Your ML workloads cheaper and faster with the latest GPUs
Daniel Walter
Cloud ML Site Reliability Engineer, Google
Gonzalo Gasca Meza
Developer Programs Engineer, Google
Running ML workloads more cost effectively
Google Cloud wants to help you run your ML workloads as efficiently as possible. To do this, we offer many options for accelerating ML training and prediction, including many types of NVIDIA GPUs. This flexibility is designed to let you get the right tradeoff between cost and throughput during training or cost and latency for prediction.
We recently reduced the price of NVIDIA T4 GPUs, making AI acceleration even more affordable. In this post, we’ll revisit some of the features of recent generation GPUs, like the NVIDIA T4, V100, and P100. We’ll also touch on native 16-bit (half-precision) arithmetics and Tensor Cores, both of which provide significant performance boosts and cost savings. We’ll show you how to use these features, and how the performance benefit of using 16-bit and automatic mixed precision for training often outweighs the higher list price of NVIDIA’s newer GPUs.
Half-precision (16-bit float)
Half-precision floating point format (FP16) uses 16 bits, compared to 32 bits for single precision (FP32). Storing FP16 data reduces the neural network’s memory usage, which allows for training and deployment of larger networks, and faster data transfers than FP32 and FP64.

Execution time of ML workloads can be sensitive to memory and/or arithmetic bandwidth. Half-precision halves the number of bytes accessed, reducing the time spent in memory-limited layers. Lowering the required memory lets you train larger models or train with larger mini-batches.
The FP16 format is not new to GPUs. In fact, it has been supported as a storage format for many years on NVIDIA GPUs: High performance FP16 is supported at full speed on NVIDIA T4, NVIDIA V100, and P100 GPUs. 16-bit precision is a great option for running inference applications, however if you’re training a neural network entirely at this precision, the network may not converge to required accuracy levels without higher precision result accumulation.
Automatic mixed precision mode in TensorFlow
Mixed precision uses both FP16 and FP32 data types when training a model. Mixed-precision training offers significant computational speedup by performing operations in half-precision format whenever it’s safe to do so, while storing minimal information in single precision to retain as much information as possible in critical parts of the network. Mixed-precision training usually achieves the same accuracy as single-precision training using the same hyper-parameters.
NVIDIA T4 and NVIDIA V100 GPUs incorporate Tensor Cores, which accelerate certain types of FP16 matrix math, enabling faster and easier mixed-precision computation. NVIDIA has also added automatic mixed-precision capabilities to TensorFlow.
To use Tensor Cores, FP32 models need to be converted to use a mix of FP32 and FP16. Performing arithmetic operations in FP16 takes advantage of the performance gains of using lower-precision hardware (such as Tensor Cores). Due to the smaller representable range of float16, though, performing the entire training with FP16 tensors can result in gradient underflow and overflow errors. However, performing only certain arithmetic operations in FP16 results in performance gains when using compatible hardware accelerators, decreasing training time and reducing memory usage, typically without sacrificing model performance.
TensorFlow supports FP16 storage and Tensor Core math. Models that contain convolutions or matrix multiplication using the tf.float16 data type will automatically take advantage of Tensor Core hardware whenever possible.
This process can be configured automatically using automatic mixed precision (AMP). This feature is available in V100 and T4 GPUs, and TensorFlow version 1.14 and newer supports AMP natively. Let’s see how to enable it.
Manually: Enable automatic mixed precision via TensorFlow API
Wrap your tf.train or tf.keras.optimizers Optimizer as follows:
This change applies automatic loss scaling to your model and enables automatic casting to half precision.
(Note: To enable mixed precision in a for TensorFlow 2 Keras you can use: tf.keras.mixed_precision.Policy.)
Automatically: Enable automatic mixed precision via an environment variable
When using the NVIDIA NGC TF Docker image, simply set one environment variable:
As an alternative, the environment variable can be set inside the TensorFlow Python script:
(Note: For a complete AMP example showing the speed-up on training an image classification task on CIFAR10, check out this notebook.)
Please take a look at the Models that have been tested successfully using mixed-precision.
Configure AI Platform to use accelerators
If you want to start taking advantage of the newer NVIDIA GPUs like the T4, V100, or P100 you need to use the customization options: Define a config.yaml file that describes the GPU options you want. The structure of the YAML file represents the Job resource.
The first example shows a configuration file for a training job that uses Compute Engine machine types with a T4 GPU.
(Note: For a P100 or V100 GPU, configuration is similar, just replace type with the correct GPU type—NVIDIA_TESLA_P100 or NVIDIA_TESLA_V100.)
Use the gcloud* command to submit the job, including a --config argument pointing to your config.yaml file. This example assumes you've set up environment variables—indicated by a $ sign followed by capital letters—for the values of some arguments:
The following example shows how to submit a job with a similar configuration (using Compute Engine machine types with GPUs attached), but without using a config.yaml file:
(Note: Please verify you are running the latest Google Cloud SDK to get access to the different machine types.)
Hidden cost of low-priced instances
The conventional practice most organizations follow is to select lower-priced cloud instances to save on per-hour compute cost. However, the performance improvements of newer GPUs can significantly reduce costs for running compute-intensive workloads like AI.
To validate the concept that modern GPUs reduce the total cost of some common training workloads, we trained Google’s Neural Machine Translation (GNMT) model—which is used for applications like real-time language translations—on several GPUs. In this particular example we tested the GNMTv2 model using AI Platform Training using Custom Containers. By simply using modern hardware like a T4, we are able to train the model at 7% of the cost while obtaining the result eight times faster, as shown in the table below. (For details about the setup please take a look at the NVIDIA site.)
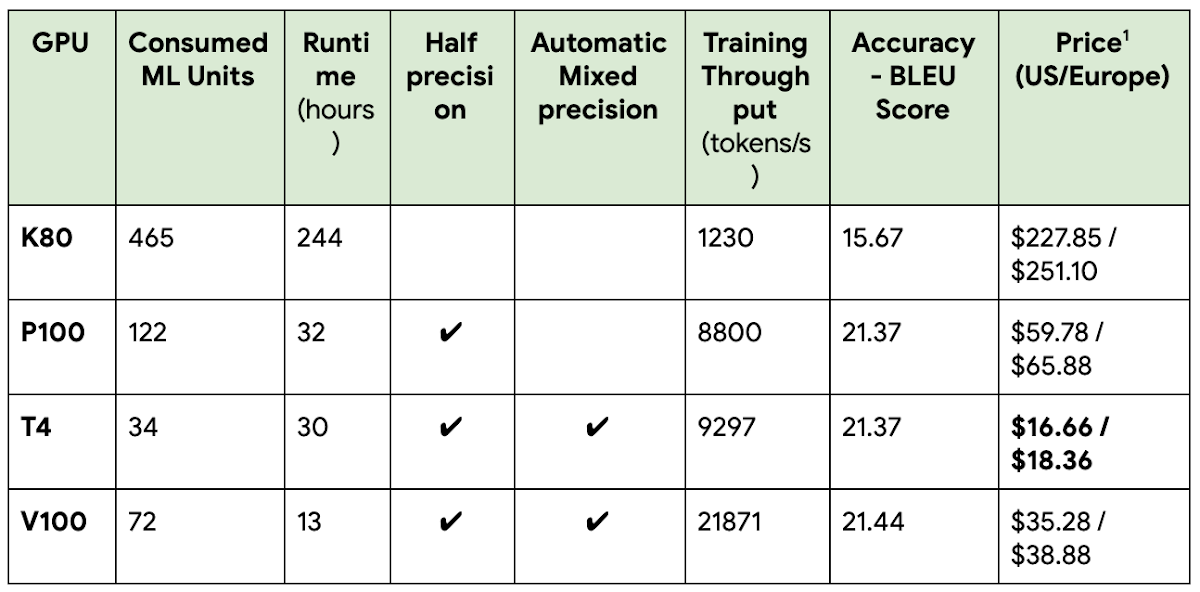
Each GPU Model was tested using three different runs and calculating the average numbers per section.
Additional costs for storing data (GNMT input data was stored on GCS) are not included, since they are the same for all tests.
A quick note: When calculating the cost of a training job using Consumed ML units use the following formula:
The cost of a training job in all available Americas regions is $0.49 per hour, per Consumed ML units.
The cost of a training job in all available Europe regions and Asia Pacific regions is $0.54 per hour, per Consumed ML units.
In this case to calculate the cost for running the job in the K80 use the Consumed ML units * $0.49 formula: 465 * $0.49 = $227.85.
The Consumed ML units can be found on your Job details page (see below), and are equivalent to training units with the duration of the job factored in:
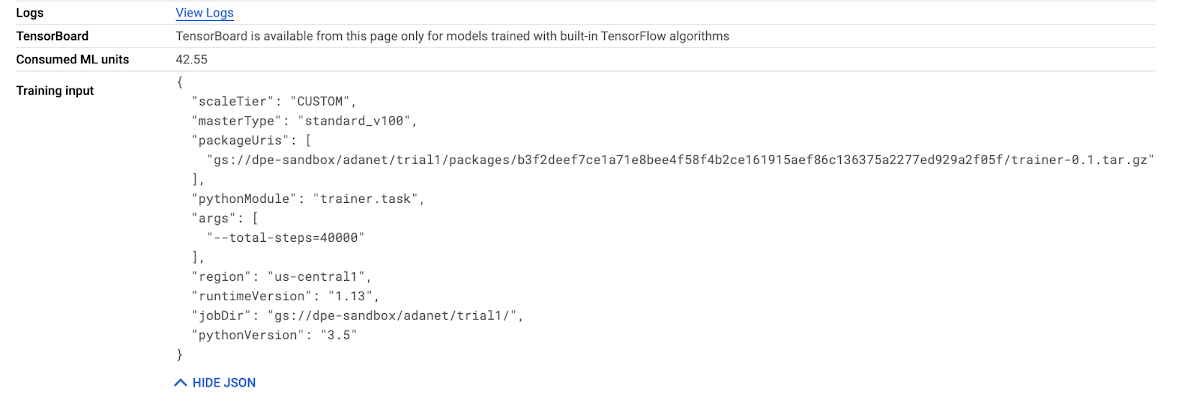
Looking at the specific NVIDIA GPUs, we can get more granular on the performance-price proposition.
NVIDIA T4 is well known for its low power consumption and great Inference performance for Image/Video Recognition, Natural Language Processing, and Recommendation Engines, just to name a few use cases. It supports half-precision (16-bit float) and automatic mixed precision for model training and gives a 8.1x speed boost over K80 at only 7% of the original cost.
NVIDIA P100 introduced half-precision (16-bit float) arithmetic. Using it gives a 7.6x performance boost over K80, at 27% of the original cost.
NVIDIA V100 introduced tensor cores that accelerate half-precision and automatic mixed precision. It provides an 18.7x speed boost over K80 at only 15% of the original cost. In terms of time savings, the time to solution (TTS) was reduced from 244 hours (about 10 days) to just 13 hours (an overnight run).
What about model prediction?
GPUs can also drastically lower latency for online prediction (inference). However, the high availability demands of online prediction often requires keeping machines alive 24/7 and provisioning sufficient capacity in case of failures or traffic spikes. This can potentially make low latency online prediction expensive.
The latest price cuts to T4s, however, make low latency, high availability serving more affordable on the Google Cloud AI Platform. You can deploy your model on a T4 for about the same price as eight vCPUs, but with the low latency and high-throughput of a GPU.
The following example shows how to deploy a TensorFlow model for Prediction using 1 NVIDIA T4 GPU:
Conclusion
Model training and serving on GPUs has never been more affordable. Price reductions, mixed precision, and Tensor Cores accelerate AI performance for training and prediction when compared to older GPUs such as K80s. As a result, you can complete your workloads much faster, saving both time and money. To leverage these capabilities and reduce your costs, we recommend the following rules of thumb:
If your training job is short lived (under 20 minutes), use T4, since they are the cheapest per hour.
If your model is relatively simple (fewer layers, smaller number of parameters, etc.), use T4, since they are the cheapest per hour.
If you want the fastest possible runtime and have enough work to keep the GPU busy, use V100.
To take full advantage of the newer NVIDIA GPUs use 16-bit precision in P100 and enable mixed precision mode when using T4 and V100.
If you haven't explored GPUs for model prediction or inference, take a look at our GPUs on Compute Engine page for more details. For more information on getting started, check out our blog post on the topic.
References
Acknowledgements: Special thanks to the following people who contributed to this post:
NVIDIA: Alexander Tsado, Cloud Product Marketing Manager
Google: Henry Tappen, Product Manager; Robbie Haertel, Software Engineer; Viesturs Zarins, Software Engineer
1. Price is calculated as described here. Consumed ML Units * Unit Cost (different per region).



