Analyze BigQuery data with Kaggle Kernels notebooks

Jessica Li
Product Manager, Kaggle
Jordan Tigani
Director, BigQuery, Google Cloud
We’re happy to announce that Kaggle is now integrated into BigQuery, Google Cloud’s enterprise cloud data warehouse. This integration means that BigQuery users can execute super-fast SQL queries, train machine learning models in SQL, and analyze them using Kernels, Kaggle’s free hosted Jupyter notebooks environment.
Using BigQuery and Kaggle Kernels together, you can use an intuitive development environment to query BigQuery data and do machine learning without having to move or download the data. Once your Google Cloud account is linked to a Kernels notebook or script, you can compose queries directly in the notebook using the BigQuery API Client library, run it against BigQuery, and do almost any kind of analysis from there with the data. For example, you can import the latest data science libraries like Matplotlib, scikit-learn, and XGBoost to visualize results or train state-of-the-art machine learning models. Even better, take advantage of Kernel’s generous free compute that includes GPUs, up to 16GB of RAM and nine hours of execution time. Check out Kaggle’s documentation to learn more about the functionality Kernels offers.
With more than 3 million users, Kaggle is where the world’s largest online community of data scientists come together to explore, analyze, and share their data science work. You can quickly start coding by spinning up a Python or R Kernels notebook, or find inspiration by viewing more than 200,000 public Kernels written by others.
For BigQuery users, the most distinctive benefit is that there is now a widely used Integrated Development Environment (IDE)—Kaggle Kernels—that can hold your querying and data analysis all in one place. This turns a data analyst’s fragmented workflow into a more seamless process instead of the previous way, where you would first query data in the query editor, then export the data elsewhere to complete analysis.
In addition, Kaggle is a sharing platform that lets you easily make your Kernels public. Kaggle lets you disseminate your open-source work and also discuss data science with the world’s top-notch data scientist professionals.
Getting started with Kaggle and BigQuery
To get started with BigQuery for the first time, enable your account under the BigQuery sandbox, which provides up to 10GB of free storage, 1 terabyte per month of query processing, and 10GB of BigQuery ML model creation queries. (Find more details on tier pricing in BigQuery’s documentation).
To start analyzing your BigQuery datasets in Kernels, sign up for a Kaggle account. Once you’re signed in, click on “Kernels” in the top bar, followed by “New kernel” to immediately spin up your new IDE session. Kaggle offers Kernels in two types: scripts and notebooks. For this example, the notebooks option is selected.
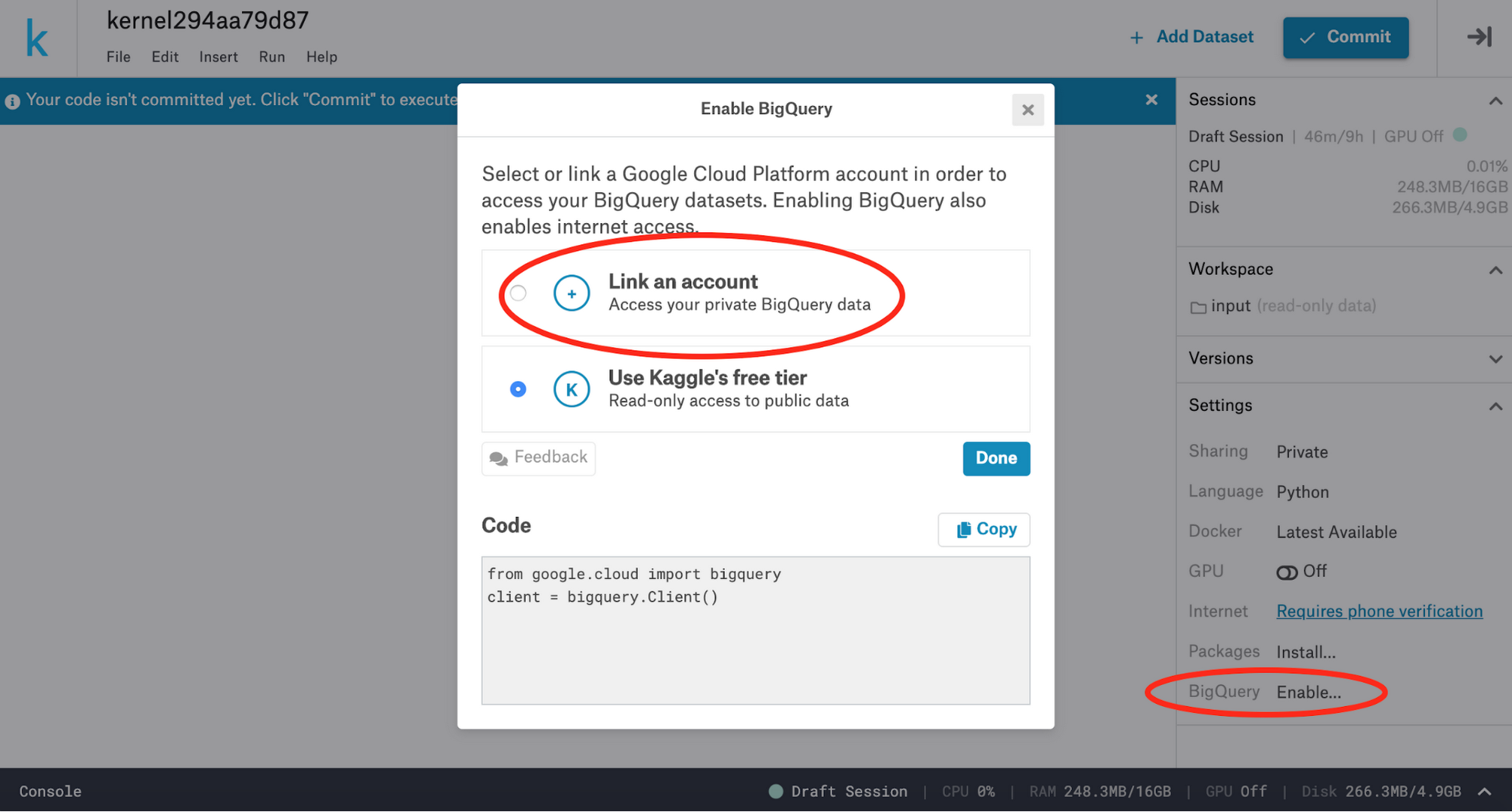
In the Kernels editor environment, link your BigQuery account to your Kaggle account by clicking “BigQuery” on the right-hand sidebar, then click “Link an account.” Once your account is linked, you can access your own BigQuery datasets using the BigQuery API Client library.
Let’s try this out using the Ames Housing dataset that’s publicly available on Kaggle. This dataset contains 79 explanatory variables describing (almost) every aspect of residential homes in Ames, Iowa, as well as their final sales price. Let’s compose a query to gain some insights from the data. We want to find out what different home types there are in this dataset, as well as how many do or do not have central air conditioning installed. Here’s how the query looks:
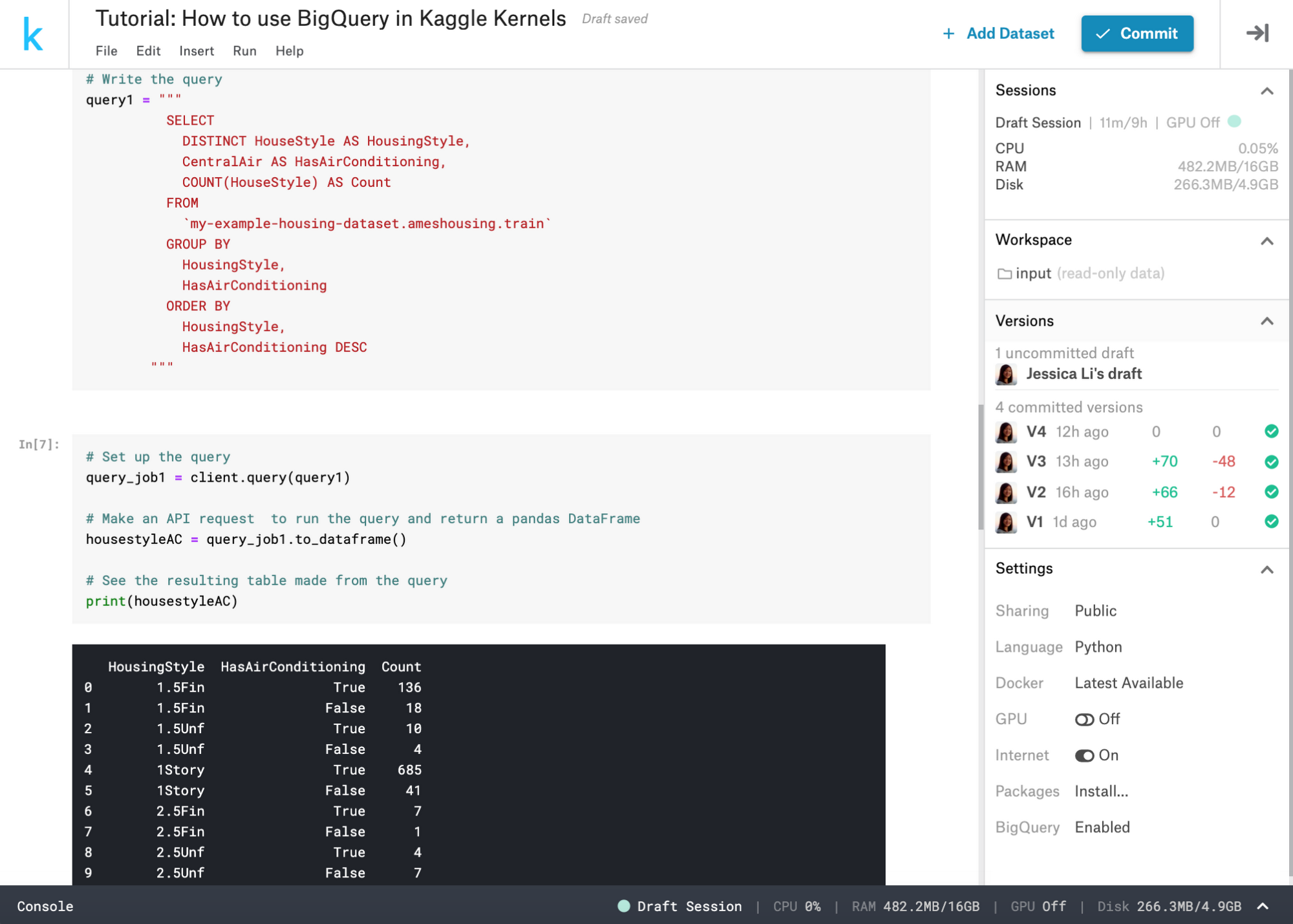
We quickly get a response showing that one-story homes are the most common home style in Ames and that, regardless of home style, most homes have central air conditioning. There are many more public datasets on Kaggle that you can explore in this way.
Building ML models using SQL queries
Aside from data analysis, BigQuery ML lets you create and evaluate machine learning models using SQL queries. With a few queries, any data scientist can build and evaluate regression models without extensive knowledge of machine learning frameworks or programming languages. Let’s create a linear model that aims to predict the final sales price of real estate in Ames. This model will train on a couple inputs—living area size, year built, overall condition, and overall quality. Here’s the model code:
In just one query, we’ve created a SQL-based ML model inside Kernels. You could continue using Kernels to create more advanced queries for analysis and optimize your model for better results. You may even choose to publish your Kernel to share publicly with the Kaggle community and broader Internet after your analysis is complete. To see the rest of the workflow on obtaining training statistics and evaluating the model, visit the complete How to use BigQuery on Kaggle tutorial. This tutorial is publicly available as a Kernels notebook. You can also check out the Getting started with BigQuery ML Kernel that goes into greater depth on training and evaluating models.
Learn more details on navigating the integration by visiting Kaggle’s documentation. Also, sign up for Kaggle’s new and updated SQL micro-course that teaches you all the basics of the SQL language using BigQuery. We hope you enjoy using this integration!


