BigQuery and surrogate keys: a practical approach
Marco Tranquilin
Cloud Consultant, Professional Services, Google Cloud
When working with tables in data warehouse environments, it is fairly common to come across a situation in which you need to generate surrogate keys. A surrogate key is a system-generated identifier that uniquely identifies a record within a table.
Why do we need to use surrogate keys? Quite simply: contrary to natural keys, they persist over time (i.e. they are not tied to any business meaning) and they allow for unlimited values. Think about a table that is collecting IoT data from multiple devices in different regions: since you want to store unlimited data and you could have possible overlaps on device identifiers, surrogate keys will help a lot to uniquely identify a record. Another use case could be an “items” table in which you want to store information not only related to articles but also history of changes made on data: even in this case surrogate keys could be an elegant solution to easily assign unique identifiers to all records.
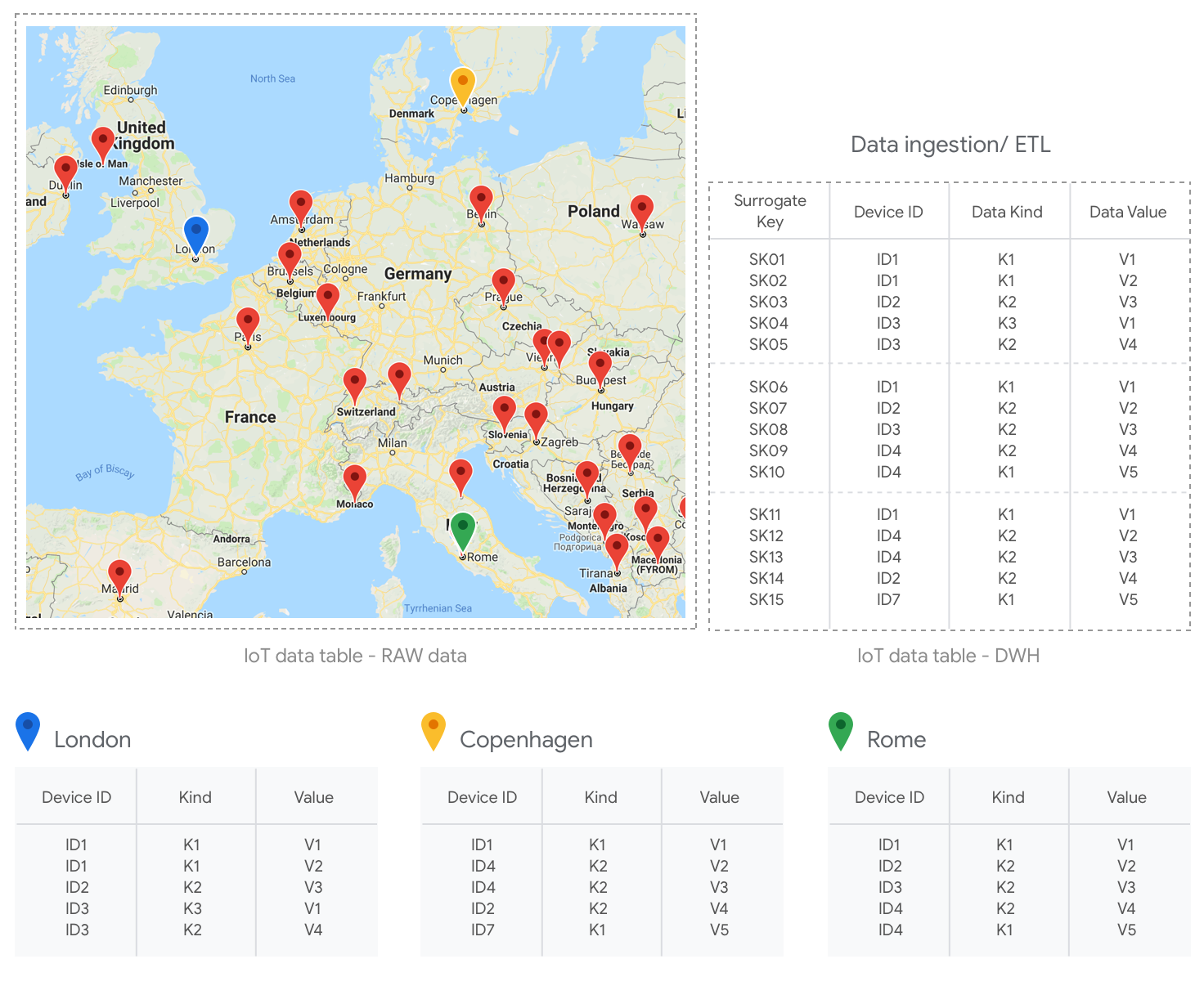
How to generate surrogate keys
A common way to generate surrogate keys is to assign an incremental number to each row of a table: you can accomplish this goal using the standard SQL function ROW_NUMBER() OVER({window_name | (window_specification)})
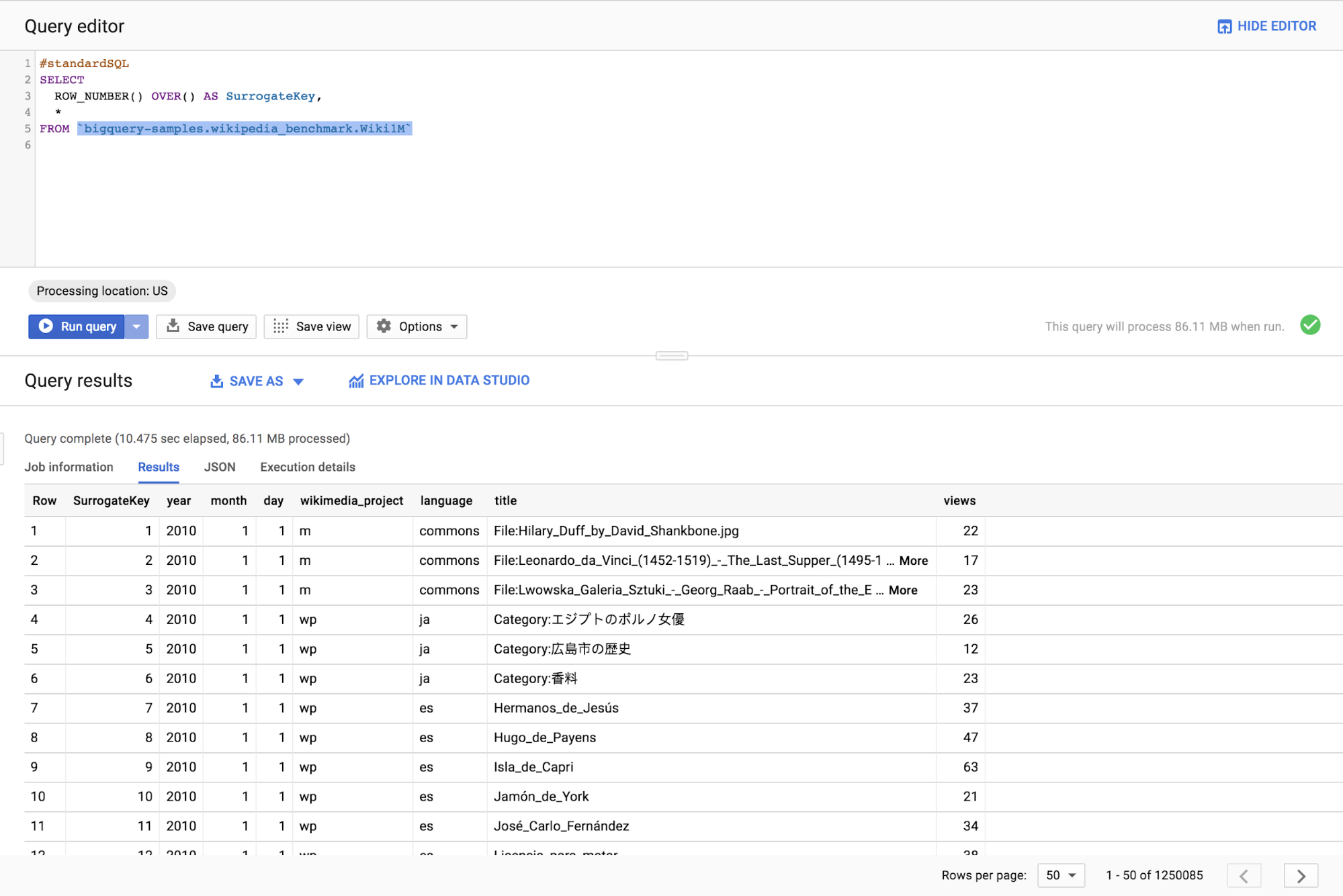
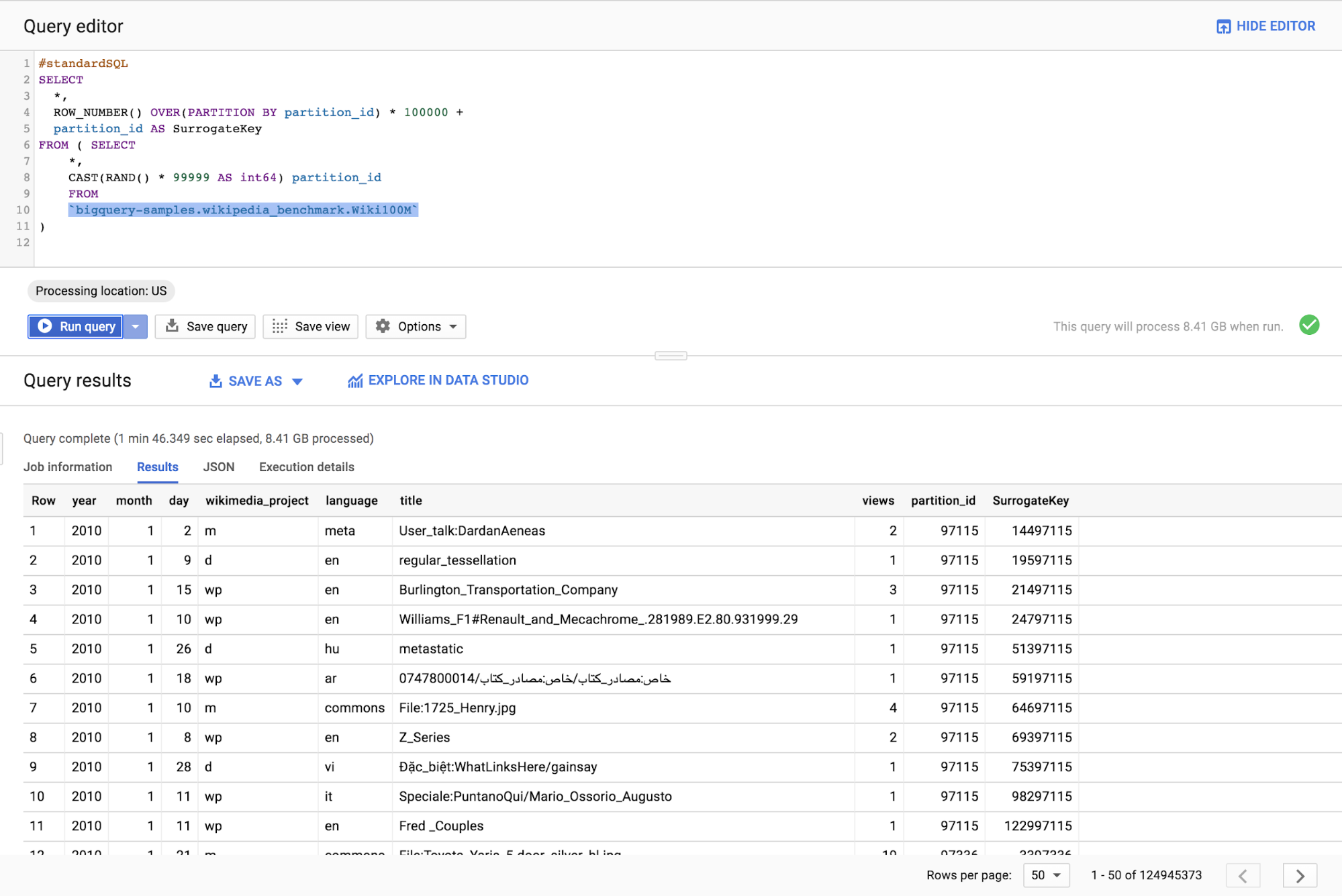
Unfortunately, this approach is limited. To implement ROW_NUMBER(), BigQuery needs to sort values at the root node of the execution tree, which is limited by the amount of memory in one execution node.
The general solution is to partition the data using PARTITION predicate combined with the partition fields to get a unique id per row.
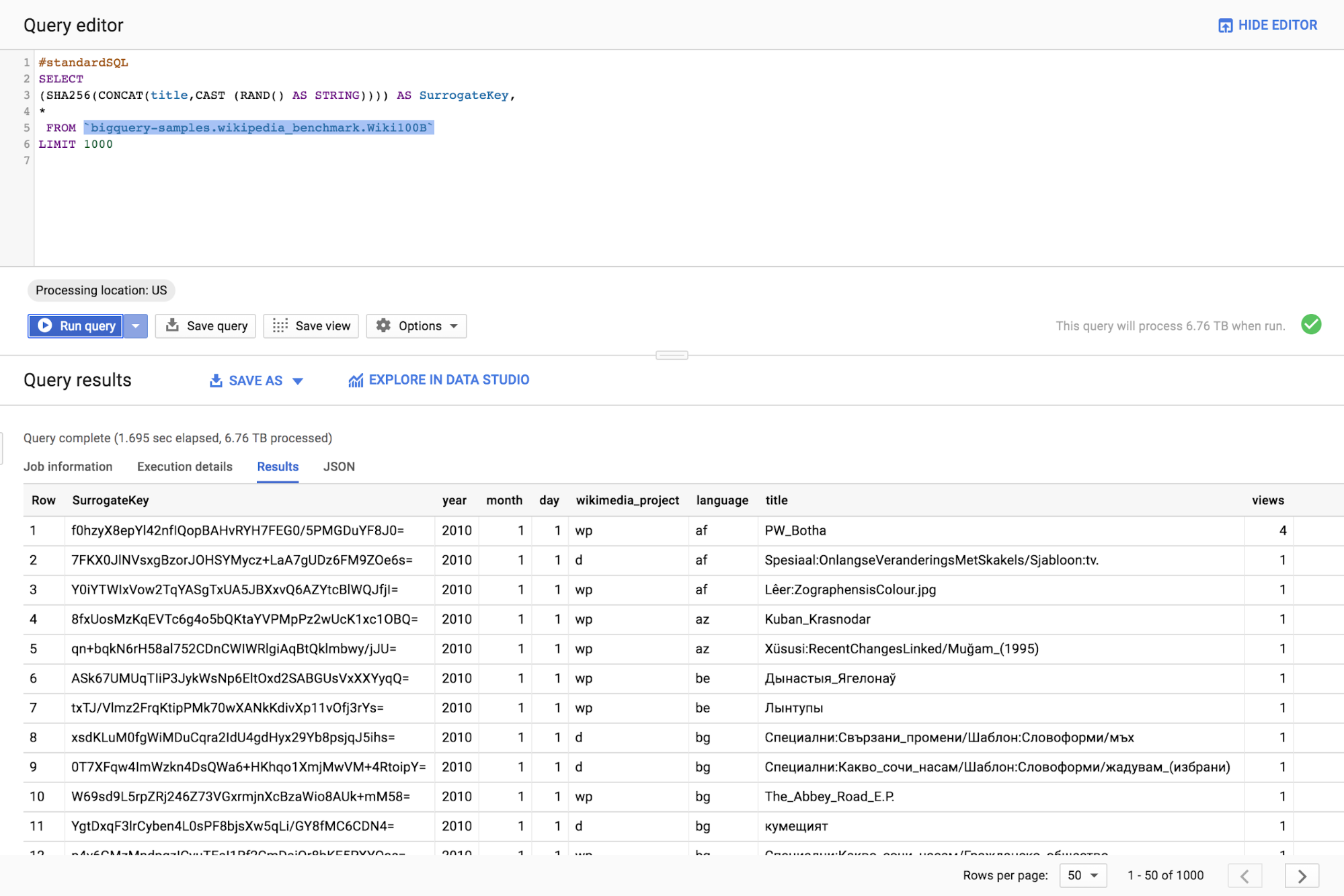
An alternative approach
Another solution that you might adopt—especially in streaming scenarios—depends on hashing functions. Since this pattern computes the surrogate key values at run time, it can be applied to data sets of any dimension. The idea is to compute the SHA256 digest of selected record fields and use the result as surrogate key.
Two possible approaches are possible:
INSERT INTOstatement when new records have to be inserted in the table (play with inner query to select target data to be inserted into target table)INSERT INTO `MyPrj.MyDataset.Wiki100B_With_SK`(SurrogateKey,year,month,day,wikimedia_project,language,title,views)SELECT (SHA256(title)) AS SurrogateKey,*FROM `bigquery-samples.wikipedia_benchmark.Wiki100B`
UPDATEstatement when existing records have to be updated (play with filters to select correct data to be updated)UPDATE `MyPrj.MyDataset.Wiki100B_With_SK`SET SurrogateKey = (SHA256(title))WHERE year = 2010
When you plan your activities, please note that you are limited to 1000 INSERT operation per table per day and 200 UPDATE operation per table per day.
In case of duplicate records in the source table, a random value can be concatenated before computing the digest: this will reduce the probability of encountering collisions.
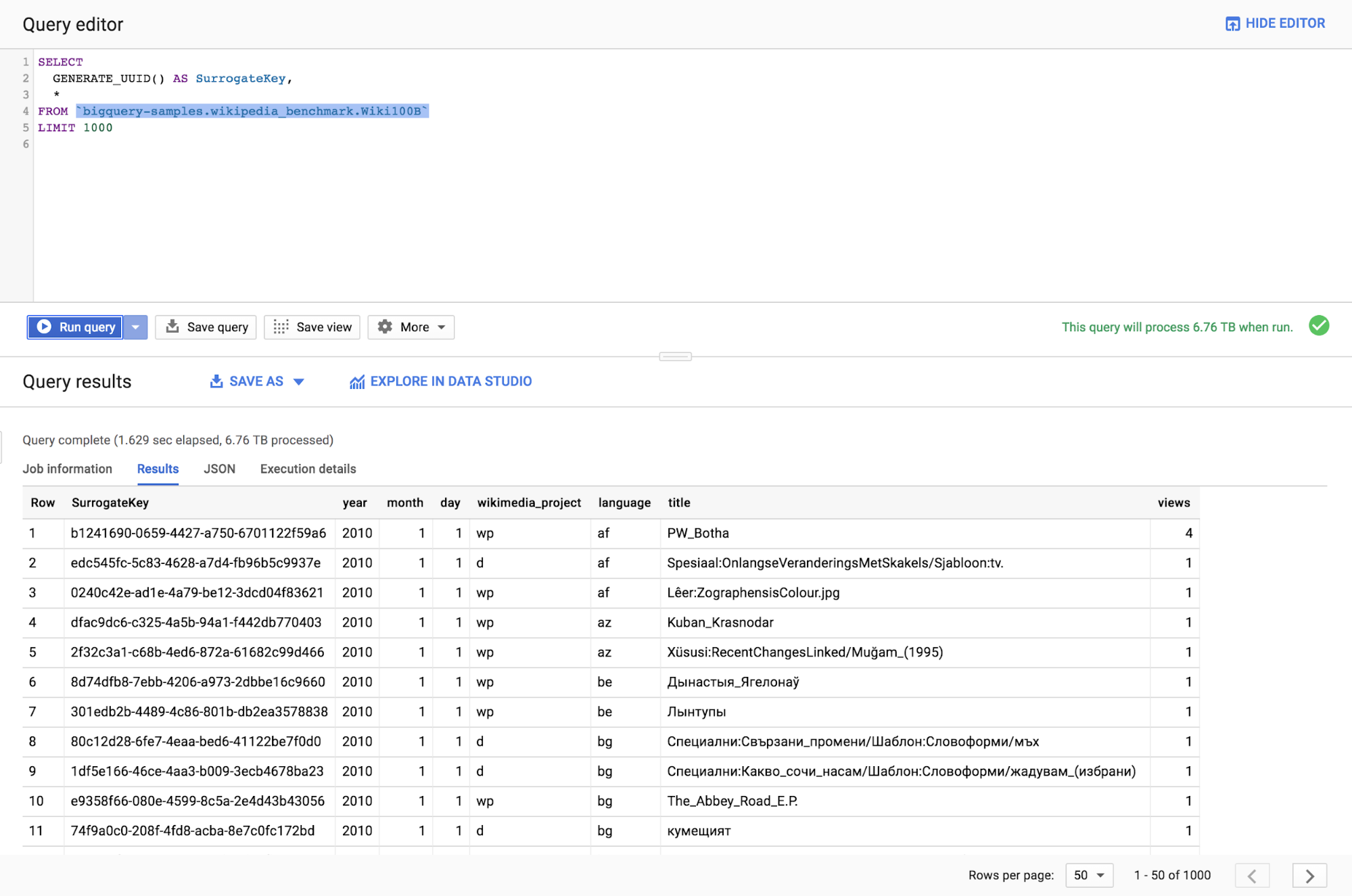
Another way to achieve the same result is to use a new function called GENERATE_UUID() that generates a unique identifier for each row of the query result at run-time. The generated key will be a lowercase String consisting of 32 hexadecimal digits in five groups separated by hyphens in the form 8-4-4-4-12.
Conclusion
Surrogate keys are common in data warehouse environments because they are:
Context-free
More future-compatible
Potentially infinitely scalable
BigQuery provides end users with the ability to easily deal with surrogate keys, enabling their generation and update at scale.
We hope you enjoyed learning some possible patterns to tackle surrogate key management; the engineering team is continuously improving the service by adding new capabilities or extending the ones already available. If you’d like to stay up to date with future additions, consider bookmarking the release notes page.

