Priority-based scheduling between node pools
Sarun Singla
Technical Account Manager, Google Cloud
Google Kubernetes Engine (GKE) is a leading managed Kubernetes service in the market. GKE is used by several organizations today that are using Google Cloud. As costs rise, customers are shifting their focus to cloud cost optimization. They are seeking more efficient and cost-effective ways to run their workloads by utilizing the best-in-class optimization techniques across products and services.
From the many ways to do cost optimization on GKE, running workloads on low cost compute Spot VMs is a cost-effective way to do so. Spot VMs are idle server machines that get offered at a significant discount. Node pools can be used to deploy workloads across multiple machine types and help reduce costs.
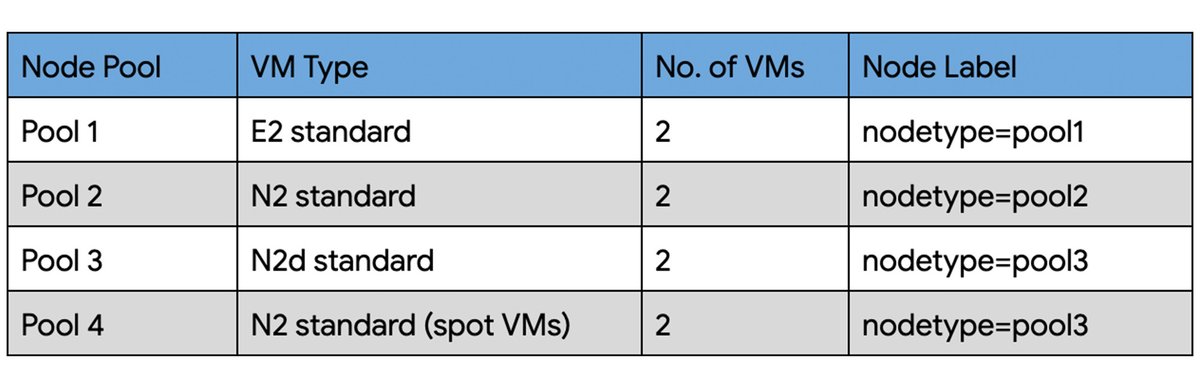
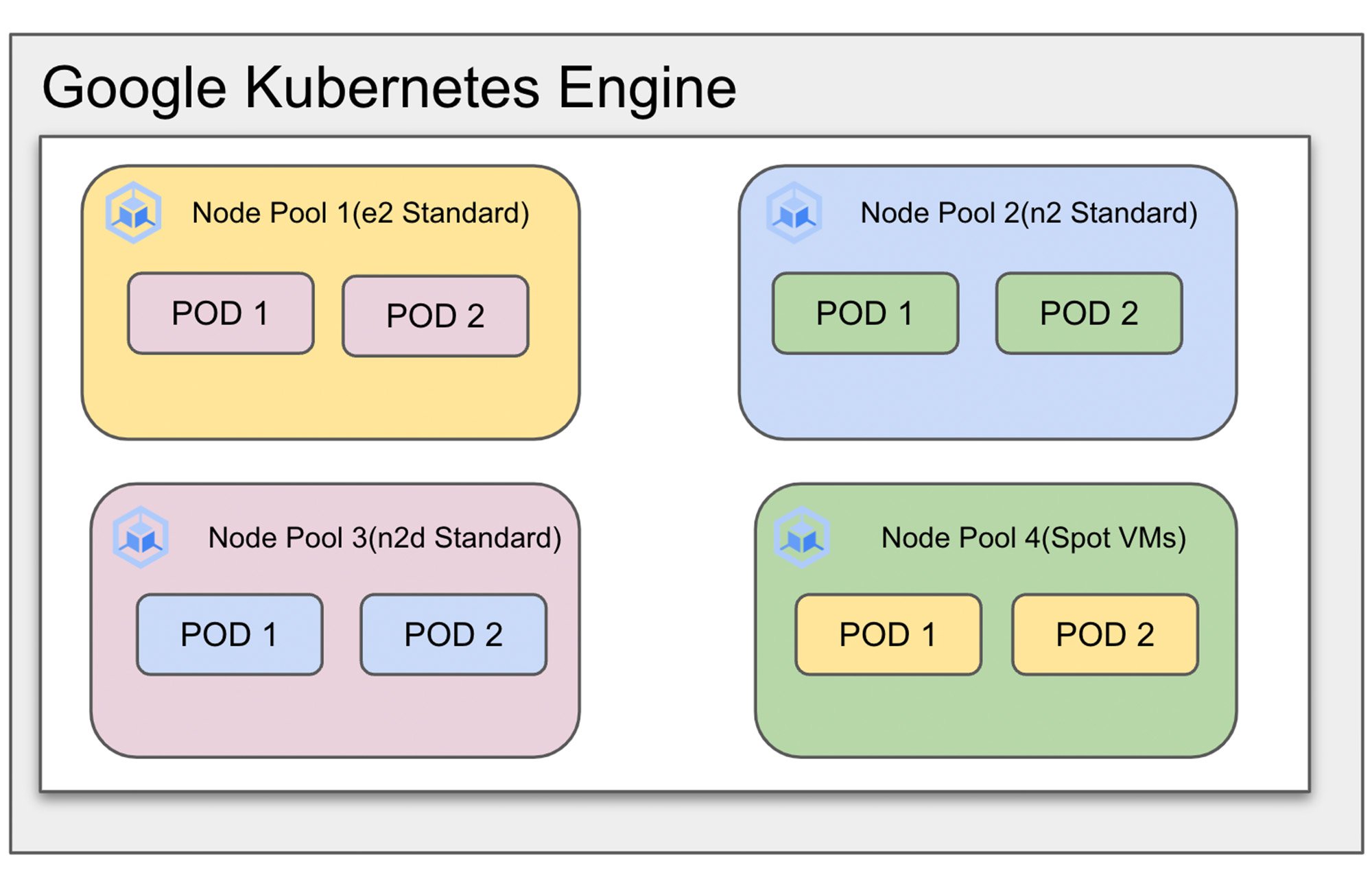
In this blog we’ll discuss how to use four different node pools: E2 standard, N2 standard, N2d standard and N2 standard (spot VMs) to deploy workloads and help reduce costs for running a production workload.
Adding node pools
Create a standard GKE cluster with these node pools. You can also replace these node pools with GPU and other required machine shapes.
Define priority class
Pods can be assigned priority class, which indicates how important they are relative to other pods. If a pod cannot be scheduled, the scheduler will try to preempt (evict) lower priority pods to make room for it.
Priority class definition when used, will help evict lower priority pods on required node pools.
In our example we have two classes defined low-priority with value 10000 and high-priority with 1000000.
priorityclass.yaml
Node affinity and priority class for deployments
Pods can be constrained from being scheduled on nodes based on node labels using node affinity. There are two types of node affinity:
- requiredDuringSchedulingIgnoredDuringExecution: Unless the rule is met the scheduler can’t schedule the Pod.
- preferredDuringSchedulingIgnoredDuringExecution: Scheduler tries to find a node that meets this rule. If a matching node is not available, the scheduler still schedules the Pod.
Create two separate deployments. Here deployment-1 and deployment-2 are running on separate sets of node pools.
Deployment files required for setup
deployment-app1.yaml
The above deployment will deploy pods on node pools 1, 2 and 4 with a weight of 80 for spot-VMs. Note deployment 1 will get deployed with a low-priority class.
After deployment of deployment-app1.yaml
Output 1
deployment-app2.yaml
Deployment-2 will deploy pods on node pools 1, 3, and 4 with a weight of 80 for spot-VMs. It will evict pods running on pools 1 and 4 as it's deployed with a higher priority class.
After deployment of deployment-app2.yaml
Output 2
After running the second deployment, compare the two outputs above. Observe that the pods running for the first deployment get evicted. This shows how to use features like node affinity and node pools to run complex production workloads and optimize cost with spot-VMs.
You can create node pools with the GPU machine types to run your ML workloads. The example shown here should work just fine with GPU machines. Priority based scheduling will also support active ML workloads on GKE which need higher-priority GPU machines when required.
Conclusion
GKE can help you run optimized AI workloads with platform orchestration.
Learn more about the recently launched GKE Editions which can help organizations with configuration and policy management, fleet wide networking features, Identity management, observability and help support microservice-based architecture.
