How to optimize your existing queries with search indexes
Huong Phan
Engineering Lead, BigQuery Search
Omid Fatemieh
Senior Engineering Manager, Google Cloud
In October 2022, BigQuery launched the search indexes and SEARCH function that enable using Google Standard SQL to efficiently pinpoint specific data elements in unstructured text and semi-structured data. In a previous blog post, we demonstrated the performance gains achievable by utilizing search indexes on the SEARCH function.
Today, BigQuery expands the optimization capabilities to a new set of SQL operators and functions, including the equal operator (=), IN operator, LIKE operator, and STARTS_WITH function when used to compare string literals with indexed data. This means that if you have a search index on a table, and a query that compares a string literal to a value in the table, BigQuery can now use the index to find the rows that match the query more quickly and efficiently.
For more information about which existing functions/operators are eligible for search index optimization, refer to the Search indexed data documentation.
In this blog post we cover the journey from creating an index and efficiently retrieving, via a few illustrative examples, and share some measured performance gain numbers.
Take Advantage of Search Index Optimizations with Existing SQLs
Before this launch, the only way to take advantage of a BigQuery search index was to use the SEARCH function. The SEARCH function is powerful. In addition to column-specific, it supports cross-column search, which is particularly helpful in cases of complex schemas with hundreds of columns, including nested ones. It also provides powerful case sensitive and case insensitive tokenized search semantics.
Even though the SEARCH function is very versatile and powerful, it may not always provide the exact result semantics one may be looking for. For example, consider the following table that contains a simplified access log of a file sharing system:
Table: Events
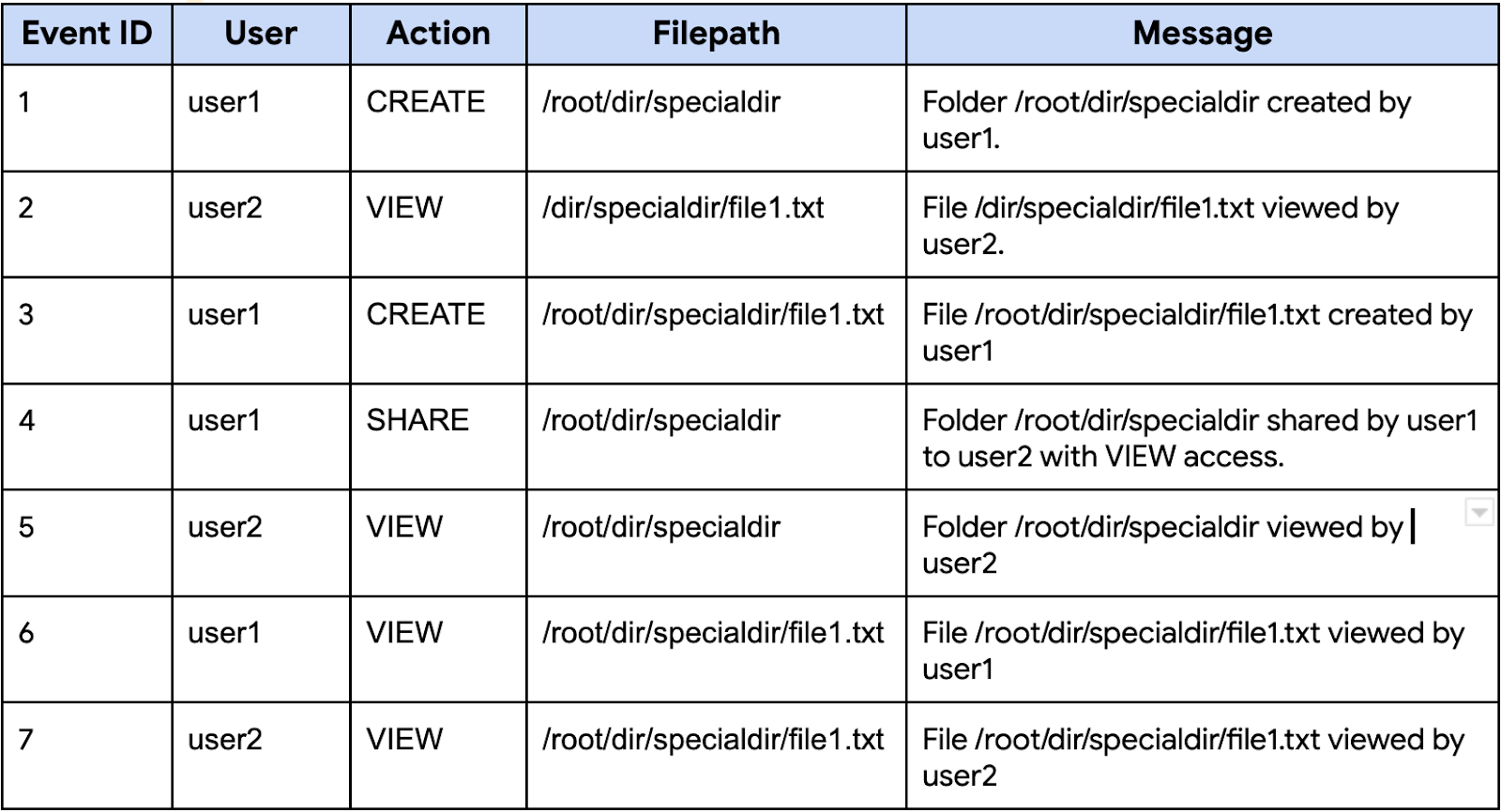
The SEARCH function allows searching for a token that appears anywhere in the table. For example, you can look for any events that involve "specialdir" with the following query:
The above query will return all rows from the above table.
However, consider the case where you want a more specific result -- only events related to the folder "/root/dir/specialdir". Using the SEARCH function as in the following query will return more rows than desired:
The above query also returns all rows except the one with Event ID 2. The reason is SEARCH is a token search function, it returns true as long as the searched data contains all the searched tokens. That means, SEARCH("/root/dir/specialdir/file1.txt", "/root/dir/specialdir") returns true. Even using backticks to enforce case sensitivity and the exact order of tokens would not help, SEARCH("/root/dir/specialdir/file1.txt", "`/root/dir/specialdir`") also returns true.
Instead, we can use the EQUAL operator to make sure that the result only contains the events related to the folder, not the files in the folder.
Query 3 Results
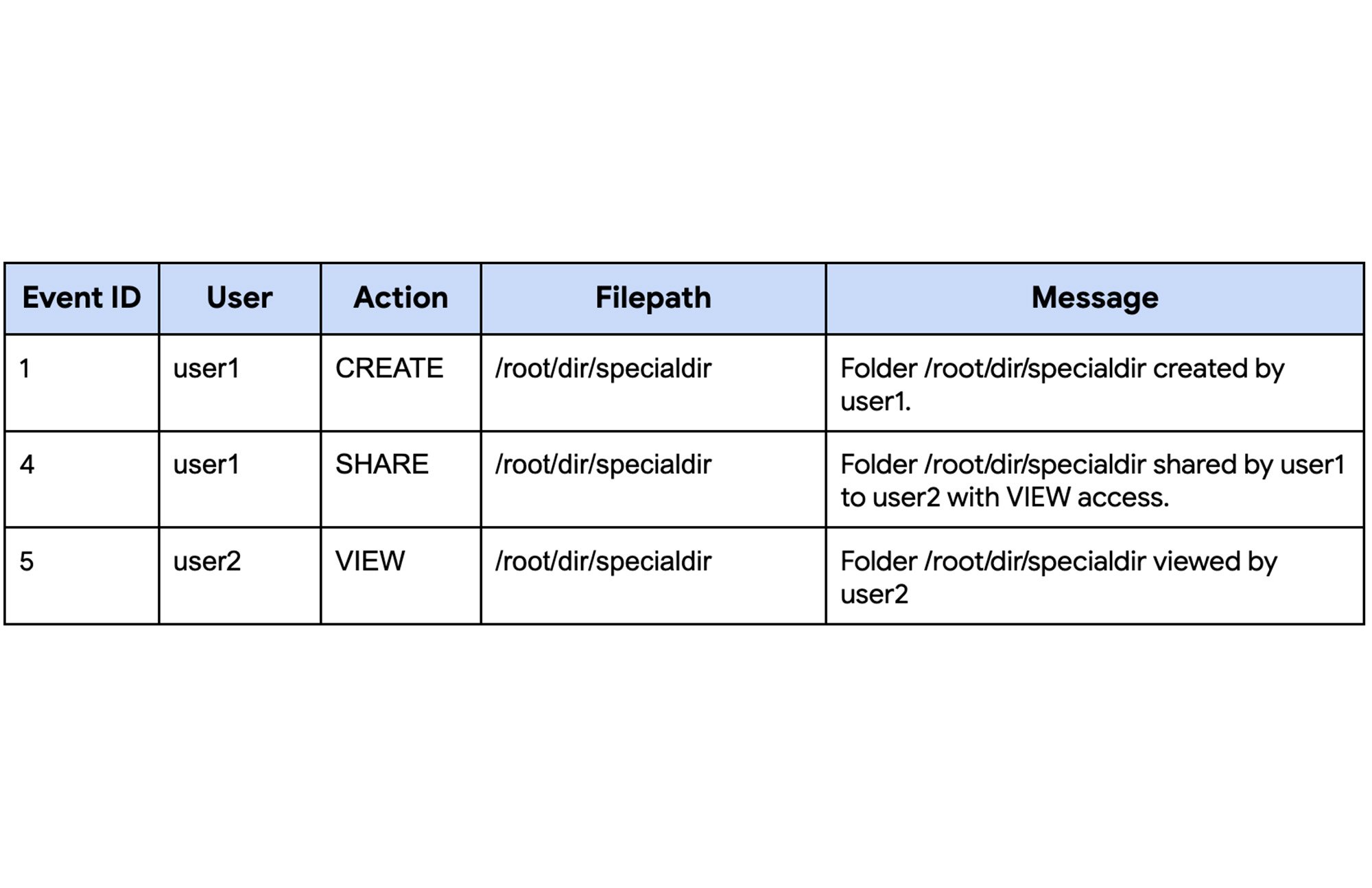
With this launch, Query 3 now can utilize the search index for lower latency, scanned bytes, and slot usage.
Prefix search
At the moment, the SEARCH function does not support prefix search. With the newly added support for using indexes with the STARTS_WITH and (a limited form of) LIKE, you can run the following queries with index optimizations:
Borth Query 4 and Query 5 return one row with Event ID 2. The SEARCH function would not have been an ideal option in this case because every row contains both tokens "dir" and "specialdir", and thus it would have returned all rows in the table.
Querying Genomic Data
In this section we share an example of retrieving information from a public dataset. BigQuery hosts a large number of public datasets, including bigquery-public-data.human_genome_variants -- the 1000 Genomes dataset comprising the genomic data of roughly 2,500 individuals from 25 populations around the world. Specifically, the table 1000_genomes_phase_3_optimized_schema_variants_20150220 in the dataset contains the information of human genome variants published in phase 3 publications (https://cloud.google.com/life-sciences/docs/resources/public-datasets/1000-genomes). The table has 84,801,880 rows, with the logical size of 1.94 TB.
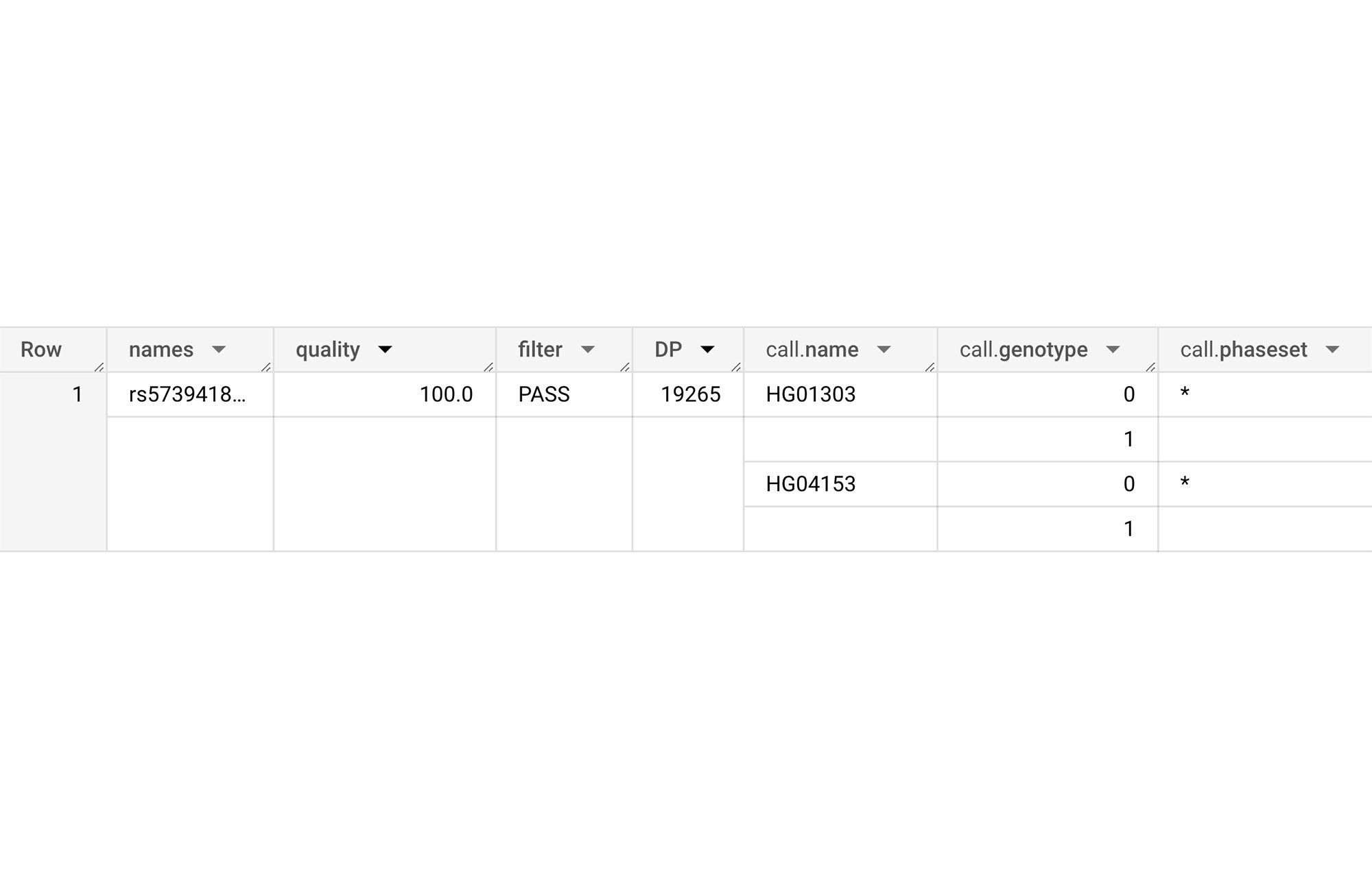
Suppose that a scientist aims to find information about a specific genomic variant such as rs573941896 in this cohort. The information includes the quality, the filter (PASS/FAIL), the DP (sequencing depth), and the call details (which individuals in the sample have this variant). They can issue a query as follows:
The query returns 1 row:
Without a search index on the table, the above query takes 5 secs and scans 294.7 GB, consuming 1 hr 1 min slot time:
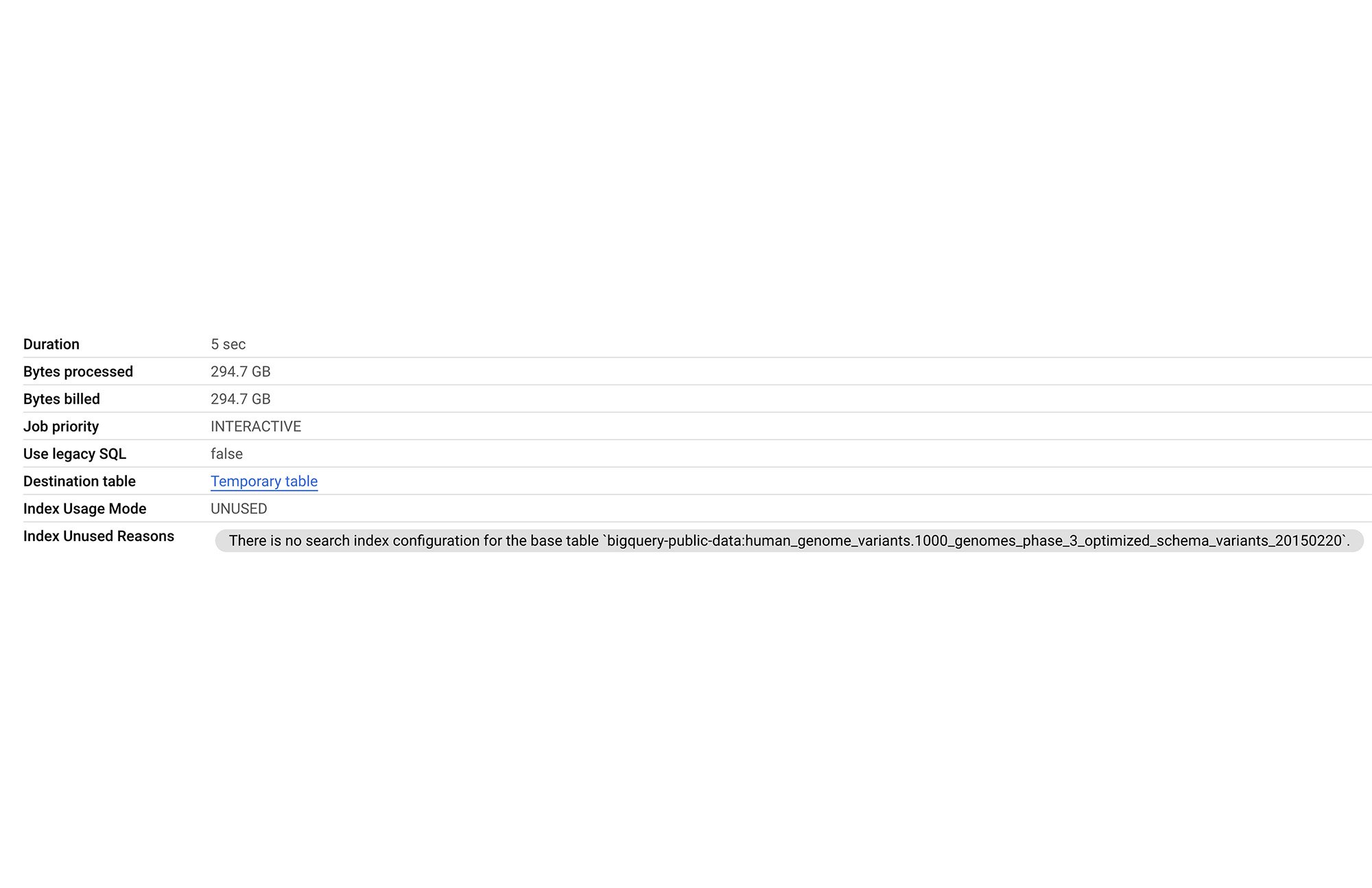
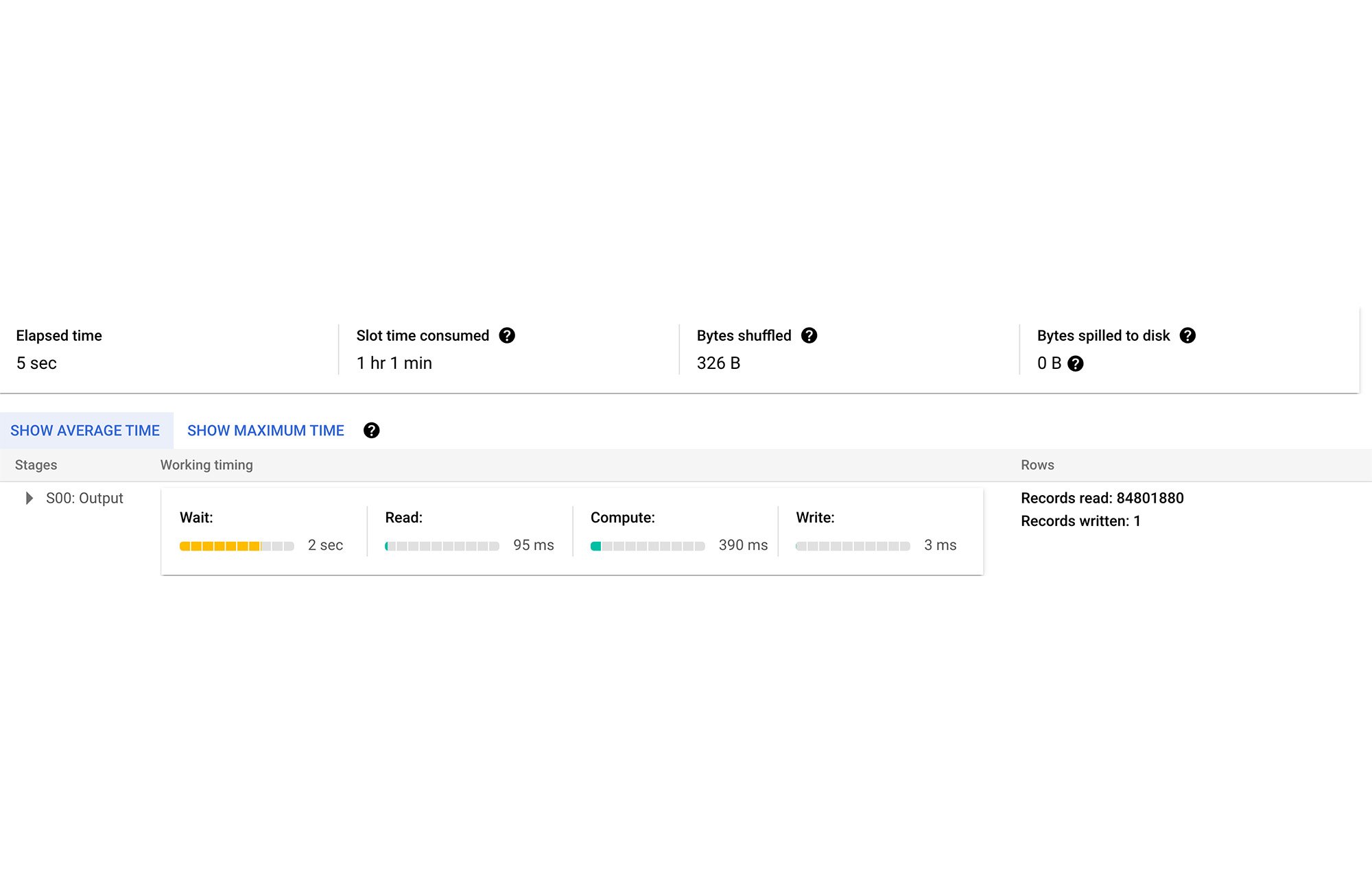
In the next section, we demonstrate the journey for benefitting from search indexes for this use case.
Create Search Index for Faster String Data Search
Creating a BigQuery’s search index can accelerate the desired retrieval in this case. We made a copy of the public table to one of our datasets before creating the index. The copied table is now my_project.my_dataset.genome_variants.
We use the following DDL to create the search index on the names column in the table:
The CREATE SEARCH INDEX command returns immediately, and the index will be asynchronously created in the background. The index creation progress can be tracked by querying the INFORMATION_SCHEMA.SEARCH_INDEXES view:
The INFORMATION_SCHEMA.SEARCH_INDEXES view shows various metadata about the search index, including its last refresh time and coverage percentage. Note that the SEARCH function always returns correct results from all ingested data, even if some of the data isn't indexed yet.
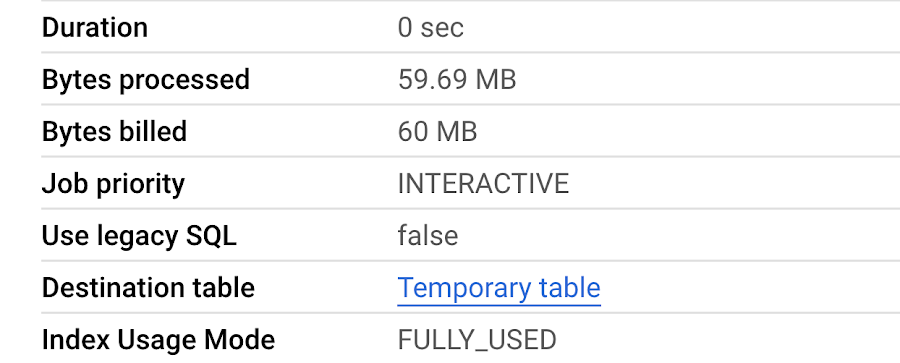
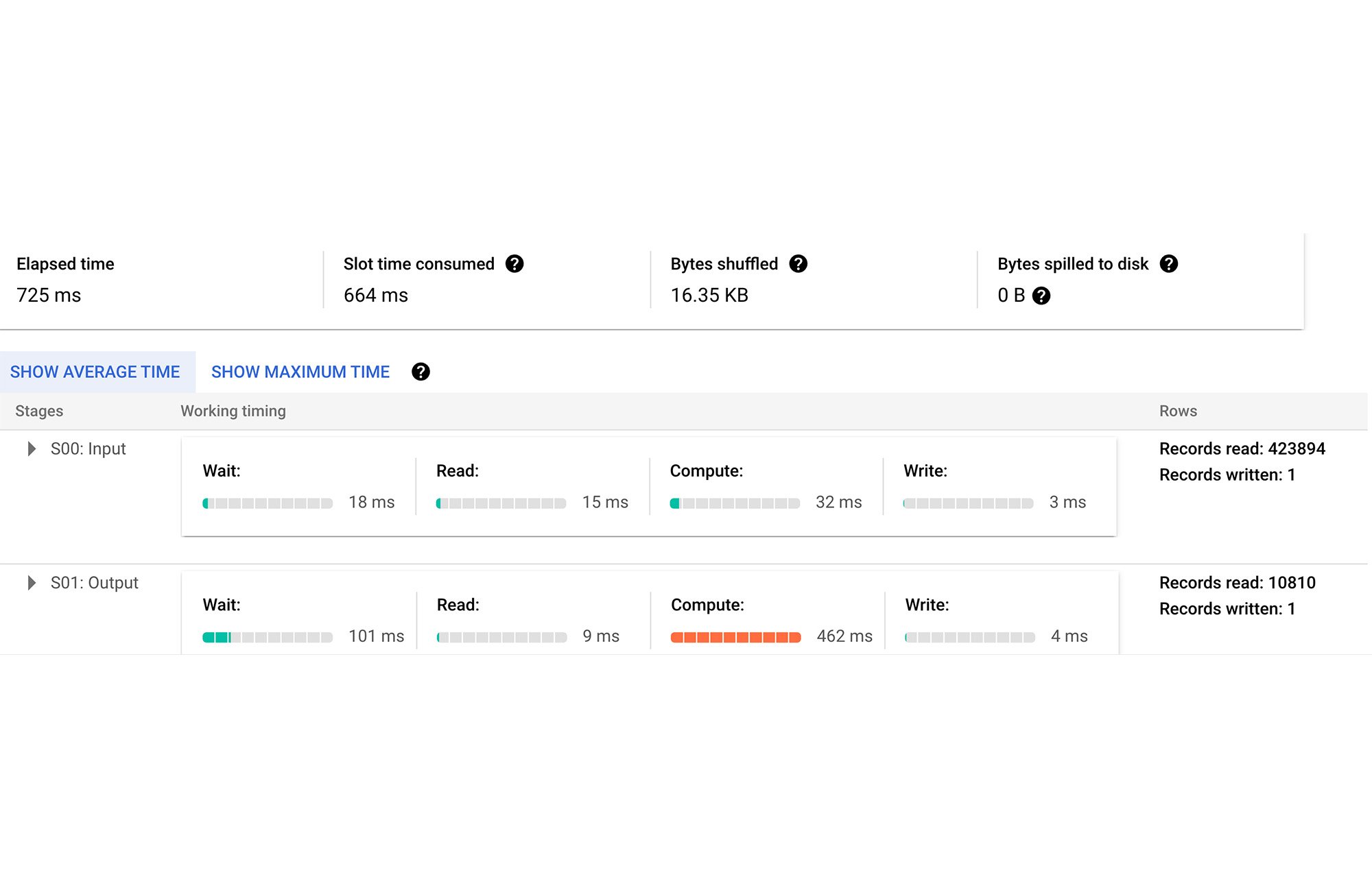
Once the indexing is complete, we perform the same query as above:
We can see significant gains in 3 fronts:
Query latency: 725 ms (vs. 5 seconds without the search index)
Bytes processed: 60 MB (vs. 294.7 GB without the search index)
Slot time: 664 ms (vs. 1 hour 1 min without the search index).
Performance Gains When Using Search Indexes On Queries with String EQUAL
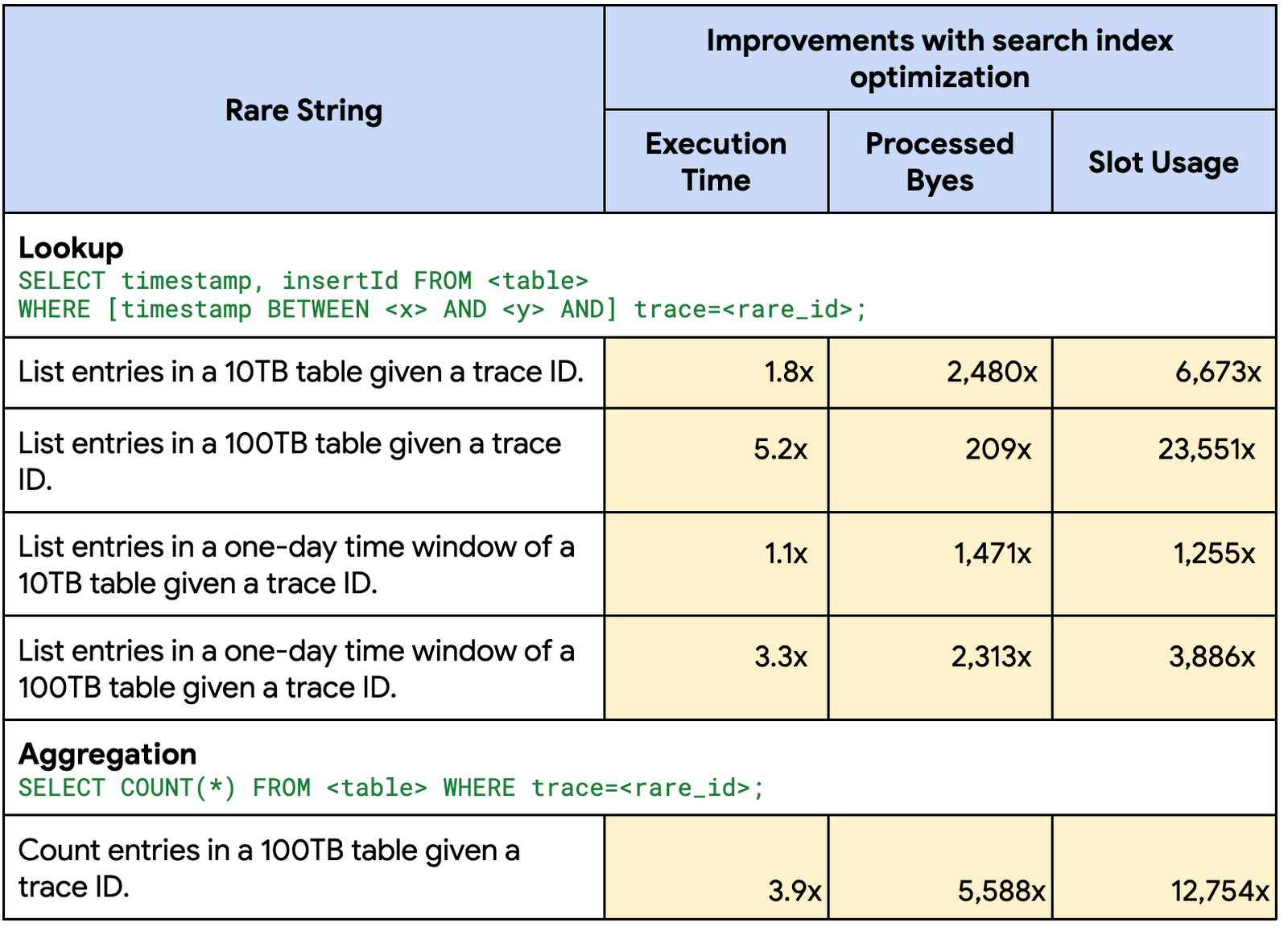
To benchmark the gains on larger and more realistic data, we ran a number of queries on Google Cloud Logging data for Google internal test project (at 10TB, 100TB scales). We compare the performance between having and not having the index optimizations.
Rare string search
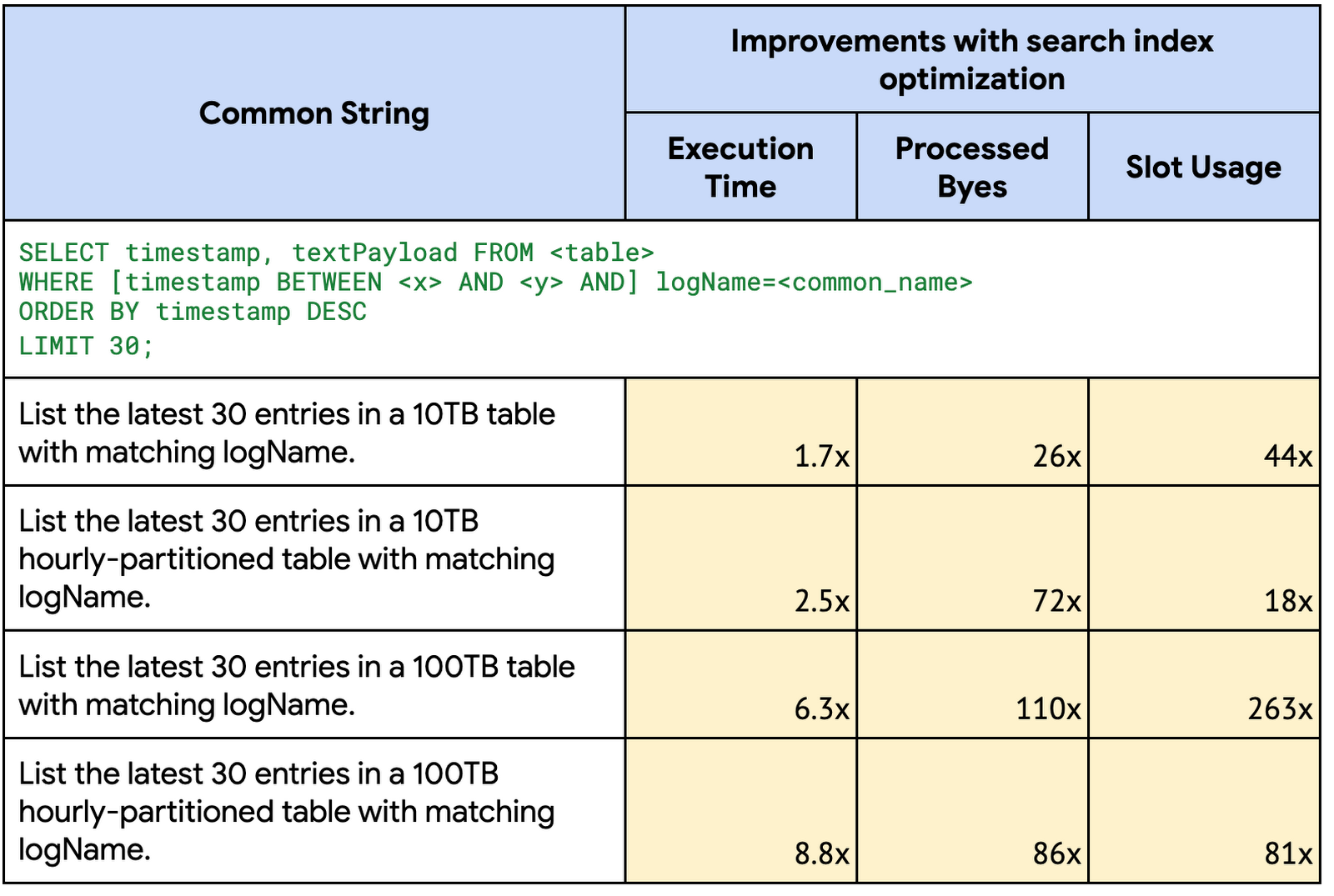
Common string search on most recent data (order-by+limit)
In our October 2022 launch, we unveiled an optimization for queries that use the SEARCH function on large partitioned tables with an ORDER BY on the partitioned column and a LIMIT clause. With this launch, the optimization is expanded to also cover queries with literal string comparisons using EQUAL, IN, STARTS_WITH and LIKE.
IP address search

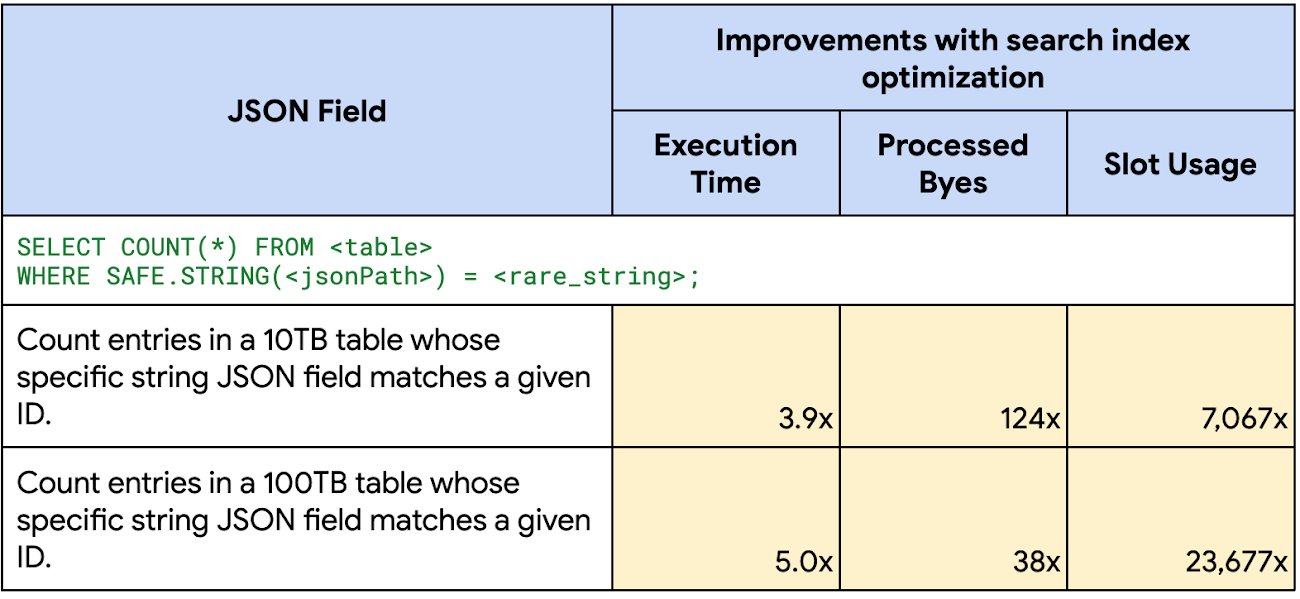
JSON field search
Using search index optimizations with equal (=), IN, LIKE, and STARTS_WITH is currently in preview. Please submit this allowlisting form if you would like to enable and use it for your project. More optimizations are still on the way. Stay tuned.



