How Snap reduced latency by 96 percent with KeyDB database on Google Cloud
Ilya Zelker
Strategic Cloud Engineer
Ian McKee
Strategic Cloud Engineer
Modern applications are often highly distributed, with microservices and APIs running across many environments, including multiple clouds. This approach offers many benefits, such as resilience, scalability, and faster team velocity. However, this approach can also introduce latency concerns. In this blog, we highlight how Google Cloud Consulting (GCC) and Snap collaborated to reduce latency by 96% for Snap’s “User Service” microservice, finally allowing them to perform data analysis of their multi-cloud estate with acceptable performance.
Solution
Snap has a multicloud architecture, with operational database workloads in both AWS and Google Cloud, leveraging services including AWS DynamoDB as well as Google Cloud Spanner, Firestore and Bigtable. In this particular case they had the operational database in AWS (DynamoDB) and an analytical database (BigQuery) in Google Cloud. However, latency between the two systems was unacceptably high.
To help, Snap decided to supplement its User Service, a microservice that provides an interface for retrieving user data, with a User Service hosted in Google Kubernetes Engine (GKE), and a KeyDB cache, an in-memory, open-source, and fast alternative to Redis, owned by Snap.
KeyDB, hosted in Google Cloud, caches frequently requested data to avoid repetitive cross-cloud calls and minimize latency. Before implementing KeyDB, the average P99 latency between Google Cloud us-central1 region and AWS us-east-1 region was between 49-133ms. With KeyDB in Google Cloud, every cache hit resulted in a tiny fraction of the original latency — between 1.56-2.11ms. The non-cached data is stored in the Dynamo database.
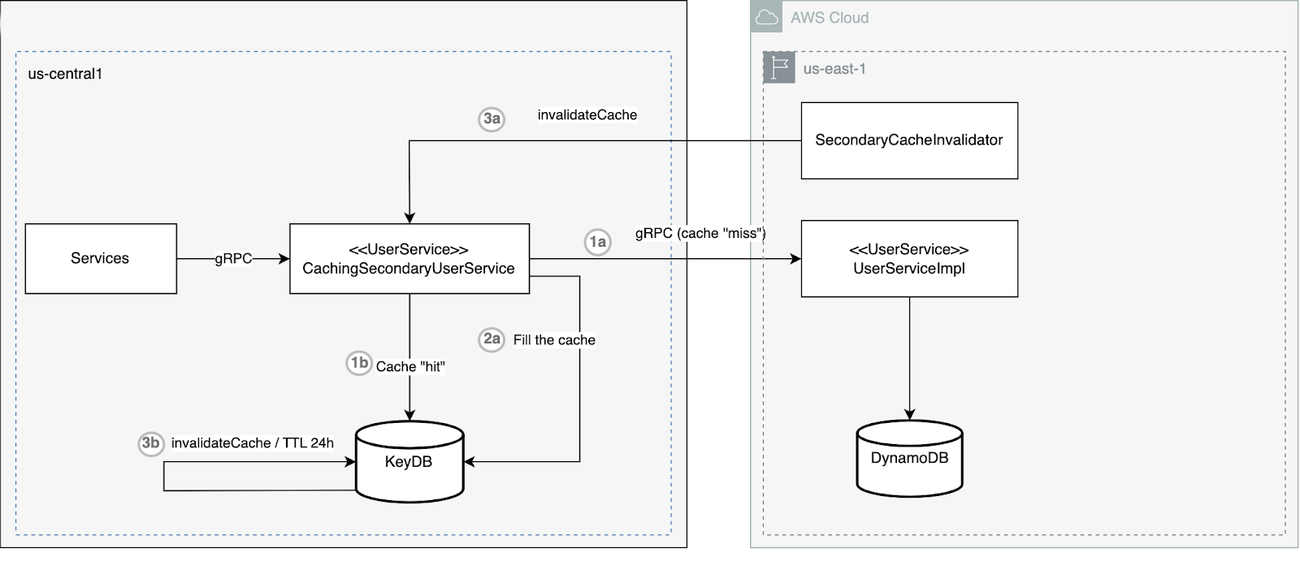
The proposed multi-cloud architecture
Data retrieval flow step by step
Below is the description of the data retrieval flow.
- Client services deployed on Google Cloud in the us-central1 region call the User Service, also deployed in the us-central1 region. The specific Google Cloud user service implementation shown on the diagram is a CachingSecondaryUserService.
- The CachingSecondaryUserService attempts to retrieve data from the KeyDB cache. KeyDB is also deployed in the us-central1 Google Cloud region on another GKE cluster. While the data for some users may exist in the cache, resulting in a cache hit (1b), data for other users may be missing, resulting in a cache miss. The missing data is retrieved from User Service implementation deployed in the us-east-1 AWS region (see path 1a).
- On retrieval, CachingSecondaryUserService backfills the cache (2a). That way subsequent requests can “hit” the cache, reducing cross-cloud latency.
The cache is invalidated using two methods:
- Cache in the KeyDB is invalidated by the TTL settings for the KeyDB every 24 hours (3b)
- Using the SecondaryServiceCacheInvalidator that is triggered when data needs to be updated, e.g., when data is written to the Dynamo database using other services (3a)
Results
Below is the screenshot from Snap’s Grafana monitoring tool that shows latency for the cache “hit” path for one of the data points.
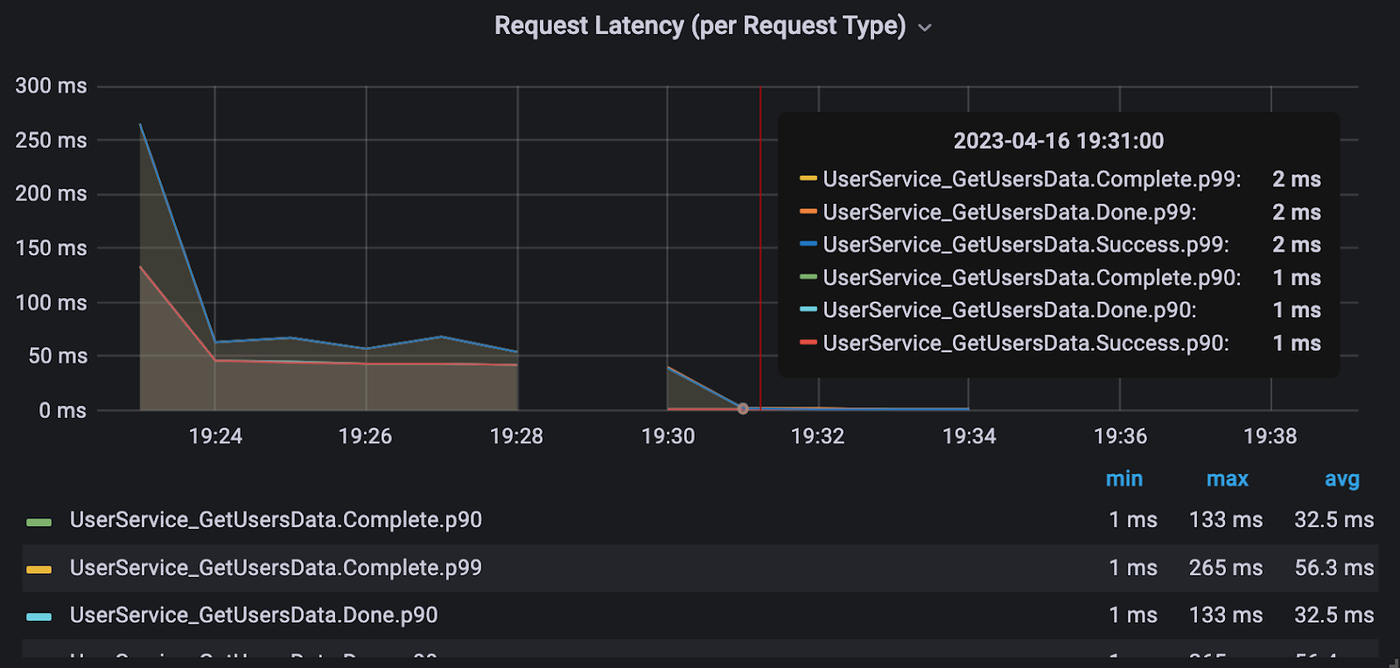
To the left of the Grafana screenshot, you can see that the retrieval latency prior to introducing the KeyDB caching solution averages just below 50ms. At 19:30 the caching solution is implemented, with the first call filling the cache, and every subsequent call retrieving from the cache on a cache hit. Below is the table summarizing results:

“Partnering with Google to integrate KeyDB caching within Google Cloud has opened the doors for future products and teams to deploy to Google Cloud with drastically reduced latency concerns,” said Vinay Kola, Software Engineering Manager, Snap. “This solution has provided us the ability to maintain a cloud-agnostic presence, as well as introduce new applications to Google Cloud that were previously unable or bottlenecked due to latency or reliability concerns.”
Next steps
By identifying Snap’s business challenges and implementing technical solutions that solve these challenges and support their multi-cloud architecture, we are enabling Snap to grow their data analytics presence on Google Cloud. Indeed, Snap plans to replicate a similar architecture for data access from other Google Cloud regions. For the broader audience, other in-memory databases such as Memorystore or Redis, could be used as a caching storage.
If you're looking for a way to improve the performance of your applications, contact Google Cloud Consulting today. We can help you design, build, and manage your cloud infrastructure, and we have a proven track record of helping businesses of all sizes achieve their goals with Google Cloud.
Special thanks to Paul Valencia, Technical Account Manager, for his contributions to this blog post.



