One click deploy Triton Inference Server in Google Kubernetes Engine
Dong Meng
Solutions Architect NVIDIA
Kevin Tsai
Head of Generative AI Solutions Architecture, Google Cloud
Try Google Cloud
Start building on Google Cloud with $300 in free credits and 20+ always free products.
Free trialtl;dr: We introduce the One-Click Triton Inference Server in Google Kubernetes Engine (GKE) Marketplace solution (solution, readme) to help jumpstart NVIDIA GPU-enabled ML inference projects.
Deep Learning research in the past decade has provided a number of exciting and useful models for a variety of different use cases. Less than 10 years ago, AlexNet was the state-of-the-art image classification model and brought the Imagenet moment marked as ground zero for deep learning explosion. Today, Bidirectional Encoder Representations from Transformers (BERT) and related family of models enable a variety of complex natural language use cases from Text Classification to Question and Answering (Q&A). While top researchers are creating bleeding edge models exceeding hundreds of millions of parameters, bringing these models to production in large-scale exposes additional challenges we have to solve.
Scale Inference with NVIDIA Triton Inference Server on Google Kubernetes Engine
While recent ML frameworks have made model training and experimentation more accessible, serving ML models, especially in a production environment, is still difficult. When building an inference environment, we commonly run into the following pain points:
Complex dependencies and APIs of DL Frameworks backend
Production workflow includes not just model inference but also preprocessing steps
Hard to find nobs to maximize accelerator performance
Too much scripting and configurations about robust Ingress and load balancing
In this blog, we will introduce the One-Click Triton Inference Server in Google Kubernetes Engine (GKE), and how the solution scales these ML models, meet stringent latency budgets, and optimize operational costs.
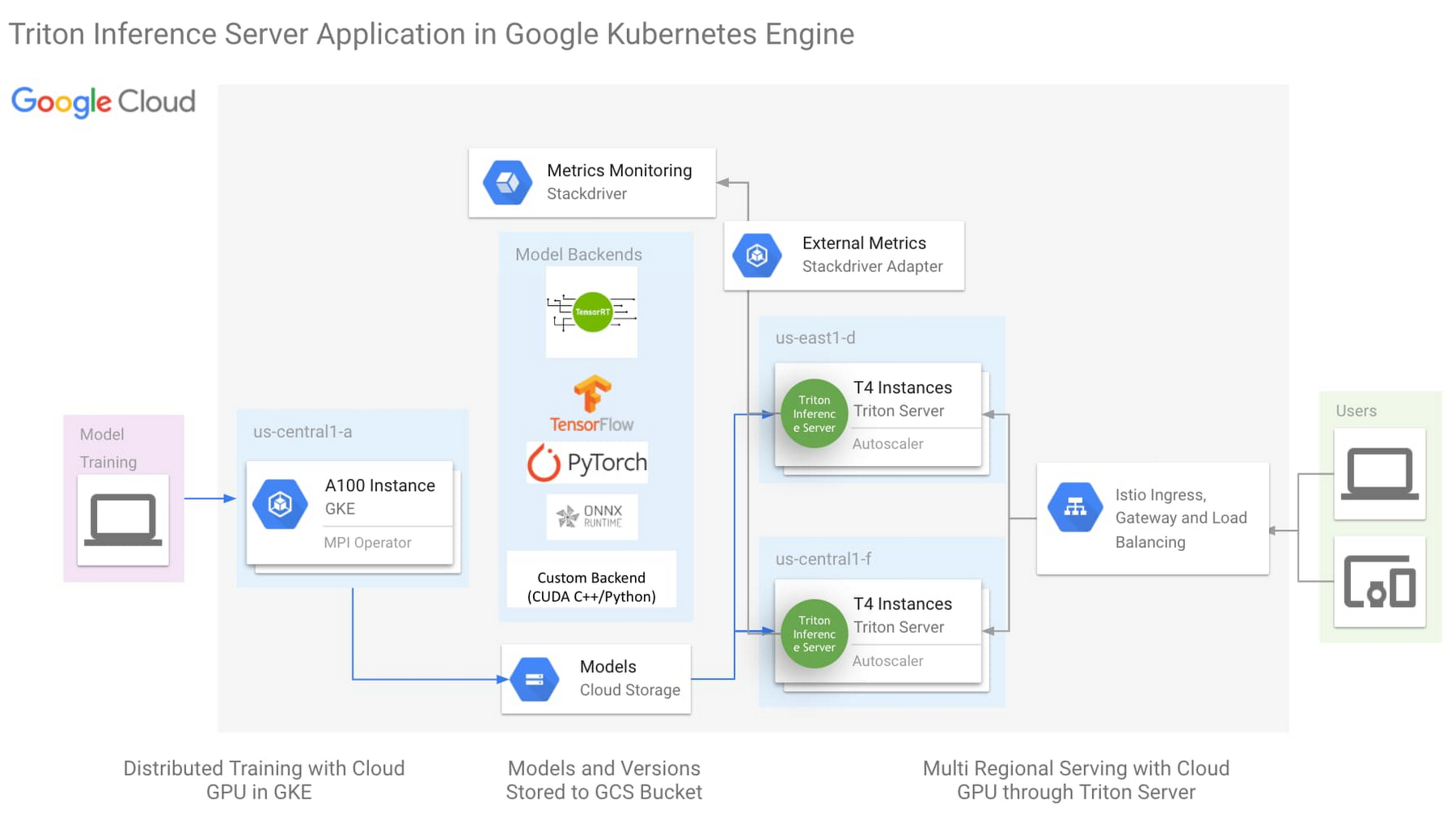
The architecture above is the One-Click NVIDIA Triton Inference Server solution (click here to try now), with the following key aspects:
NVIDIA Triton Inference Server
Istio for simplified Ingress and Load Balancing
Horizontal Pod Autoscaler(HPA) monitoring external metric through Stackdriver
Triton Inference Server is an open source inference server from NVIDIA with backend support for most ML Frameworks, as well as custom backend for python and C++. This flexibility simplifies ML infrastructure by reducing the need to run different inference servers to serve different frameworks. While Triton was created to leverage all the advanced features of the GPU, it is also designed to be highly performant on the CPU. With this flexibility in ML framework and processing hardware support, Triton can reduce the complexity of model serving infrastructure.
More detailed description of the One-Click Triton solution could be found here.
NVIDIA Triton Inference Server for mission-critical ML model serving
Organizations today are looking to create a shared-service ML platform to help democratize ML across their business units. To be successful, a share-service ML serving platform must be reliable and cost effective. To address these requirements NVIDIA has created two capabilities that are unique to the Triton Inference Server:
Model Priority
TensorRT
Maximizing Utilization and ROI with Model Priority
When we build a shared-service inference platform, we will need to expect to support models for multiple use cases, each with different latency sensitivity, business criticality, and transient load fluctuations. At the same time, we also need to consider control costs through standardization and economy of scale. However, these requirements are often in conflict. For example, a business-critical, latency-sensitive model with a strict Service Level Objective (SLO) will present to us two choices: do we pre-provision compute resources in anticipation of transient load fluctuations and pay for the excess unused compute, or do we provision only the typical compute resources needed to save cost, and risk violating the latency SLO when transient loads spike?
In the population of models we serve, we can usually find a subset that are both latency-sensitive and business critical. These can be treated as Tier-1 models, with the remaining as Tier-2.
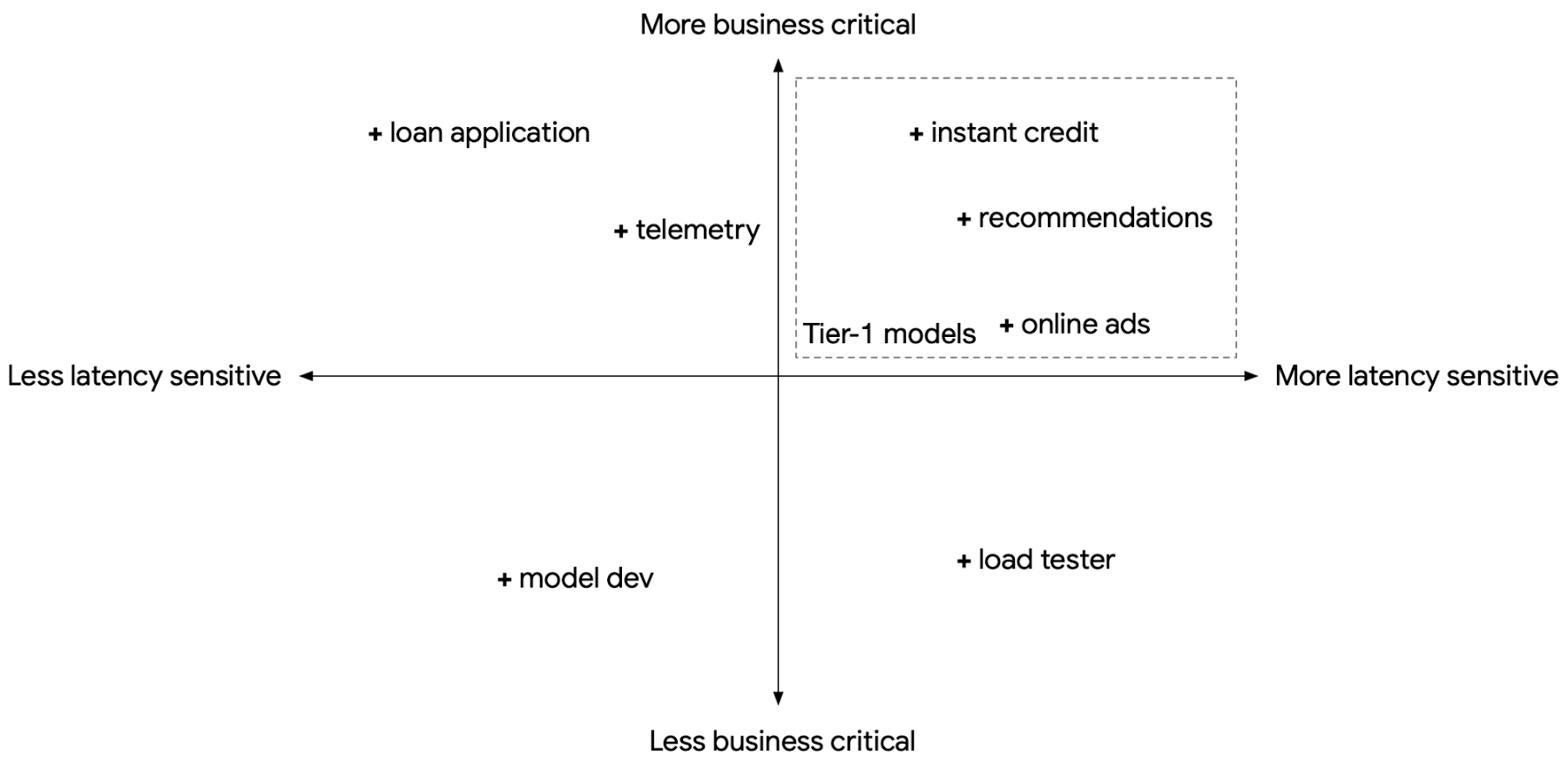
With Triton Inference Server, we have the ability to mark a model as PRIORITY_MAX. This means when we consolidate multiple models in the same Triton instance and there is a transient load spike, Triton will prioritize fulfilling requests from PRIORITY_MAX models (Tier-1) at the cost of other models (Tier-2).
Below is an illustration of three common load spiking scenarios. In the first (1) scenario, load spikes but load is within the provisioned compute limit. Both models continue normally. In the second (2) scenario, the Tier-1 model spikes and the combined compute load exceeds the provisioned compute limit. Triton prioritizes the Tier-1 model by reducing compute on the Tier-2 model. In the third (3) scenario, the Tier-2 model spikes. Triton ensures the Tier-1 model will receive the compute resources it needs. In all three scenarios.
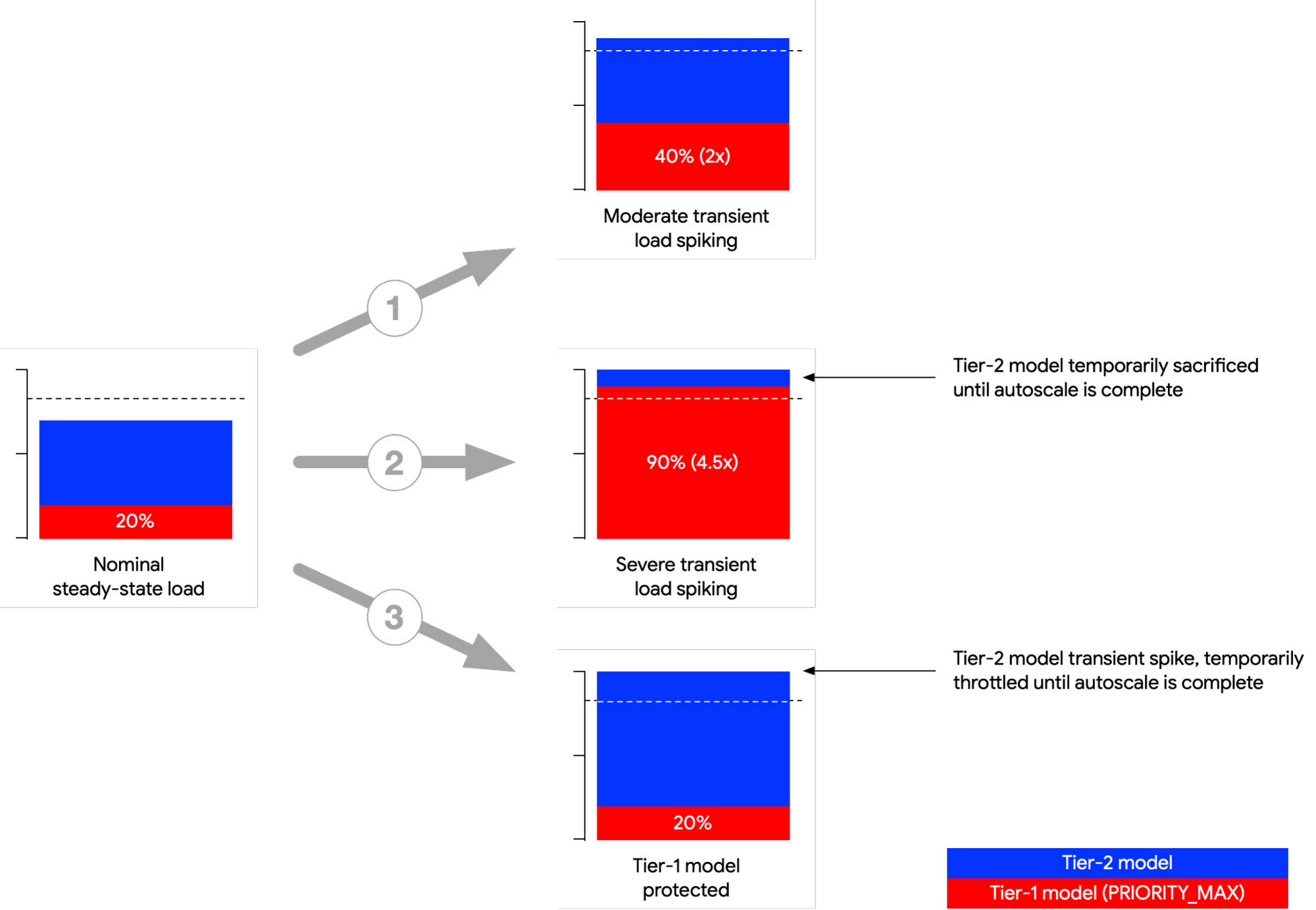
While GKE provides autoscaling, relying only on GKE to autoscale on transient load spikes can lead to SLO violation, as load spikes can appear in seconds, whereas GKE autoscales in minutes. Model priority provides a short window to buffer transient spikes to help maintain Tier-1 model SLO while GKE autoscales its nodepool. For a description of options to address transient load spikes, please refer to the reference guide Mitigating transient load effects on ML serving latency.
Maximizing Performance and Cost Effectiveness with NVIDIA TensorRT
While Triton offers a multitude of backend framework support and a highly pluggable architecture, the TensorRT backend offers the best performance benefits.
NVIDIA TensorRT (TRT) is an SDK for high performance deep learning inference on NVIDIA GPU’s, leveraging out-of-box performance enhancements by applying optimization such as layer fusion, mixed precision and structured sparsity. With the latest NVIDIA A100 GPU as an example, TensorRT incorporates Tensor Cores, a region of the GPU optimized for FP16 and INT8 matrix math, with support for structured sparsity. For optimizations TensorRT applied to the BERT model, please visit the reference blog.
The following Triton configuration will help GPU inference performance and utilization when used with TensorRT:
Concurrent execution: a separate copy of the model is run in its own separate CUDA stream, allowing for concurrent CUDA kernel executions simultaneously. This allows for increased parallelization.
Dynamic batching: Triton will dynamically group together multiple inference requests on the server-side within the constraint of specified latency requirements.
TensorRT Impact on BERT Inference Performance
We deploy CPU BERT BASE and Distill BERT on n1-standard-96, and GPU BERT BASE, Distill BERT and BERT BASE with TRT optimization on n1-standard-4 with 1 T4 GPU, with sequence length of the BERT model being 384 token. We measure the latency and throughput with a concurrency sweep with Triton's performance analyzer. The latency includes Istio ingress/load balancing and reflects the true end to end cost in the same GCP zone.
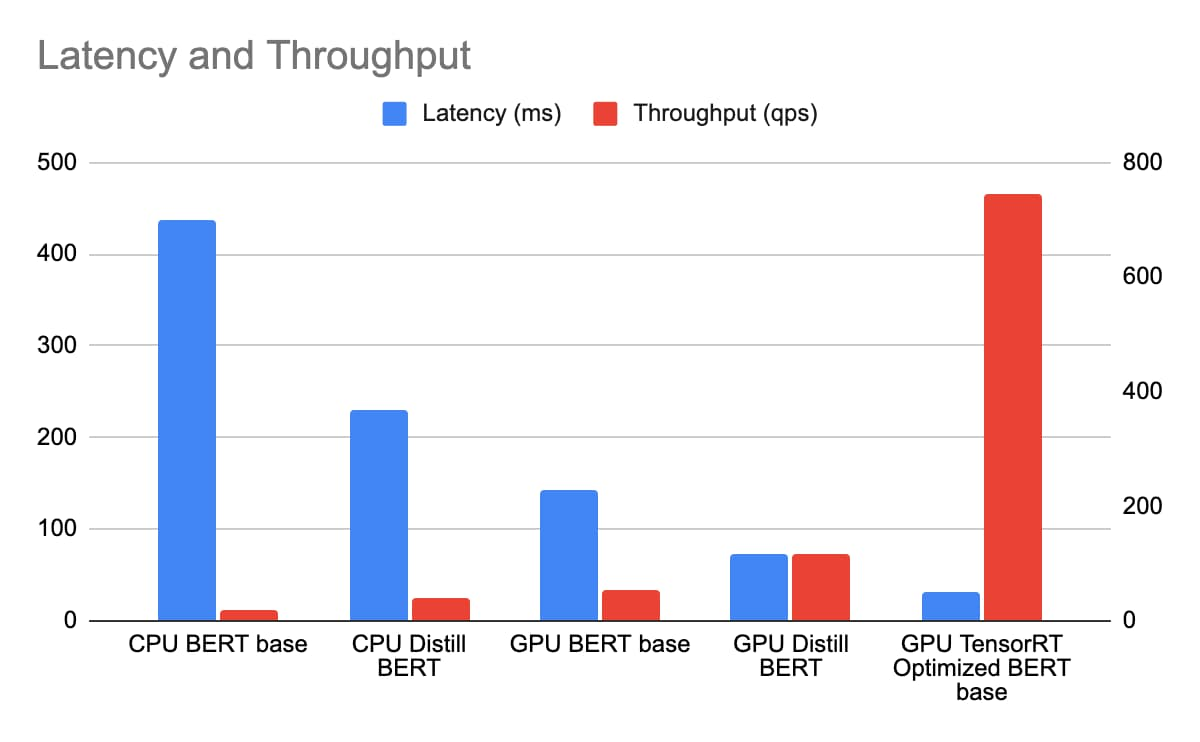
With n1-standard-96 priced at $4.56/hr and n1-standard-4 at $0.19/hr and T4 at $0.35/hr totaling $0.54/hr. While achieving a much lower latency, the TCO of BERT inference with TensorRT on T4 is over 163 times that of Distill BERT inference on n1-standard-96.
Conclusion
NVIDIA Triton Inference Server, running on GKE with GPU and TensorRT, provides a cost-effective and high-performance foundation to build an enterprise-scale, shared-service ML inference platform. We also introduced the One-Click Triton Inference Server solution to help jumpstart ML inference projects. Finally, we provided a few recommendations that will help you get a GPU-enabled inference project off the ground:
Use TensorRT to optimize Deep Learning model inference performance.
Leverage concurrent serving and dynamic batching features in Triton.
To take full advantage of the newer GPUs, use FP16 or INT8 precision for the TensorRT models.
Use Model Priority to ensure latency SLO compliance for Tier-1 models.
References
- Cheaper Cloud AI deployments with NVIDIA T4 GPU price cut
- Efficiently scale ML and other compute workloads on NVIDIA’s T4 GPU, now generally available
- New Compute Engine A2 VMs—first NVIDIA Ampere A100 GPUs in the cloud
- Turbocharge workloads with new multi-instance NVIDIA GPUs on GKE
- Mitigating transient load effects on ML serving latency
Acknowledgements: David Goodwin, Principal Software Engineer, NVIDIA; Mahan Salehi, Triton Product Manager, NVIDIA; Jill Milton, Senior Account Manager, NVIDIA; Dinesh Mudrakola, Technical Solution Consultant, GCP and GKE Marketplace Team


