Loss Prevention (Cloud DLP) enables users to run Cloud DLP inspection jobs on BigQuery and automatically create Data Catalog tags for identifying PII data. You can find this in the Cloud DLP interface. You can also refer to the Google tutorial Create Data Catalog tags by inspecting BigQuery data with Cloud Data Loss Prevention and use the accompanying source code.
Data Catalog support for non-Google Cloud data assets
The Data Catalog API supports ingestion of technical metadata from non-Google Cloud data assets as well. The open-source connectors are organized in four Google Cloud Github repositories: datacatalog-connectors contains the common components for all connectors; datacatalog-connectors-rdbms has connectors for Oracle, SQL Server, Teradata, Redshift, PostgreSQL, MySQL, Vertica, and Greenplum; datacatalog-connectors-bi hosts connectors for Looker and Tableau; and data catalog-connectors-hive provides the connector for Hive with the option for live syncing.
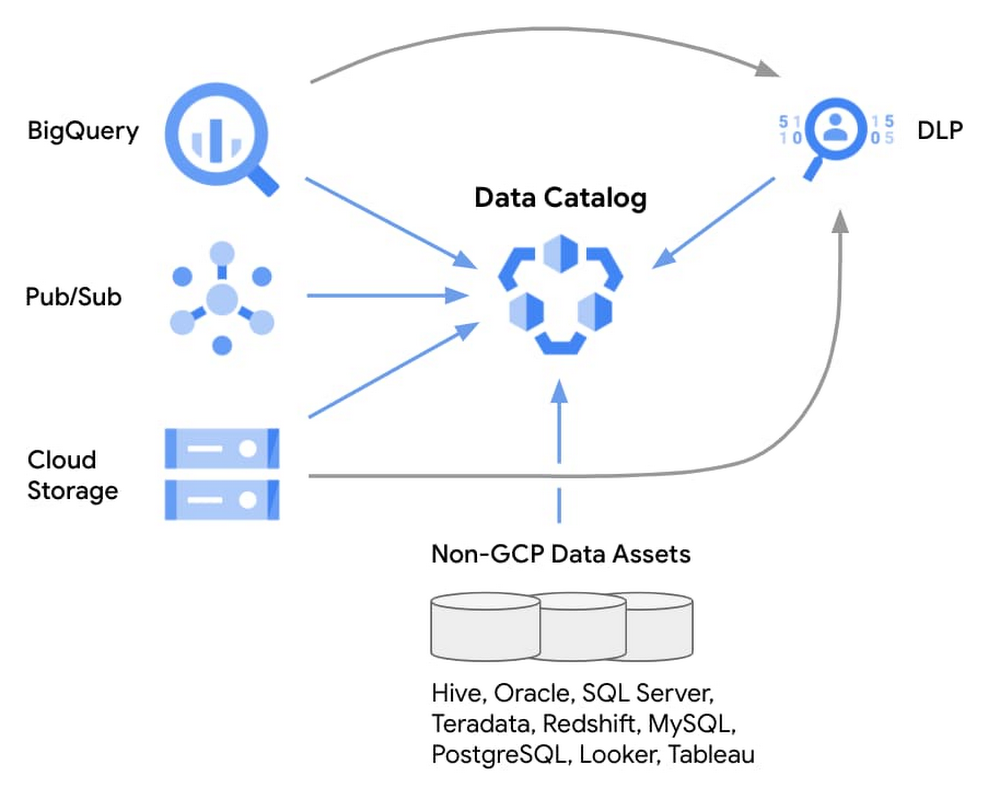
You can attach structured metadata tags on the Data Catalog entries for data assets that reside outside of Google Cloud. The single interface of Data Catalog lets you discover, annotate, and manage all your data assets.
Next steps with Data Catalog
Data Catalog is now GA and provides self-service data discovery at scale to enterprise users across all regions. Getting started with Data Catalog couldn’t be easier, as it does not require any setup to quickly discover, understand, and manage all your data in Google Cloud and supports ingesting on-premises metadata from non-Google Cloud data sources. Learn more about Data Catalog, check out our comprehensive documentation, or try the Quickstart guide.

