Kubernetes best practices: Setting up health checks with readiness and liveness probes
Sandeep Dinesh
Developer Advocate
Editor’s note: Today is the third installment in a seven-part video and blog series from Google Developer Advocate Sandeep Dinesh on how to get the most out of your Kubernetes environment.
Distributed systems can be hard to manage. A big reason is that there are many moving parts that all need to work for the system to function. If a small part breaks, the system has to detect it, route around it, and fix it. And this all needs to be done automatically!
Health checks are a simple way to let the system know if an instance of your app is working or not working. If an instance of your app is not working, then other services should not access it or send a request to it. Instead, requests should be sent to another instance of the app that is ready, or retried at a later time. The system should also bring your app back to a healthy state.
By default, Kubernetes starts to send traffic to a pod when all the containers inside the pod start, and restarts containers when they crash. While this can be “good enough” when you are starting out, you can make your deployments more robust by creating custom health checks. Fortunately, Kubernetes make this relatively straightforward, so there is no excuse not to!
In this episode of “Kubernetes Best Practices”, let’s learn about the subtleties of readiness and liveness probes, when to use which probe, and how to set them up in your Kubernetes cluster.

Types of health checks
Kubernetes gives you two types of health checks, and it is important to understand the differences between the two, and their uses.Readiness
Readiness probes are designed to let Kubernetes know when your app is ready to serve traffic. Kubernetes makes sure the readiness probe passes before allowing a service to send traffic to the pod. If a readiness probe starts to fail, Kubernetes stops sending traffic to the pod until it passes.Liveness
Liveness probes let Kubernetes know if your app is alive or dead. If you app is alive, then Kubernetes leaves it alone. If your app is dead, Kubernetes removes the Pod and starts a new one to replace it.
How health checks help
Let’s look at two scenarios where readiness and liveness probes can help you build a more robust app.Readiness
Let’s imagine that your app takes a minute to warm up and start. Your service won’t work until it is up and running, even though the process has started. You will also have issues if you want to scale up this deployment to have multiple copies. A new copy shouldn’t receive traffic until it is fully ready, but by default Kubernetes starts sending it traffic as soon as the process inside the container starts. By using a readiness probe, Kubernetes waits until the app is fully started before it allows the service to send traffic to the new copy.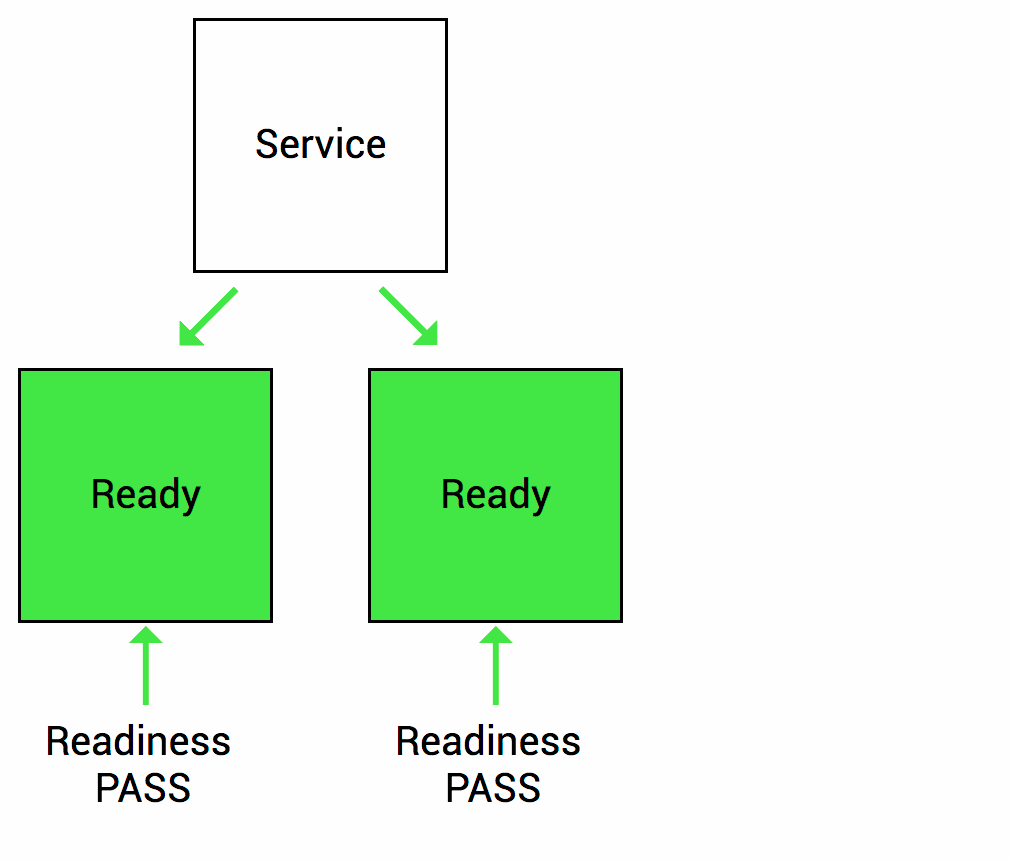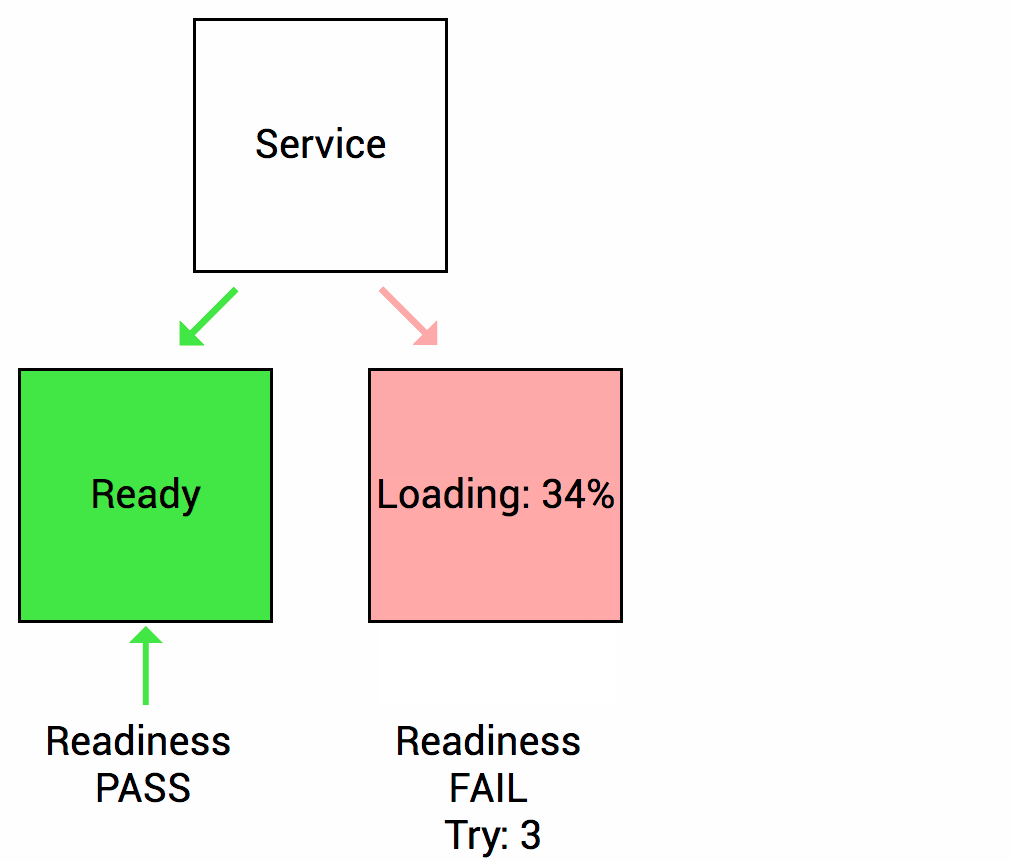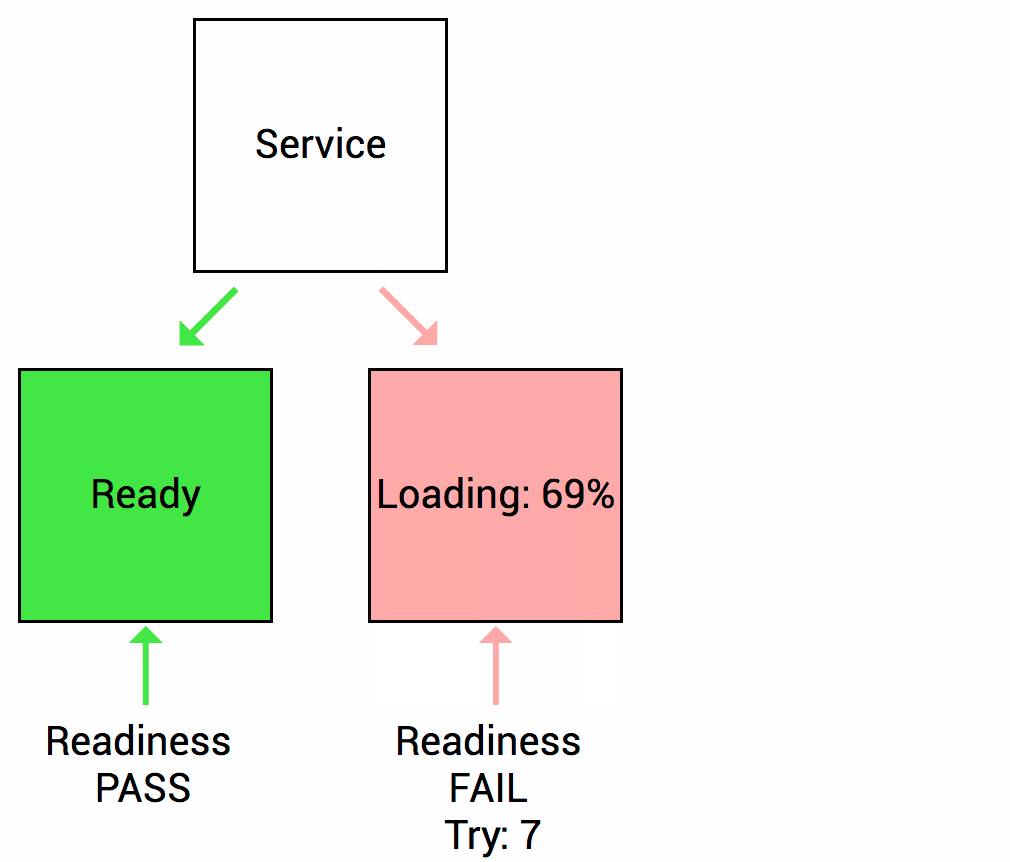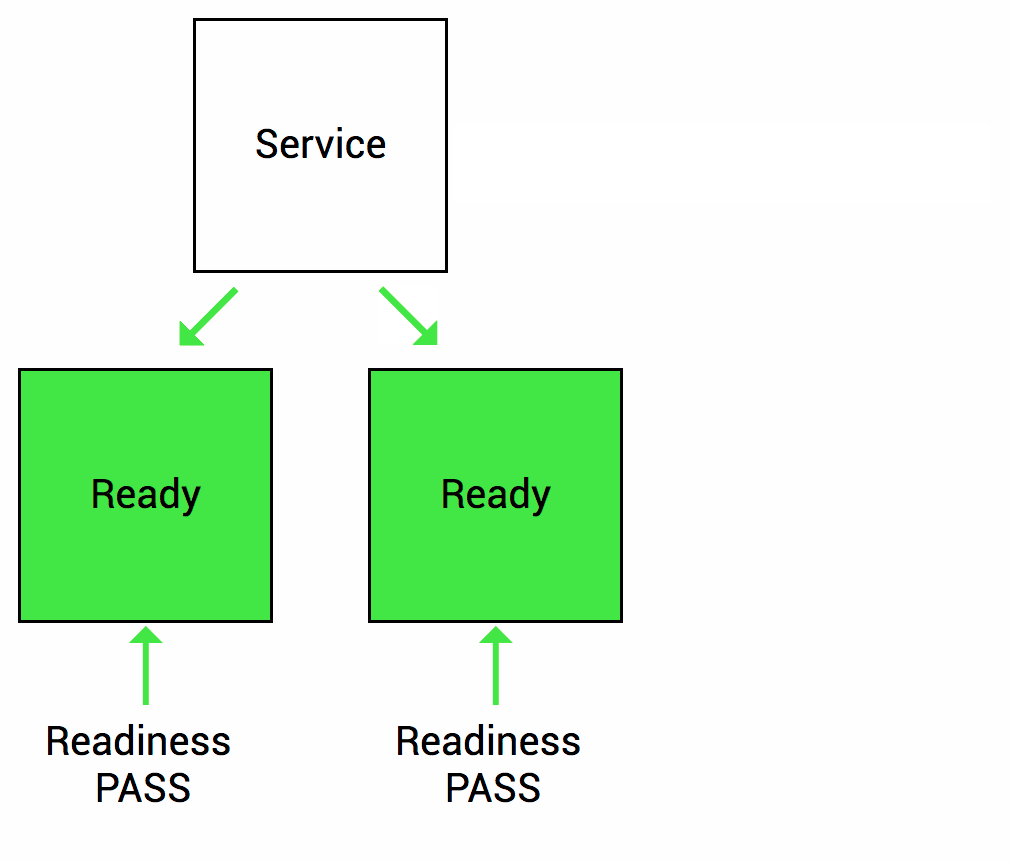
Liveness
Let’s imagine another scenario where your app has a nasty case of deadlock, causing it to hang indefinitely and stop serving requests. Because the process continues to run, by default Kubernetes thinks that everything is fine and continues to send requests to the broken pod. By using a liveness probe, Kubernetes detects that the app is no longer serving requests and restarts the offending pod.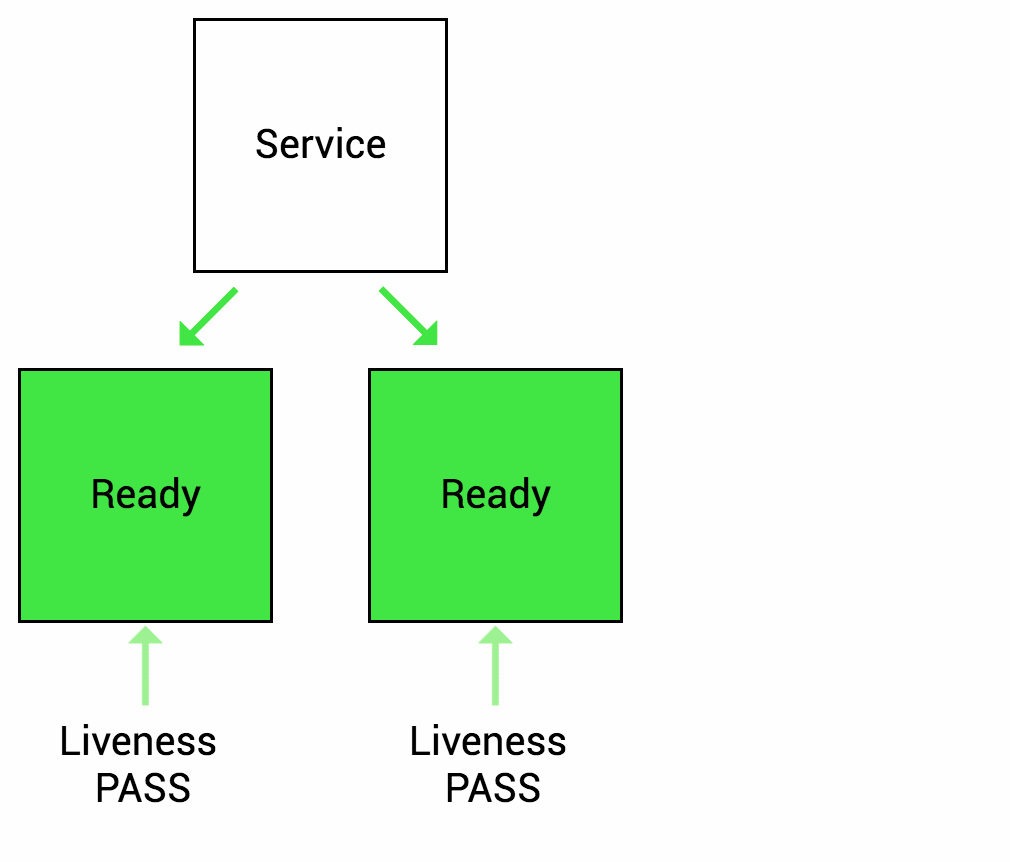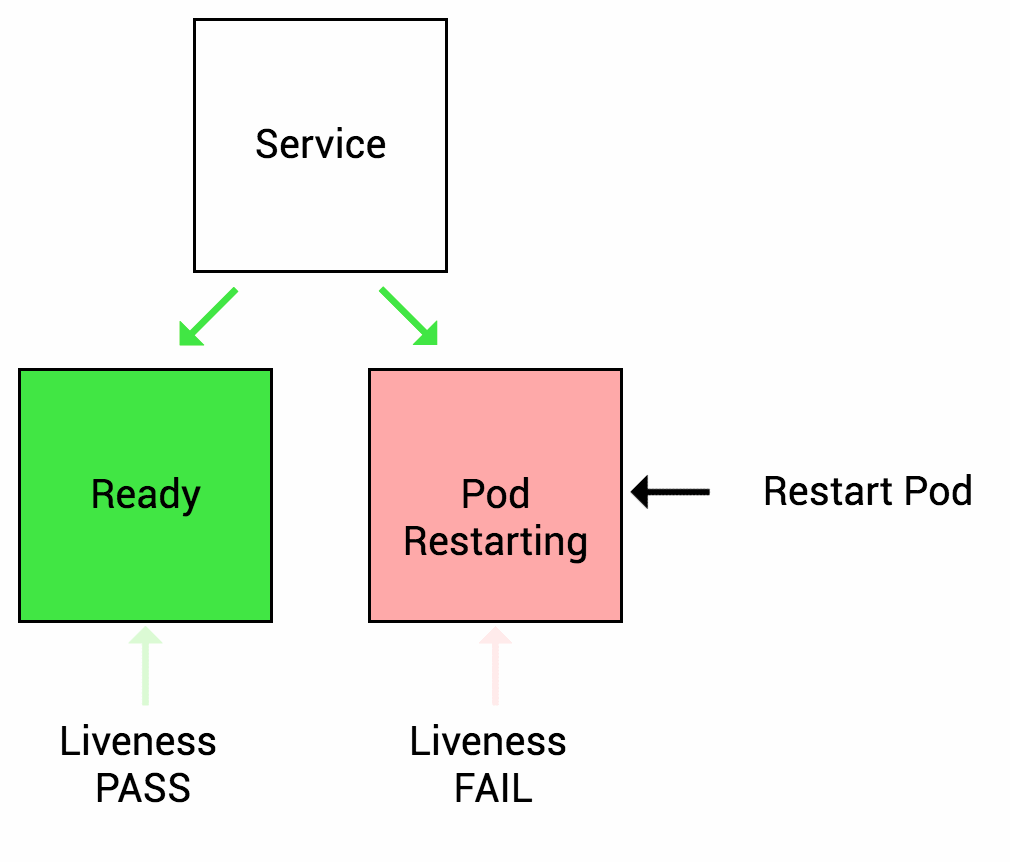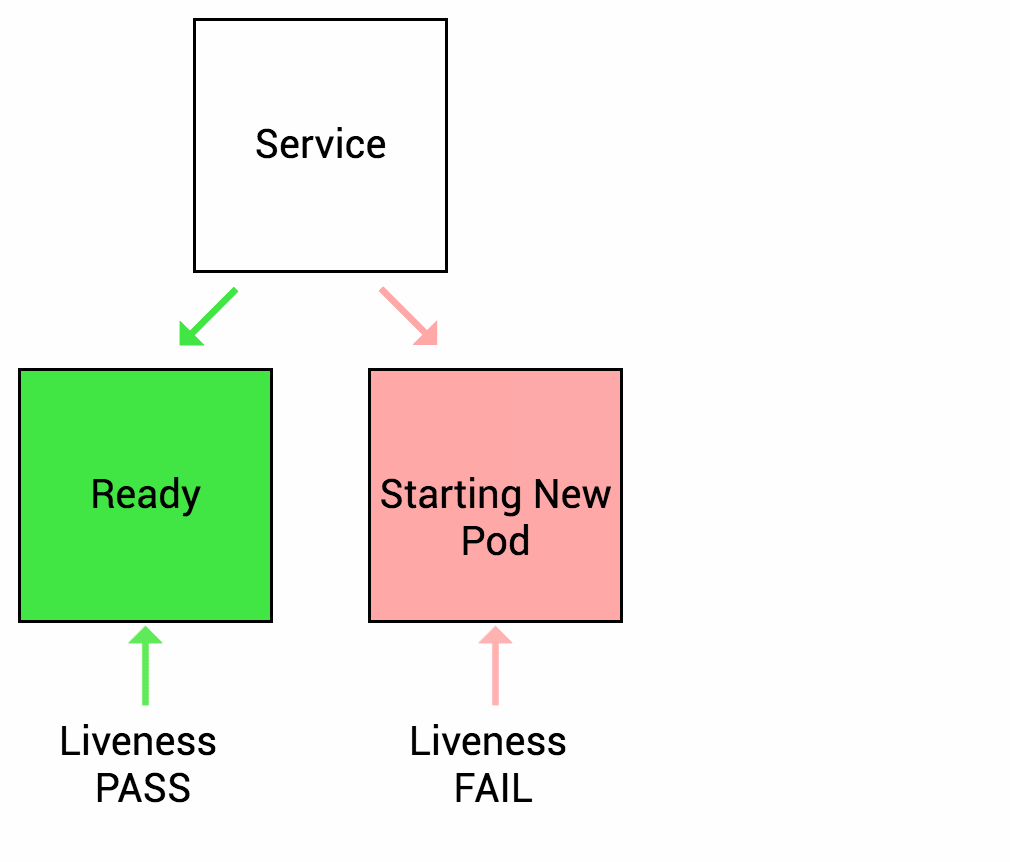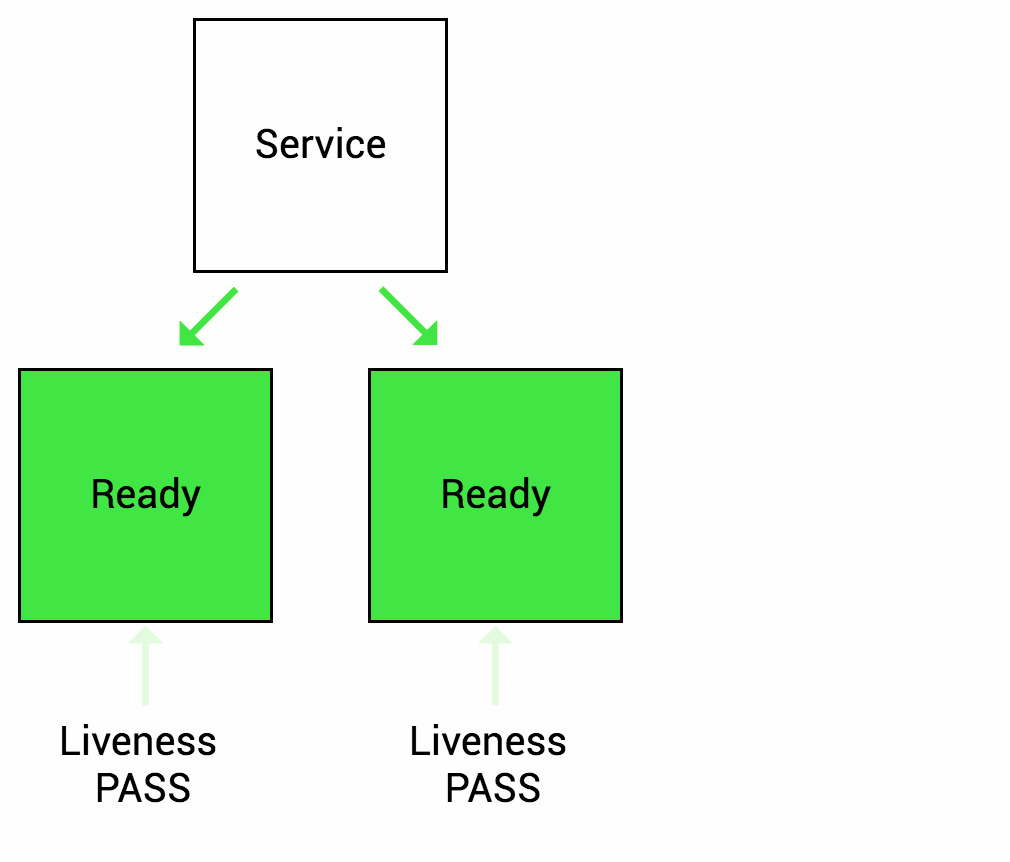
Type of Probes
The next step is to define the probes that test readiness and liveness. There are three types of probes: HTTP, Command, and TCP. You can use any of them for liveness and readiness checks.HTTP
HTTP probes are probably the most common type of custom liveness probe. Even if your app isn’t an HTTP server, you can create a lightweight HTTP server inside your app to respond to the liveness probe. Kubernetes pings a path, and if it gets an HTTP response in the 200 or 300 range, it marks the app as healthy. Otherwise it is marked as unhealthy.You can read more about HTTP probes here.
Command
For command probes, Kubernetes runs a command inside your container. If the command returns with exit code 0, then the container is marked as healthy. Otherwise, it is marked unhealthy. This type of probe is useful when you can’t or don’t want to run an HTTP server, but can run a command that can check whether or not your app is healthy.You can read more about command probes here.
TCP
The last type of probe is the TCP probe, where Kubernetes tries to establish a TCP connection on the specified port. If it can establish a connection, the container is considered healthy; if it can’t it is considered unhealthy.TCP probes come in handy if you have a scenario where HTTP probes or command probe don’t work well. For example, a gRPC or FTP service is a prime candidate for this type of probe.
You can read more about TCP probes here.
Configuring the initial probing delay
Probes can be configured in many ways. You can specify how often they should run, what the success and failure thresholds are, and how long to wait for responses. The documentation on configuring probes is pretty clear about the different options and what they do.However, there is one very important setting that you need to configure when using liveness probes. This is the initialDelaySeconds setting.
As I mentioned above, a liveness probe failure causes the pod to restart. You need to make sure the probe doesn’t start until the app is ready. Otherwise, the app will constantly restart and never be ready!
I recommend using the p99 startup time as the initialDelaySeconds, or just take the average startup time and add a buffer. As your app's startup time gets faster or slower, make sure you update this number.




