Achieve higher performance and lower query cost for BigQuery integer or timestamp lookups
Jing Mao
Software Engineer
Huong Phan
Engineering Lead, BigQuery Search
The first incarnation of search indexes in BigQuery focused on fast and efficient lookups on STRING data elements, either in standalone STRING scalar columns, or within an ARRAY, STRUCT, or JSON column. Our previous blog posts showcased the orders-of-magnitude performance gains achievable when utilizing indexes with the SEARCH function and other functions and operators.
Today, we are announcing the public preview of numeric search indexes, which enables optimized lookups on INT64 and TIMESTAMP data types. With this change, the EQUAL(=) and IN operations on these data types can utilize search indexes to reduce byte scans for improved performance. So now your lookups for account IDs or transactions IDs or log timestamps can get faster and cheaper.
In this blog, we demonstrate the gains on real data, showcasing index creation and queries on a 100TB log table called log_table that contains Google Cloud Logging data for an internal Google test project.
The base table details are as follows:
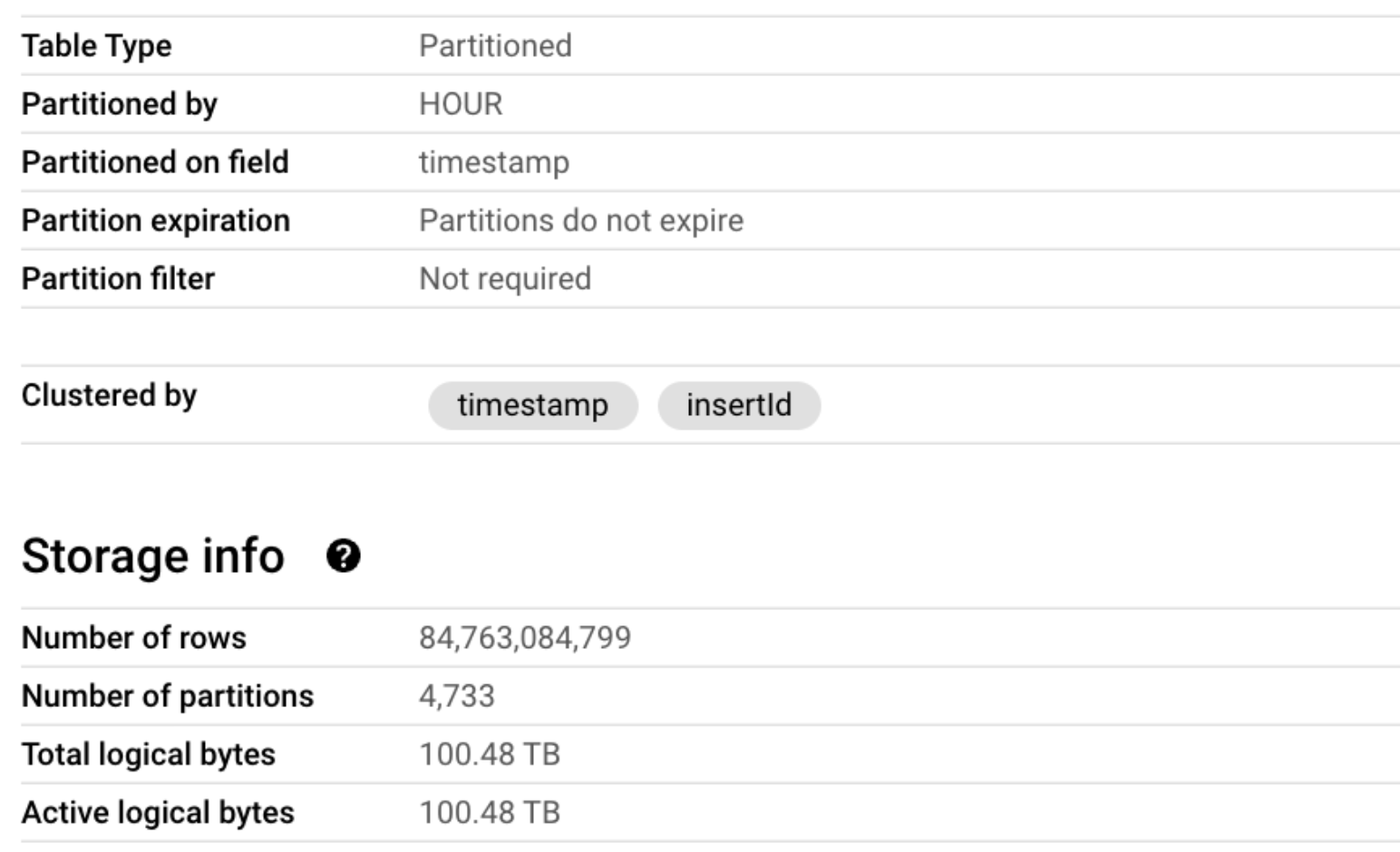
The table has the following columns of interest:
-
jsonPayload: type JSON -
This jsonPayload has a leaf field named
threadIdof type JSON number. -
sourceLocation: type RECORD (or STRUCT) with two sub-fields of interest: -
file: type STRING, containing the name of the file producing the log entry -
line: type INT64, containing the line number in the file where the log entry was produced.
Using search indexes
By default, a search index is created for the STRING data only. If you want to index INT64 or TIMESTAMP, you need to provide them in the index option called data_types. In the following example, all data of type STRING and INT64 in the log_table table will be indexed.
JSON field search
In this first example, we want to search for log entries that have the thread ID 12104 in the JSON payload.
We compare between having a search index and having no index. Given that log entries with this thread ID are very rare, the results show dramatic improvements on all three metrics:
STRUCT nested field search
In the second example, we count how many log entries are produced from a certain line of code (line 813 in the file borg/borgletlib/borgletlib.cc).
Note that sourceLocation.file is a STRING field. A search index on only STRING data type can already help improve the query performance as shown below. However, with indexing on also the INT64 data type, the performance can be further improved.
Do I need indexing if I use partitioning/clustering?
While partitioning and clustering can optimize filtering and lookups, they have certain limitations. For instance, partitioning can only be done on a single column, and clustering allows up to four columns per table. However, clustering is most effective when filtering on the first clustering column, as subsequent columns often provide minimal pruning power. Furthermore, both partitioning and clustering are limited to top-level columns.
Search indexes on INT64/TIMESTAMP complement these BigQuery features by enabling lookup optimizations on any number of columns. In addition, as demonstrated above, they cover struct nested fields, array elements, and JSON leaf fields.
This feature is currently in preview. For more information, refer to Optimize with numeric predicates.

