Using GKE workload rightsizing to find — and fix — resource utilization
Ameenah Burhan
Solutions Architect
Xiang Shen
Solutions Architect
Kubernetes has become the leading platform for efficiently managing and scaling containerized applications, particularly as more businesses transition to the cloud. While migrating to Kubernetes, organizations often face common challenges such as incorrect workload sizing. This can result in decreased reliability and performance of workloads, and idle clusters that waste resources and drive up costs.
GKE has built-in tools for workload rightsizing for clusters within a project. In this blog, we'll explore how to use GKE's built-in tools to optimize cost, performance, and reliability at scale across projects and clusters. We'll focus on workload rightsizing and identifying idle clusters.
Workload rightsizing recommendations at scale
The Vertical Pod Autoscaler (VPA) recommendations intelligence dashboard uses intelligent recommendations available in Cloud Monitoring combined with GKE cost optimization best practices to help your organization answer these questions:
Is it worth it to invest in workload rightsizing?
How much effort does it take to rightsize your workloads?
Where should you focus initially?
How many workloads are over-provisioned and how many are under-provisioned?
How many workloads are under reliability or performance risk due to incorrectly requested resources?
Are you getting better over time at workload rightsizing?
The dashboard presents an overview of all clusters across all projects in one place. Before adjusting resource requests, ensure you have a solid grasp on the actual needs of your workloads for optimal resource utilization.
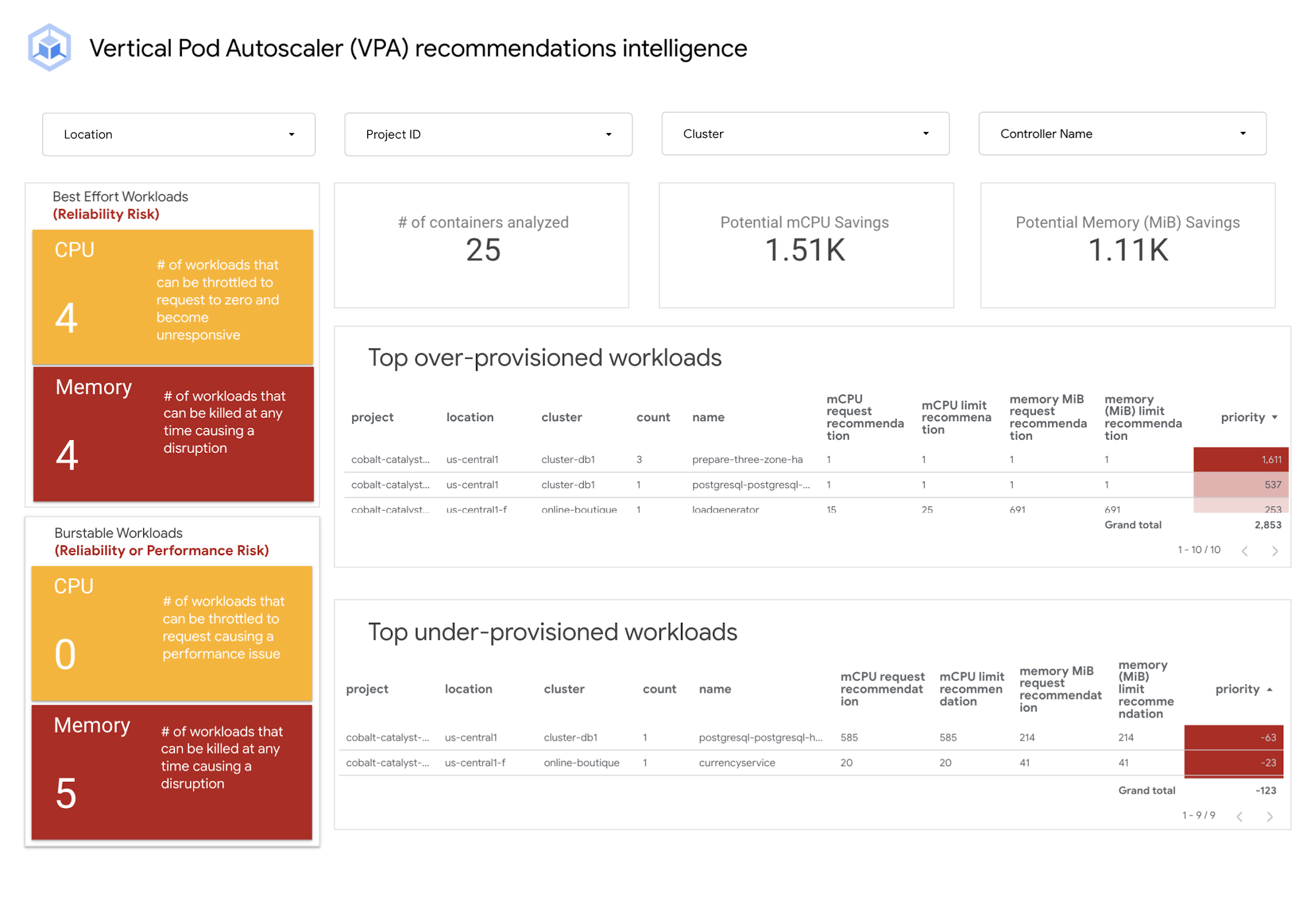
The following section walks you through the dashboard and discusses how to use the data on your optimization journey.
Best-effort workloads (reliability risk)
Workloads with no resource requests or limits configured are at a high risk of failing due to being out-of-memory or the CPU throttling to zero.
How to improve?
1. Navigate to the VPA container recommendations detail view dashboard.
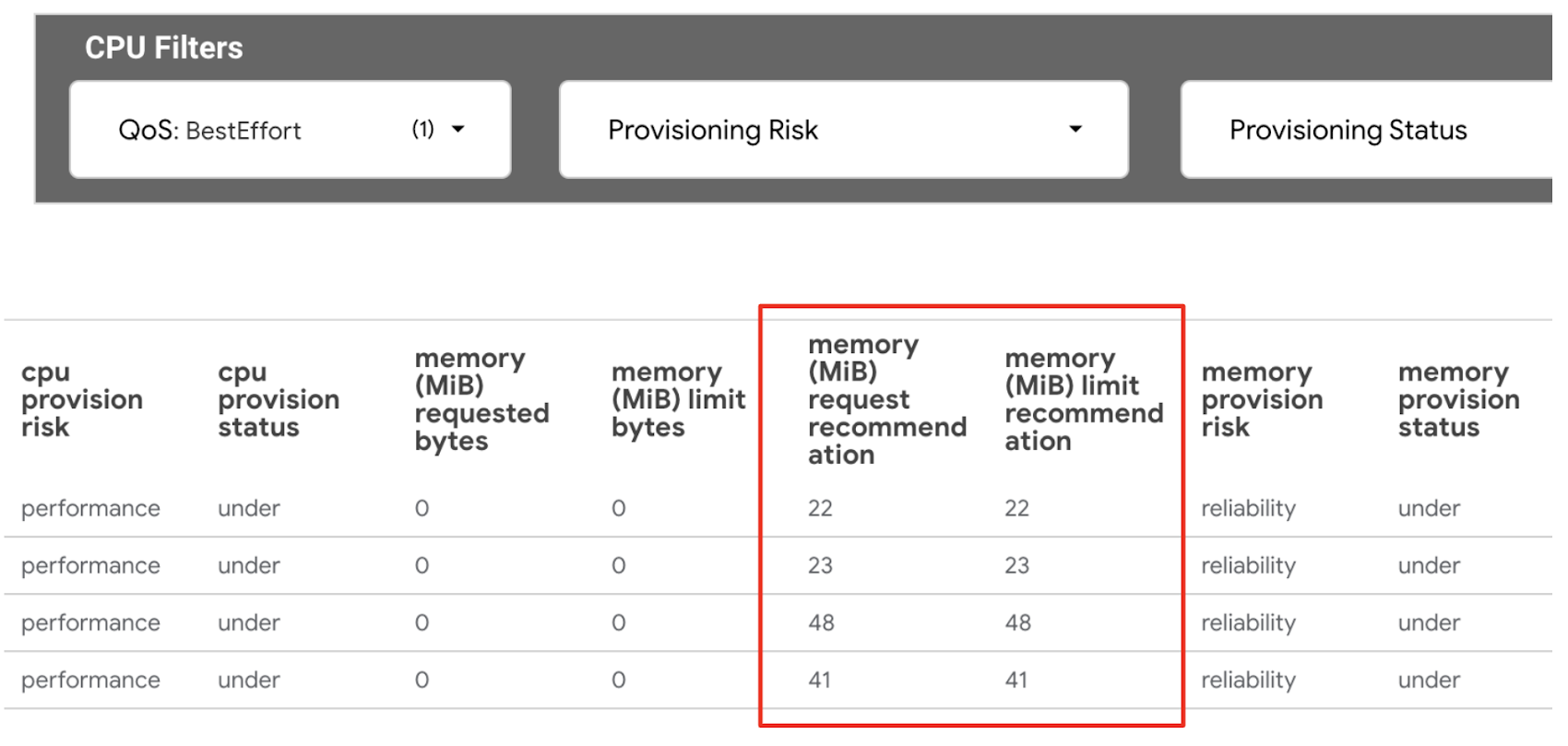
2. Use the Memory Filter ‘QoS’ filtering for ‘BestEffort’.
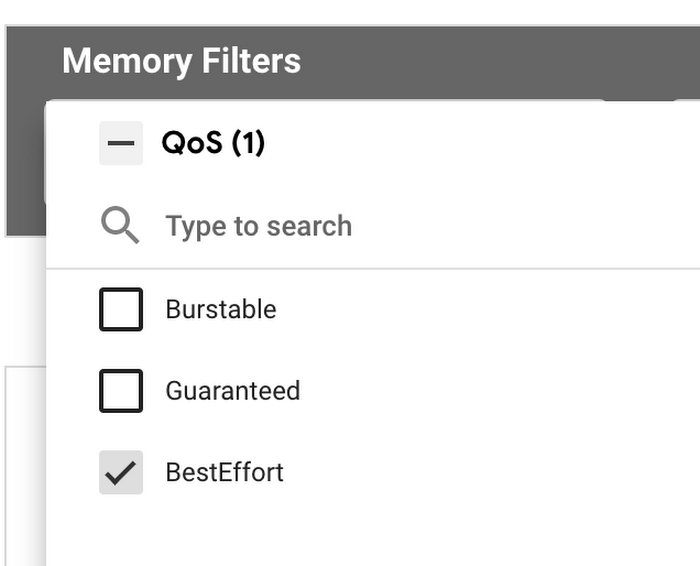
The resulting list will contain identifying information on which workloads resources require an update.
The best practice for updating CPU and memory resources is to do it gradually, in small increments, while monitoring the performance of your applications and services. To update workloads listed:
3. Use the memory (MiB) request recommendation and memory (MiB) limit recommendation to set memory requests and limits. The best practice for memory is to set the same amount of memory for requests and limits. Note: All values are in mebibytes for memory units.
To identify CPU BestEffort workloads:
4. Use the CPU filter QoS as ‘BestEffort’ taking note of the mCPU request recommendation and mCPU limit recommendation values. Note: All values are in millicores for the CPU.

5. In your deployment, set CPU requests equal to or greater than the mCPU request recommendation and use mCPU limit recommendation to set the CPU limit or leave it unbound.
Burstable workloads (reliability or performance risk)
We recommend running CPU burstable workloads in environments where CPU requests are configured to be less than the CPU limit. This enables workloads to experience sudden spikes (during initialization or unexpected high demand) without hindrance.
However, some workloads consistently exceed their CPU request, which can lead to both performance issues and disruptions in your system.
How to improve?
1. Use the VPA container recommendations detail view. For example, to address memory workloads at reliability risk, use the Memory filter ‘QoS’ set to Burstable and Provisioning Risk filter for reliability.
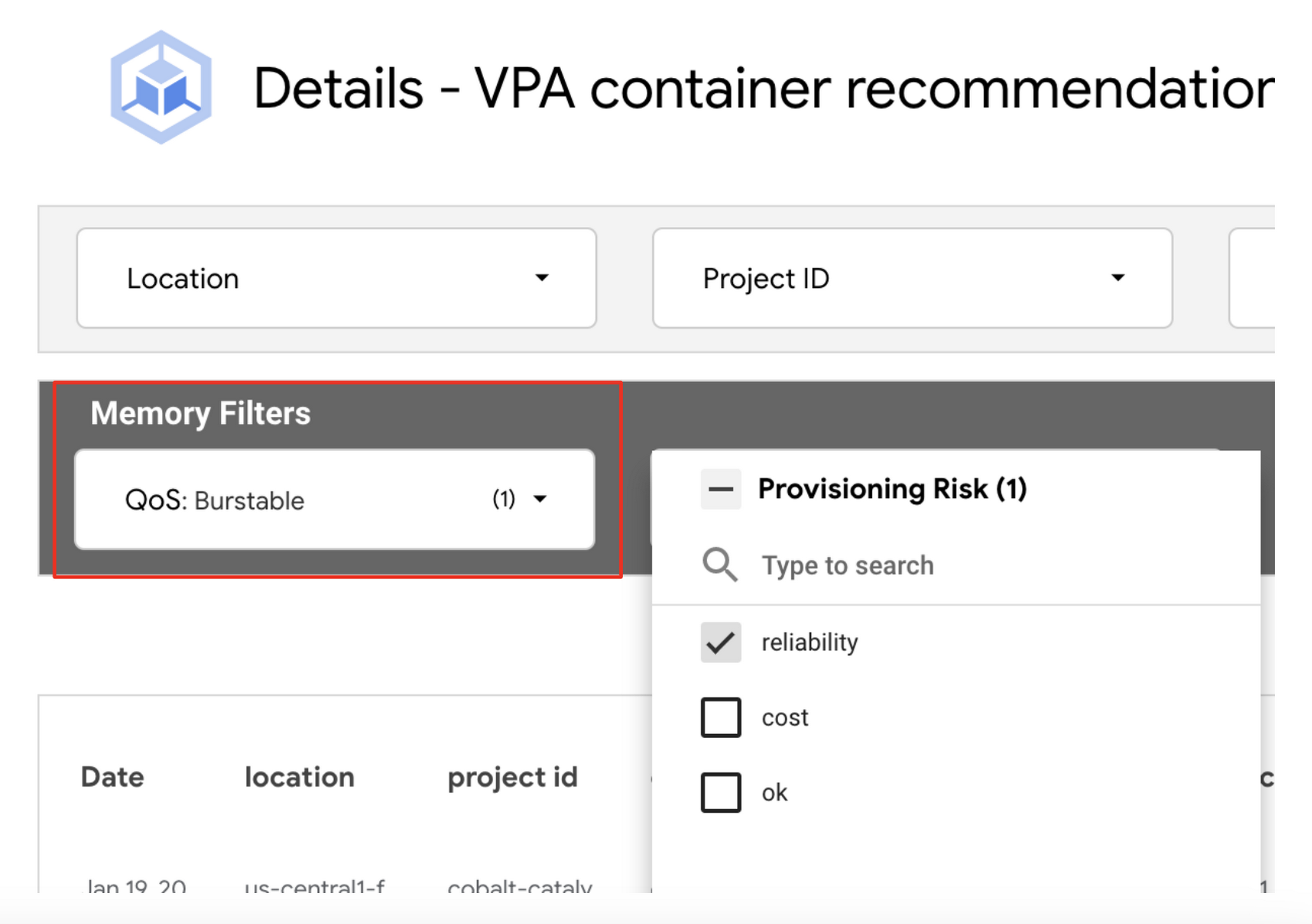
As discussed previously, the best practice for setting your container resources is to use the same amount of memory for requests and limits, and a larger or unbounded CPU limit.
To update Burstable workloads at performance risk:
1. Use the VPA container recommendations detail view. For example, to address memory workloads at reliability risk, use the CPU filter ‘QoS’ set to Burstable and Provisioning Risk filter for performance.
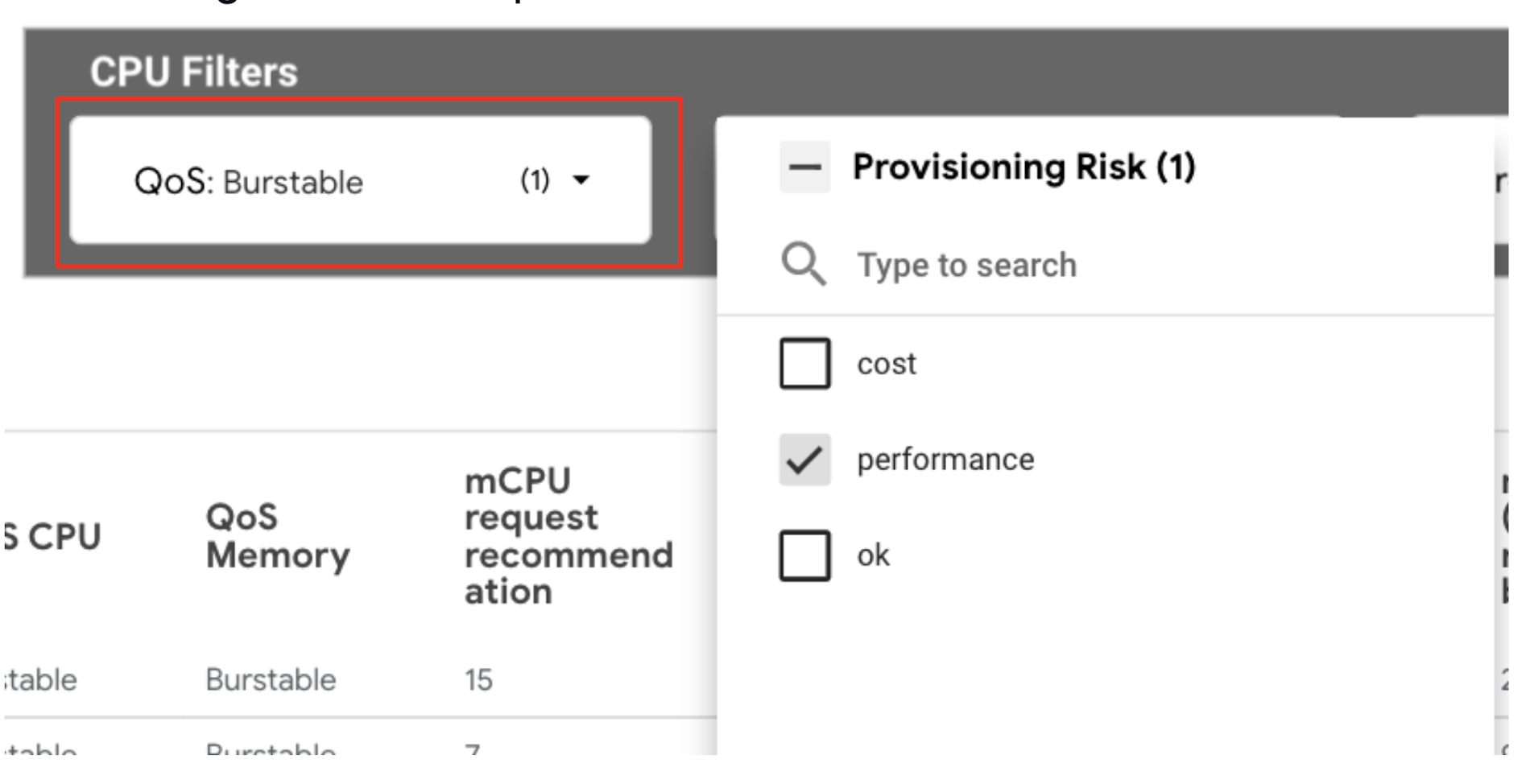
2. Use the mCPU request recommendation and mCPU limit recommendation columns to edit your workload’s CPU requests and limits at or above the VPA recommendations.
Potential CPU savings and Potential Memory savings tiles
These tiles show a positive value indicating cost savings potential. If the value is negative, the current container settings are under-provisioned, and correcting the workload resources will improve performance and reliability.
How to improve?
1. Navigate to the VPA container recommendations detail view dashboard.
2. To find opportunities to reduce cost, use the Provisioning Risk filter and filter for “cost”. These workloads are determined to be over-provisioned and waste resources.
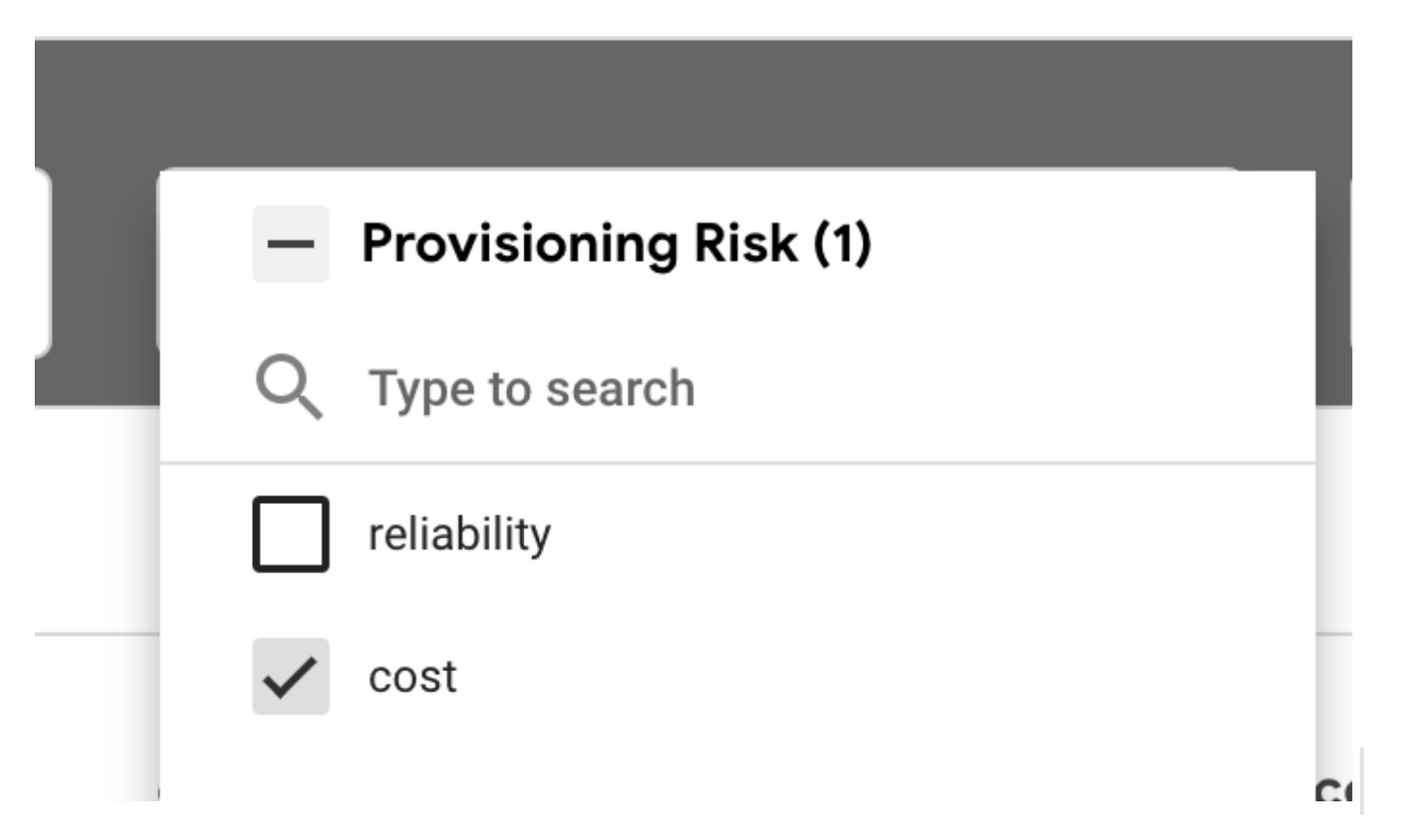
3. Update your workload’s resource configurations to rightsize your containers for CPU and memory. This will reduce the value displayed in these tiles.
Note: It's essential to address reliability or performance risks to ensure workloads remain reliable and performant.
Top over-provisioned workloads list
Over-provisioning workloads will add cost to your GKE bill. This list will organize the workloads to prioritize cost reduction. Workloads with the most significant difference between what's currently requested for CPU and memory and what is recommended will be listed first.
How to improve?
1. On the Recommendation Overview page, use the “Top over-provisioned workloads” list to identify workloads.
2. Review recommendations for requests and limits for memory and CPU listed in the table.

3. Update the container configurations requests and limits values to be closer to the recommended values.
For more details on the workloads, use the VPA container recommendations detail view and filter ‘over’ as the Provisioning Status.
Top under-provisioned workloads list
Under-provisioning workloads can lead to containers failing or throttling. This list organizes workloads where the CPU and memory requests are below VPA recommendations.
How to improve?
1. Similar to the "Top over-provisioned workloads" section, the "Top under-provisioned workloads" identify workloads that are under-provisioned.
2. Review recommendations for CPU and limits are listed in the table.
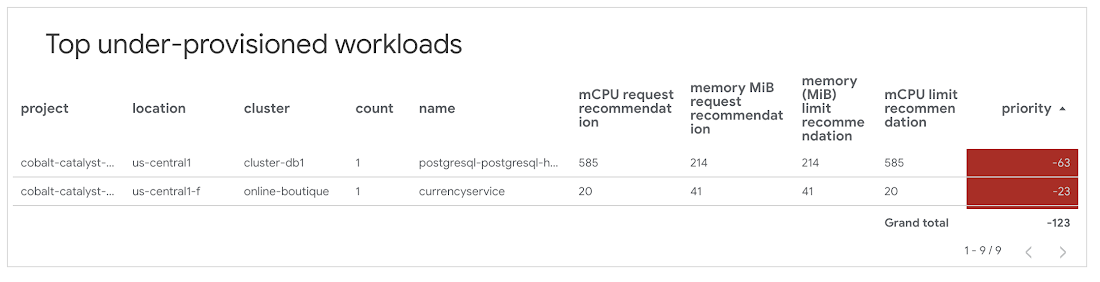
3. Update the container configurations requests and limit values to be closer to the recommended values
Note: Concentrating solely on either over or under-provisioned resources separately can lead to inaccuracies in cost savings or costs. To achieve both cost-effectiveness and reliability, consider alternating between addressing the top over-provisioned and top under-provisioned workloads. By toggling between the lists, you can optimize your application's savings and reliability.
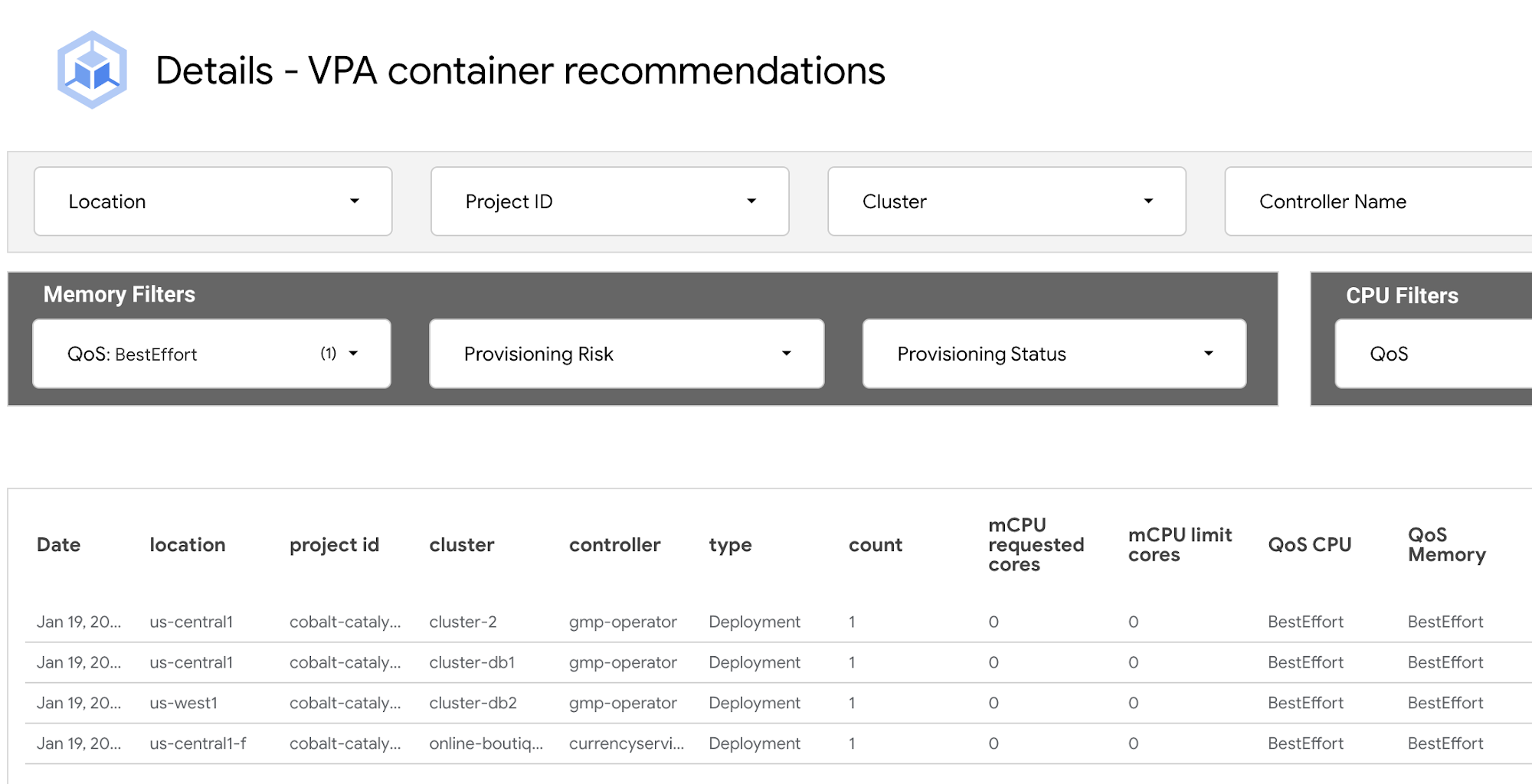
VPA container recommendations detail view
A detailed view of all clusters across all projects as shown below.
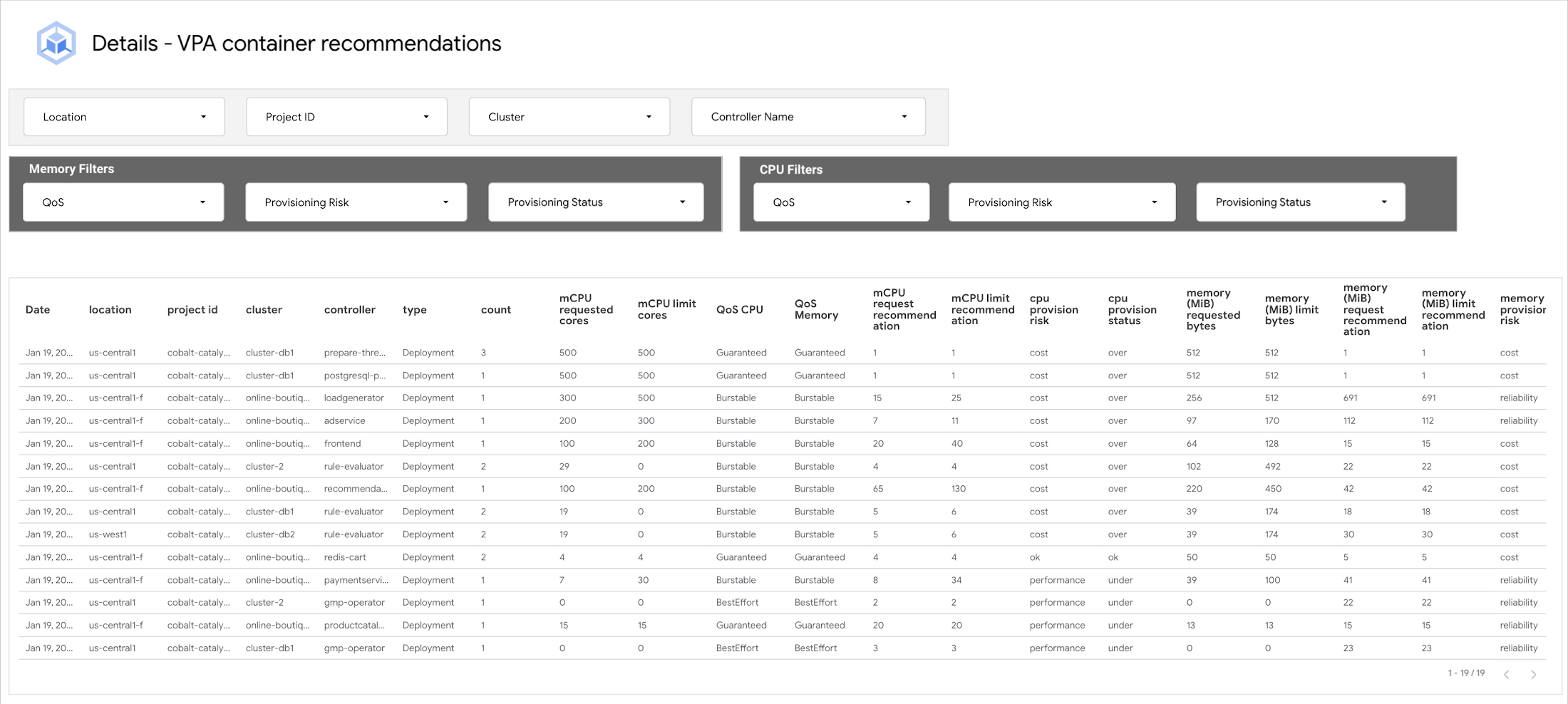
To help you get started on your optimization journey, the table contains three columns to assist in prioritizing which workloads should be tackled first.
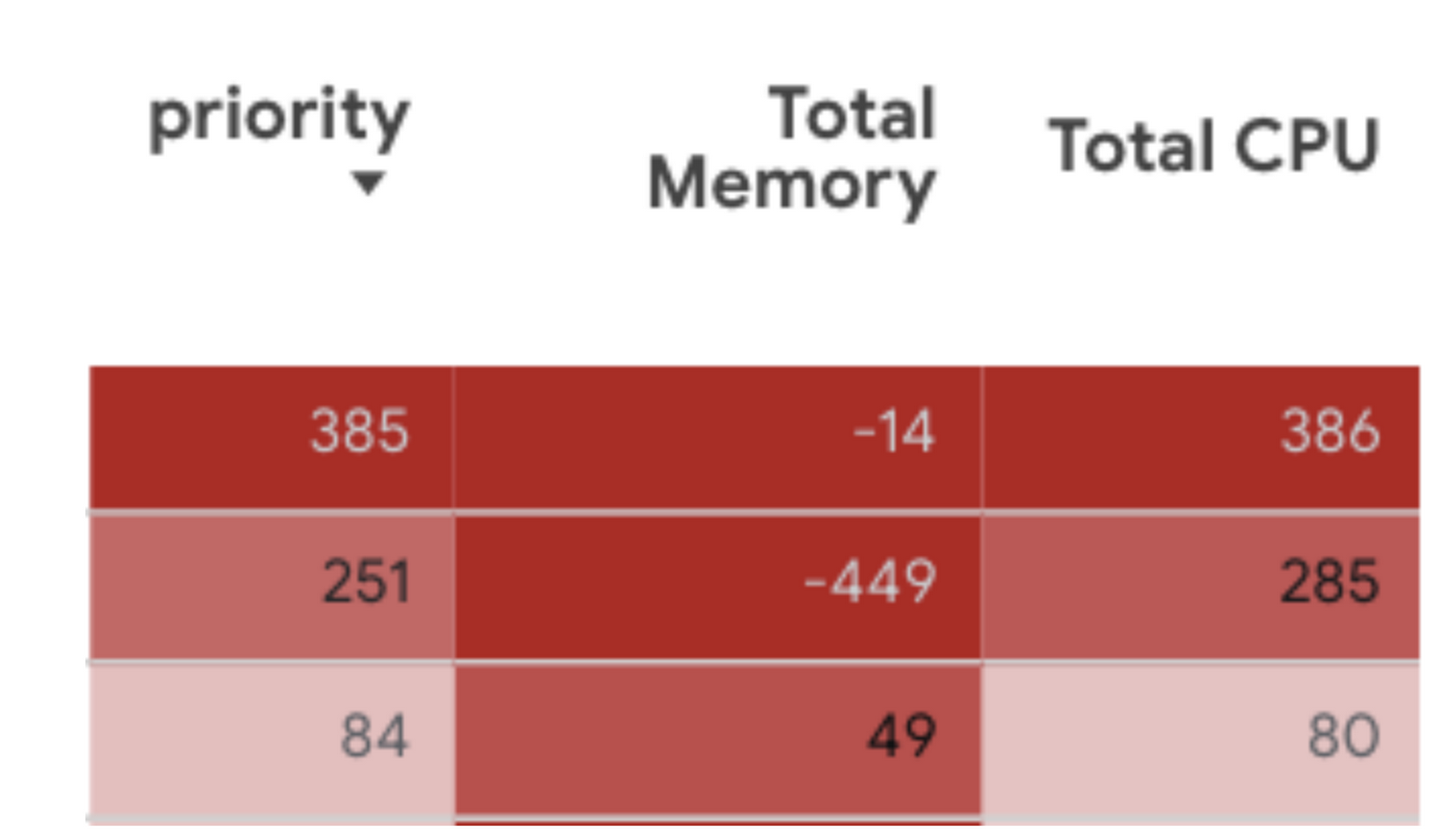
The formula takes into account the difference between the requested resources and the recommended resources for CPU and memory, and then uses a ratio of predefined vCPUs and predefined memory to adjust the priority value.
The “Total Memory" and "Total CPU" columns represent the difference between the current configurations for Memory/CPU and the VPA recommendations for Memory/CPU. A negative value shows the workload is under-provisioned in its respective resource, and a positive value indicates a workload is over-provisioned for that resource.
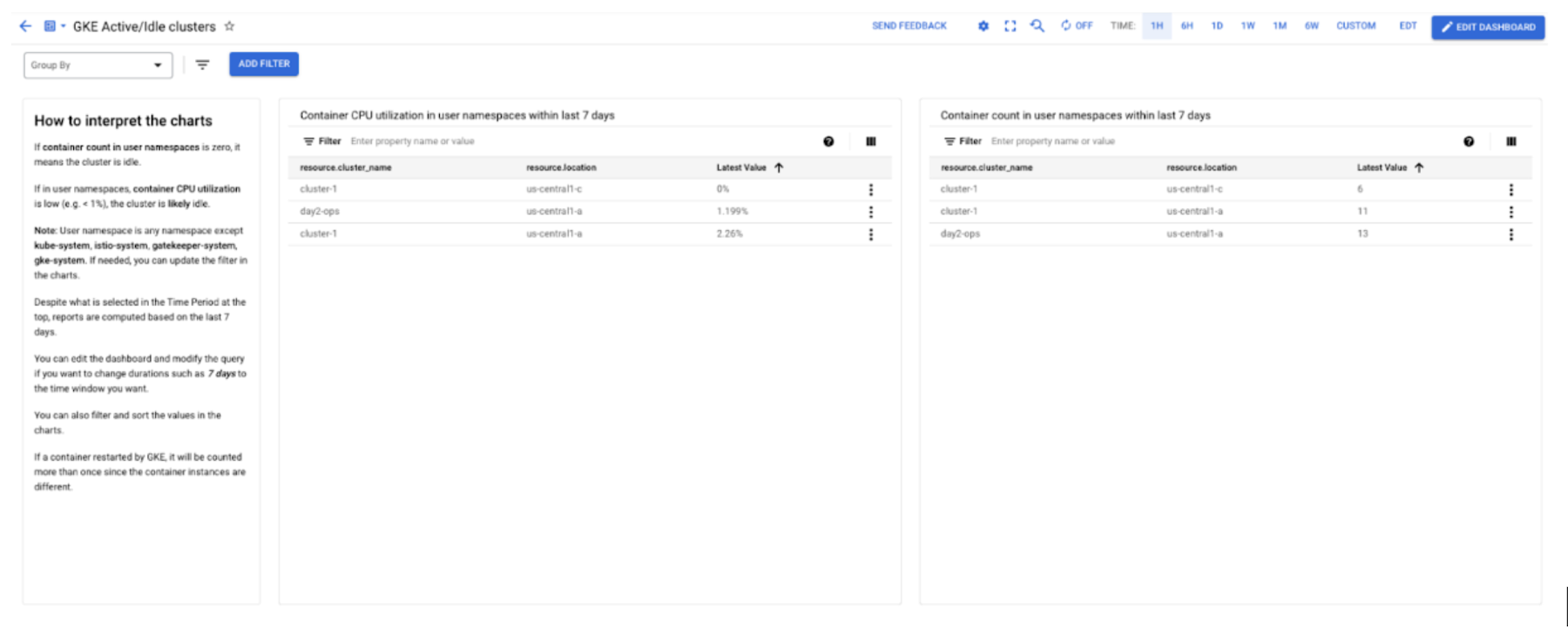
Cloud Monitoring Active/Idle cluster dashboard
Pay-as-you-go is one crucial benefit of cloud computing. It's critical for cost optimization to identify active and idle GKE clusters, so you can shut them down if they are no longer used. One way to do that is to import the 'GKE Active/Idle clusters' dashboard from the sample library in Cloud Monitoring.
The dashboard provides two charts. One counts the running containers in the user namespaces in a certain period. The other shows the CPU usage time the user containers consume in the same time window. It's probably safe to identify those clusters as idle if the container count is zero and the CPU usage is low, such as less than 1%.
Below is a screenshot of an example. You can read the note panel for additional details. After importing the dashboard, you can edit the charts based on your use cases in Cloud Monitoring. Alternatively, you can modify the source file and import it directly. You can find all GKE-related sample dashboards on GitHub in our sample repository.
Get started today
To deploy the VPA recommendation dashboard and begin your optimization journey check out this tutorial with step-by-step instructions.
Please consider using the solution to rightsize your workloads on GKE and navigate to Cloud Monitoring in the Console to try the GKE dashboards. For more information on GKE optimization, check our Best Practices for Running Cost Effective Kubernetes Applications, the YouTube series, and have a look at the GKE best practices to lessen over-provisioning
We welcome your feedback and questions. Please consider joining the Cloud Operations group in Google Cloud Communities.