Music to their ears: microservices on GKE, Preemptible VMs improved Musiio’s efficiency by 7000%
Aron Pettersson
CTO, Musiio
Editor’s note: Advanced AI startup Musiio, the first ever VC-funded music tech company in Singapore, needed more robust infrastructure for the data pipeline it uses to ingest and analyze new music. Moving to Google Kubernetes Engine gave them the reliability they needed; rearchitecting their application as a series of microservices running on Preemptible VMs gave them new levels of efficiency and helped to control their costs. Read on to hear how they did it.
At Musiio we’ve built an AI that ‘listens’ to music tracks to recognize thousands of characteristics and features from them. This allows us to create highly accurate tags, allow users to search based on musical features, and automatically create personalized playlists. We do this by indexing, classifying and ultimately making searchable new music as it gets created—to the tune of about 40,000 tracks each day for one major streaming provider.
But for this technology to work at scale, we first need to efficiently scan tens of millions of digital audio files, which represent terabytes upon terabytes of data.
In Musiio’s early days, we built a container-based pipeline in the cloud orchestrated by Kubernetes, organized around a few relatively heavy services. This approach had multiple issues, including low throughput, poor reliability and high costs. Nor could we run our containers with a high node-CPU utilization for an extended period of time; the nodes would fail or time out and become unresponsive. That made it almost impossible to diagnose the problem or resume the task, so we’d have to restart the scans.
As a part of reengineering our architecture, we decided to experiment with Google Kubernetes Engine (GKE) on Google Cloud Platform (GCP). We quickly discovered some important advantages that allowed us to improve performance and better manage our costs:
- GKE reliability: We were very impressed by GKE’s reliability, as we were able to run the nodes at >90% CPU load for hours without any issues. On our previous provider, the nodes could not take a high CPU load and would often become unreachable.
- Preemptible VMs and GPUs: GKE supports both Preemptible VMs and GPUs on preemptible instances. Preemptible VMs only last up to 24 hours but in exchange are up to 80% cheaper than regular compute instances; attached GPUs are also discounted. They can be reclaimed by GCP at any time during these 24 hours (along with any attached GPUs). However, reclaimed VMs do not disappear without warning. GCP sends a signal 30 seconds in advance, so your code has time to react.
We wanted to take advantage of GKE’s improved performance and reliability, plus lower costs with preemptible resources. To do so, though, we needed to implement some simple changes to our architecture.
Building a microservices-based pipeline
To start, we redesigned our architecture to use lightweight microservices, and to follow one of the most important principles of software engineering: keep it simple. Our goal was that no single step in our pipeline would take more than 15 seconds, and that we could automatically resume any job wherever it left off. To achieve this we mainly relied on three GCP services:
Google Cloud Pub/Sub to manage the task queue,
Google Cloud Storage to store the temporary intermediate results, taking advantage of its object lifecycle management to do automatic cleanup, and
GKE with preemptible nodes to run the code.
Specifically, the new processing pipeline now consists of the following steps:
New tasks are added through an exposed API-endpoint by the clients.
The task is published to Cloud Pub/Sub and attached data is passed to a cloud storage bucket.
The services pulls new tasks from the queue and reports success status.
The final output is stored in a database and all intermediate data is discarded.
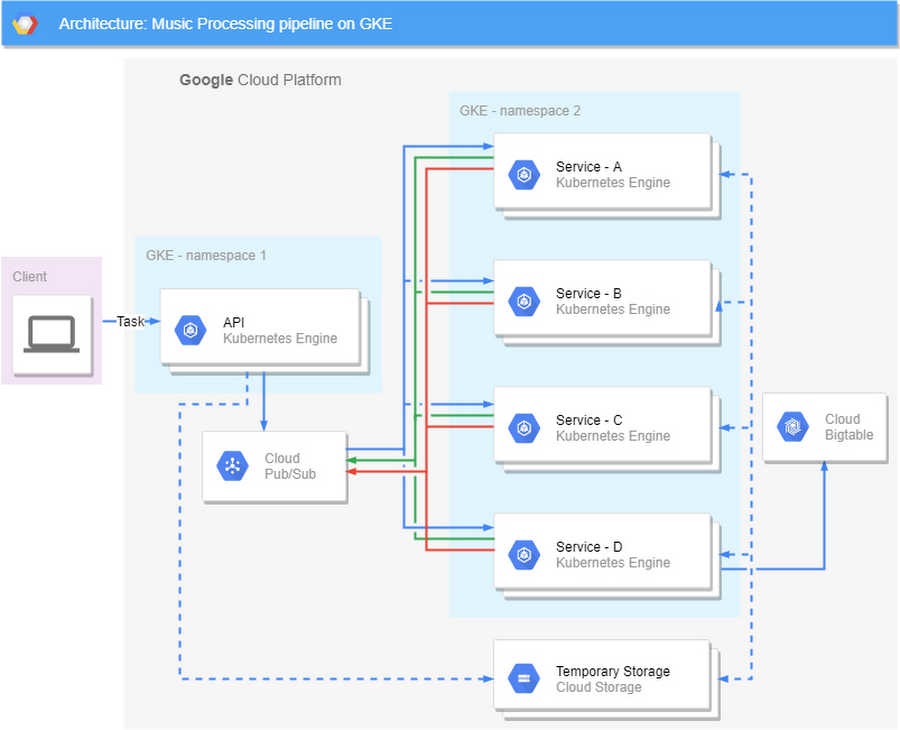
While there are more components in our new architecture, they are all much less complex. Communication is done through a queue where each step of the pipeline reports its success status. Each sub-step takes less than 10 seconds and can easily and quickly resume from the previous state and with no data loss.
How do Preemptible VMs fit in this picture?
Using preemptible resources might seem like an odd choice for a mission-critical service, but because of our microservices design, we were able to use Preemptible VMs and GPUs without losing data or having to write elaborate retry code. Using Cloud Pub/Sub (see 2. above) allows us to store the state of the job in the queue itself. If a service is notified that a node has been preempted, it finishes the current task (which, by design, is always shorter than the 30-second notification time), and simply stops pulling new tasks. Individual services don't have to do anything else to manage potential interruptions. When the node is available again, services begin pulling tasks from the queue again, starting where they left off.
This new design means that preemptible nodes can be added, taken away, or exchanged for regular nodes without causing any noticeable interruption.
GKE’s Cluster Autoscaler also works very well with preemptible instances. By combining the auto scaling features (which automatically replaces nodes that have been reclaimed) with node labels, we were able to achieve an architecture with >99.9% availability that runs primarily on preemptible nodes.
Finally...
We did all this over the course of a month—one week for design, and three weeks for the implementation. Was it worth all this effort? Yes!
With these changes, we increased our throughput from 100,000 to 7 million tracks per week—and at the same cost as before! This is a 7000% increase (!) in efficiency, and was a crucial step in making our business profitable.
Our goal as a company is to be able to transform the way the music industry handles data and volume and make it efficient. With nearly 15 million songs being added to the global pool each year, access and accessibility are the new trend. Thanks to our new microservices architecture and the speed and reliability of Google Cloud, we are on our way to make this a reality.
Learn more about GKE on the Google Cloud Platform website.
