Optimize costs for Windows workloads using Persistent Disk Async Replication
Brian Kudzia
Enterprise Infrastructure Customer Engineer
Akaash Rampersad
Customer Engineer
Before launching your critical workloads in the cloud, you need to plan for disaster recovery. A robust disaster recovery (DR) strategy can minimize business disruption by enabling rapid recovery in another region. For most traditional Windows Server environments, DR also requires careful consideration of Microsoft licensing compliance, costs, and how quickly you can recover — including the time it takes to manually remediate any domain issues on your member servers.
Google Cloud offers various options for robust protection. In this blog, we focus on Persistent Disk Asynchronous Replication (PD Async Replication), which has been generally available since June 2023.
PD Async Replication delivers quick recovery from unforeseen disasters. It replicates storage blocks across regions, achieving low Recovery Point Objective (RPO) under one minute and helps reduce Recovery Time Objective (RTO). In the unlikely event of a regional compute outage in the workload’s primary region, PD Async Replication helps ensure workload data is available in the DR region by replicating both boot and data disks. These replicated workloads can then be spun up quickly and programmatically using tools like Terraform or the gcloud SDK to minimize the business impact.Customers running Windows Server on Google Compute Engine can see particular benefit from this capability, as it minimizes licensing costs, speeds up recovery, and reduces the amount of manual intervention that might be required in a traditional DR solution. The on-demand licensing model associated with Windows Server instances incurs charges only for running virtual machines, not disks. Notably, if PD Async Replication is used with disks that are not attached to running VMs, there are no licensing costs. Therefore, limiting VM activation within the DR region solely to actual disaster scenarios (including testing) presents an opportunity to minimize licensing costs.
In the following example, we examine a small Windows Server with Active Directory environment. Let's assume there is an on-premises component running Active Directory domain controllers, but there are also domain controllers in Google Cloud. This example has a single production region in us-east4. The DR region is designated as us-central1. Cloud DNS is configured according to best practices for Domain Forwarding and Domain Peering for Active Directory environments. Let's take a look at a sample architecture diagram, and dissect it further:
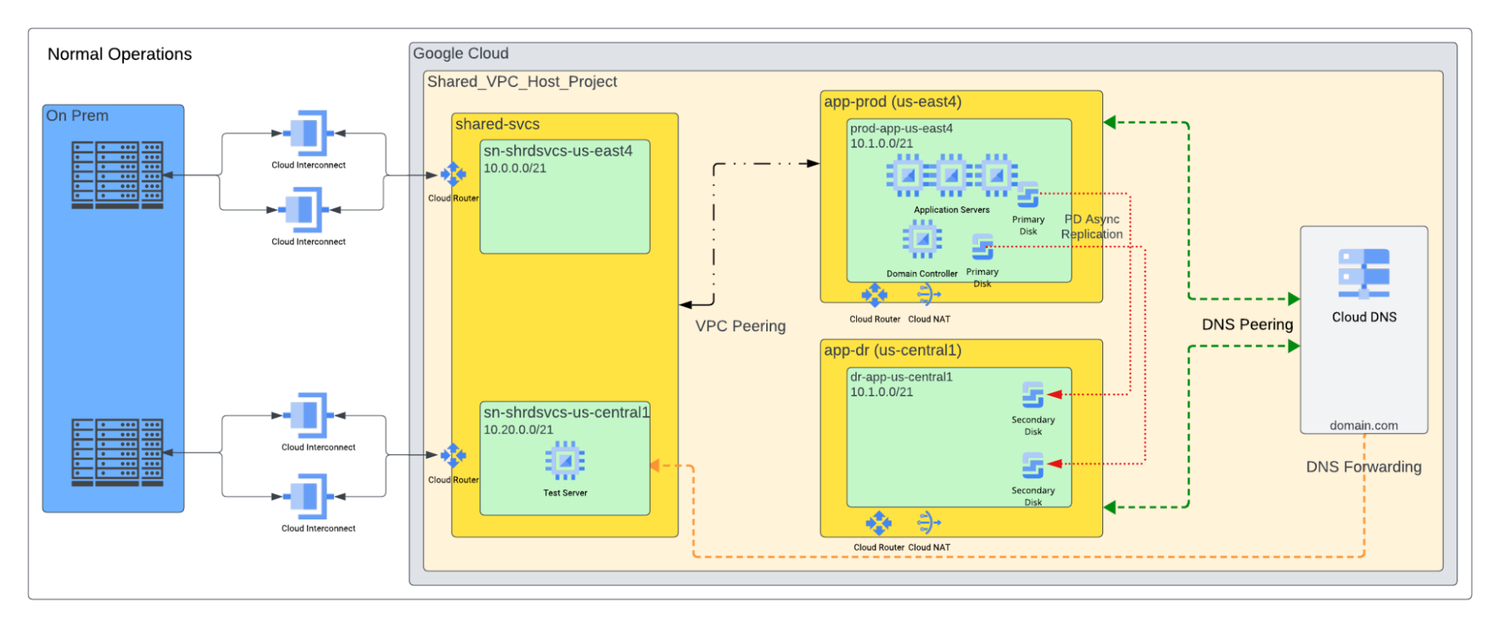
PD Async Replication plays a crucial role in safeguarding data continuity within this DR environment. It ensures the contents of all boot and data disks, including Active Directory information, from the production region (us-east4), are mirrored onto disks in the designated DR region (us-central1). This guarantees data and Active Directory availability even if a catastrophic event renders us-east4 inaccessible.
While storage replication is paramount, recovering quickly hinges on additional configurations. In typical DR scenarios, different Classless Inter-Domain Routing (CIDR) blocks are implemented for both environments. However, this specific example differs by utilizing the same IP Subnet range for both production and DR. This strategic choice facilitates rapid Windows Server recovery by eliminating the need to reconfigure the network interface, on-premises routing adjustments, or Active Directory DNS changes. Notably, the DR-to-shared-svcs peering link remains incomplete, effectively circumventing potential IP conflict issues.
During a DR event, the following processes occur in quick succession:
-
Production VMs are powered off (if possible — depending on the disaster scenario)
-
PD Async Replication is stopped
-
VPC Peering from the Production environment is severed
-
Disaster Recovery VMs are built using the same configuration as the Production VMs
-
Instance configuration including Network IP will be the same
-
Replicated Boot and Data disks from Production VMs are used during instance creation
-
VPC Peering to the DR environment is established
By preserving the IP address along with the low RPO/RTO replication of the disks, the DR VMs boot up with the existing Production configuration without the need to rejoin the Domain. This also means that you can follow this same process and mirror disks in DR back to production for easy failback once your disaster scenario is over, providing a full end-to-end solution.
You can use PD Async Replication to protect a variety of Windows workloads including SQL Server; it is especially useful in cases where the use of native replication technology (such as SQL Server AlwaysOn) might be cost-prohibitive due to the additional licensing required.
You can find the Terraform code for this example deployment, along with detailed instructions on how to use it, in this repository.
This blog post introduces PD Async Replication and its key features. However, for in-depth understanding and to confirm it aligns with your needs, please review the product page. You can find pricing for PD Asynchronous Replication here.