Inside Capacitor, BigQuery’s next-generation columnar storage format
Mosha Pasumansky
Dremel / BigQuery Technical Lead
The “BigQuery under the hood” blog post gave an overview of different BigQuery subsystems. Today, we'll take a deeper dive into one of them — the storage system. We'll follow data as it's loaded into a BigQuery table.BigQuery supports several input formats — CSV, JSON, Datastore backups, AVRO — and when they're imported, data is converted into our internal representation. BigQuery uses a columnar storage that supports semistructured data — nested and repeated fields. When Google published the Dremel paper in 2010, it explained how this structure is preserved within column store. Every column, in addition to its value, also stores two numbers — definition and repetition levels. This encoding ensures that the full or partial structure of the record can be reconstructed by reading only requested columns, and never requires reading parent columns (which is the case with alternative encodings). That same paper gives an exact algorithm for both encoding the data and reconstructing the record.
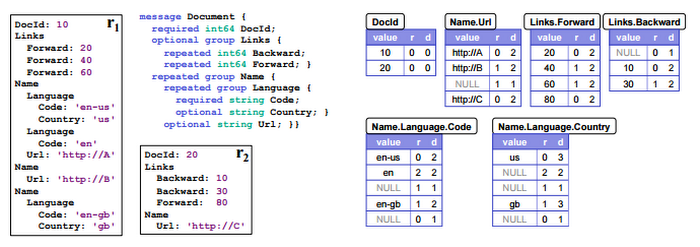
Example of encoding semistructured data using definition and repetition levels
The definition and repetition levels encoding is so efficient for semistructured data that other open source columnar formats, such as Parquet, also adopted this technique. In addition to helping with storing and building structured records, definition and repetition levels can also be used in algorithms for efficient query processing.
In 2014, Google published another paper — Storing and Querying tree-structured records in Dremel — which lays theoretical foundation and proves correctness of algorithms for filtering and aggregation operators, which take advantage of the above encoding.
Now that we understand how the record structure is implemented, what about the actual values? In the last 10 years, there's been a resurgence of research in column oriented database systems. One of the classic papers in this area — Integrating Compression and Execution in Column-Oriented Database Systems — describes various techniques and encodings, such as Run Length Encoding (RLE), Dictionary encoding, Bit-Vector encoding, Frame of Reference encoding, etc. The paper discusses various tradeoffs and algorithms that can be used with these different encodings.
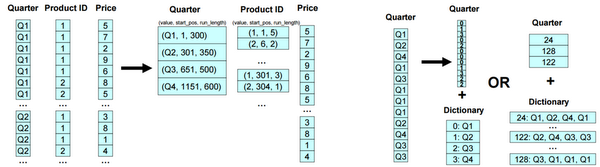
Example of Run Length Encoding (left) and Dictionary Encoding (right). Taken from VLDB 2009 tutorial on Column Oriented Database Systems.
Capacitor — the storage format in BigQuery, builds heavily on this research and employs variations and advancements of these techniques. To show one example where Capacitor advances the state of the art, we'll review the problem of reordering of input rows. This is one of the less studied problems in research (see this paper for some background). To illustrate the problem, let’s consider the following example of input with 3 columns:
If we were to encode these data with RLE, it would not be very optimal, since in every column every value doesn’t repeat more than once, so all the run lengths would be 1, and we'll end up with total of 21 runs.
However, if the input rows are reshuffled into following:
we'll be able to take great advantage of RLE, and will end up with a total of 9 runs. This permutation is the optimal solution for the given input, and it produces better results than lexicographical sort by any combination of columns. Unfortunately, finding the optimal solution is known to be a NP-complete problem in computer science, which means that finding the optimal solution is not practical, even for a modest number of input rows, let alone for millions and billions of rows of typical input to BigQuery. To further complicate matters, we should notice that not all columns are born equal. Some might be very long strings, where shorter RLE runs are more beneficial than longer runs on the small integers column. Finally, we must take into account actual usage: some columns are more likely to be selected in queries than others, and some columns are more likely to be used as filters, for example in WHERE clauses. Capacitor builds an approximation model that takes into account all relevant factors and comes up with a reasonable solution. The runtime of evaluating this model is bound, since we wouldn’t want data import to BigQuery to take forever!
While every column is being encoded, Capacitor and BigQuery collect various statistics about the data — these statistics are persisted and later are used during query execution — they both feed into query planner to help compiling optimal plans, and into the dynamic runtime to choose most efficient runtime algorithms for required operators.
Once all column data is encoded, it's written to Google’s distributed file system — Colossus. More decisions must be made at this time, the most important one being how to shard the input data. A shard is a unit of processing at query time. We don’t want too few shards, because we would like to take advantage of distributed processing capabilities of BigQuery, processing a table in parallel using potentially thousands of machines — each one reading individual shards. But we also don’t want too many shards, because every unit of storage and processing has constant overhead. Future query patterns influence the sharding strategy as well. Queries that will read lots of columns may benefit from smaller shards, but queries that read only few might be better of with larger shards. Again, BigQuery has a model that evaluates all of the different factors, and comes up with an ideal number of shards.
When data is sent to Colossus for permanent storage, all of it is encrypted. There are many levels of defense against unauthorized access in Google Cloud Platform, and 100% of data being encrypted at rest is one of them.
Colossus is a reliable and fault tolerant file system, leveraging techniques such as Reed Solomon codes to ensure that data is never lost. In addition, immediately upon writing data to Colossus, BigQuery starts the geo-replication process, mirroring all the data into different data centers around the specified jurisdiction, be it US or EU. Having data in multiple data centers enables the highest availability, in case one data center is temporarily unavailable, and also helps query load balancing.
For Cloud Platform users, all this encoding, encryption and replication are already included in the price of BigQuery storage!
It doesn’t end here. BigQuery has background processes that constantly look at all the stored data and check if it can be optimized even further. Perhaps initially data was loaded in small chunks, and without seeing all the data, some decisions were not globally optimal. Or perhaps some parameters of the system have changed, and there are new opportunities for storage restructuring. Or perhaps, Capacitor models got more trained and tuned, and it possible to enhance existing data. Whatever the case might be, when the system detects an opportunity to improve storage, it kickstarts data conversion tasks. These tasks do not compete with queries for resources, they run completely in parallel, and don’t degrade query performance. Once the new, optimized storage is complete, it atomically replaces old storage data — without interfering with running queries. Old data will be garbage-collected later.
BigQuery performs all this maintenance behind the scenes, and it's completely invisible to you, and free of charge, both money and performance. BigQuery is a true NoOps service — it lets you focus on solving your business problems, and takes care of managing the rest for you!



