Why you need to explain machine learning models
Lak Lakshmanan
Director, Analytics & AI Solutions
Many companies today are actively using AI or have plans to incorporate it into their future strategies — 76% of enterprises are now prioritizing AI and ML over other initiatives in their IT budgets and the global AI industry is expected to reach over $260 billion by 2027. But as AI and advanced analytics become more pervasive, the need for more transparency around how AI technologies work will be paramount.
In this post, we’ll explore why explainable AI (XAI) is essential to widespread AI adoption, common XAI methods, and how Google Cloud can help.
Why you need to explain ML models
AI technology suffers from what we call a black box problem. In other words, you might know the question or the data (the input), but you have no visibility into the steps or processes that provide you with the final answer (the output). This is especially problematic in deep learning and artificial neural network approaches, which contain many hidden layers of nodes that “learn” through pattern recognition.
Stakeholders are often reluctant to trust ML projects because they don’t understand what they do. It’s hard for decision-makers to relinquish control to a mysterious machine learning model, especially when it’s responsible for critical decisions. AI systems are making predictions that have a profound impact, and in some industries like healthcare or driverless cars, it can mean the difference between life and death.
It’s often hard to get support that a model can be trusted to make decisions, let alone make them better than a human can—especially when there is no explanation of how that decision was made. How did the AI model predict or make a decision? How can you be sure there is no bias creeping into algorithms? Is there enough transparency and interpretability to trust the model’s decision?
Decision-makers want to know the reasons behind an AI-based decision, so they have the confidence that it is the right one. In fact, according to a PwC survey, the majority of CEOs (82%) believe that AI-based decisions must be explainable to be trusted.
What is Explainable AI?
Explainable AI (XAI) is a set of tools and frameworks that can be used to help you understand how your machine learning models make decisions. This shouldn’t be confused with showing a complete step-by-step deconstruction of an AI model, which can be close to impossible if you’re attempting to trace the millions of parameters used in deep learning algorithms. Rather, XAI aims to provide insights into how models work, so human experts are able to understand the logic that goes into making a decision.
When you apply XAI successfully, it offers three important benefits:
1. Increases trust in ML models
When decision-makers and other stakeholders have more visibility into how a ML model found its final output, they are more likely to trust AI-based systems. Explainable AI tools can be used to provide clear and understandable explanations of the reasoning that led to the model’s output. Say you are using a deep learning model to analyze medical images like X-rays, you can use explainable AI to produce saliency maps (i.e. heatmaps) that highlight the pixels that were used to get the diagnosis. For instance, a ML model that classifies a fracture would also highlight the pixels used to determine that the patient is suffering from a fracture.
2. Improves overall troubleshooting
Explainability in AI can also enable you to debug a model and troubleshoot how well a model is working. Let’s imagine your model is supposed to be able to identify animals in images. Over time, you notice that the model keeps classifying images of dogs playing in snow as foxes. Explainable AI tools make it easier to figure out why this error keeps occurring. As you look into your explainable AI models that you’re using to show how a prediction is made, you discover that that ML model is using the background of an image to differentiate between dogs and foxes. The model has mistakenly learned that domestic backgrounds are dogs and snow in an image means the image contains a fox.
3. Busts biases and other potential AI potholes
XAI is also useful for identifying sources of bias. For example, you might have a model to identify when cars are making illegal left hand turns. When you are asked to define what the violation is based on in an image, you find out that the model has picked up a bias from the training data. Instead of focusing on cars turning left illegally, it’s looking to see if there is a pothole. This influence could be caused by a skewed dataset that contained a large amount of images taken on poorly maintained roads, or even real-bias, where a ticket might be more likely to be given out in an underfunded area of a city.
Where does explainability fit into the ML lifecycle?
Explainable AI should not be an afterthought that’s done at the end of your ML workflow. Instead, explainability should be integrated and applied every step of the way—from data collection, processing to model training, evaluation, and model serving.
There are a few ways you can work explainability into your ML lifecycle. This could mean using explainable AI to identify data set imbalances, ensure model behavior satisfies specific rules and fairness metrics, or show model behavior both locally and globally. For instance, if a model was trained using synthetic data, you need to ensure it behaves the same when it uses real data. Or, as we discussed above with deep learning models for medical imaging, a common form of explainability is to create heatmaps to identify the pixels used for image classification.
Another tool you might use is sliced evaluations of machine learning model performance. According to our AI principles, you should avoid creating or reinforcing unfair bias. AI algorithms and datasets can often reflect or reinforce unfair biases. If you notice that a model is not performing well for a small minority of cases, it’s important for you to address any fairness concerns.
Sliced evaluations will allow you to explore how different parts of a dataset might be affecting your results. In the case of imaging models, you might explore different images based on factors like poor lighting or over exposure.
We also recommend creating model cards, which can help explain any potential limitations, any trade-offs you have to make for performance, and then, providing a way to test out what the model does.
Explainable AI methods
When we talk about explainable AI methods, it’s important to understand the difference between global and local methods.
A global method is understanding the overall structure of how a model makes a decision.
A local method is understanding how the model made decisions for a single instance.
For instance, a global method might be that you look at a table that includes all the features that were used, ranked by the overall importance they have for making a decision. Feature importance tables are commonly used to explain structured data models to help people understand how specific input variables impact the final output of a model.
But what about explaining how a model makes a decision for an individual prediction or a specific person? This is where local methods come into play.
For the purpose of this post, we’ll cover local methods based on how they can be used for explaining model predictions in image data.
Here are the most common explainable AI local methods:
- Local interpretable model-agnostic explanation (LIME)
- Kernel Shapley additive explanations (KernalSHAP)
- Integrated gradients (IG)
- Explainable explanations through AI (XRAI)
Both LIME and KernalShap break down an image into patches, which are randomly sampled from the prediction to create a number of perturbed (i.e. changed) images. The image will look like the original, but parts of the image have been zeroed out. Perturbed images are then fed to the trained model and asked to make a prediction.
In the example below, the model would be asked: Is this image a frog or not a frog?
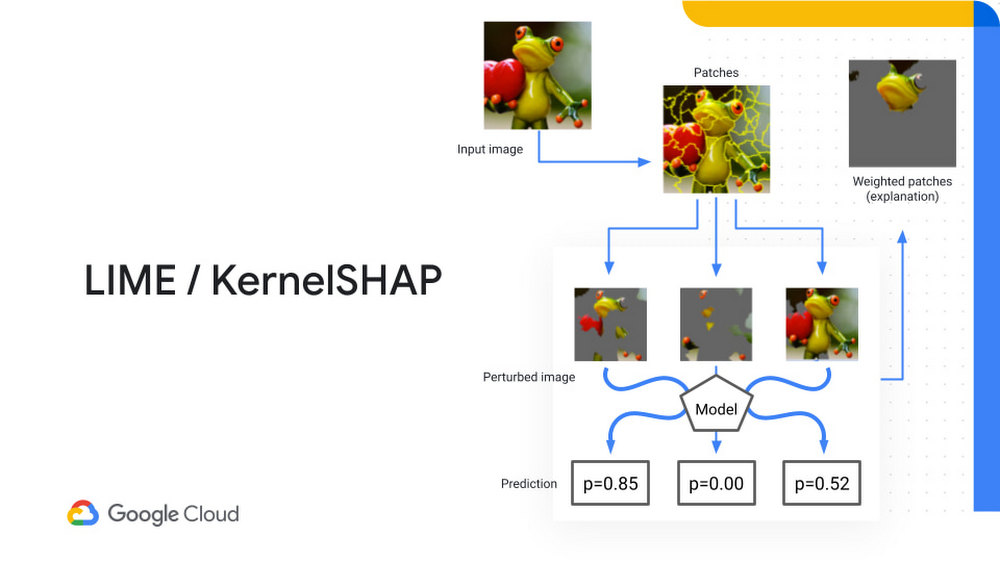
The model would then provide the probability of whether the image is a frog. Based on the patches that were selected, you can actually rank the importance of each patch to the final probability. Both these methods can be used to help explain the local importance for determining whether the image contained a frog.
Integrated gradients is a technique used to give importance value based on gradients of the final output. IG takes baseline images and compares them to the actual pixel value of the images that contain the information the corresponding model is designed to identify. The idea is that the value should improve in accuracy when the image contains what the model was trained to find. It helps determine how much a gradient changes from the baseline image to the point where it makes a prediction, providing an attribution mask that helps determine what the image is using to classify an image.

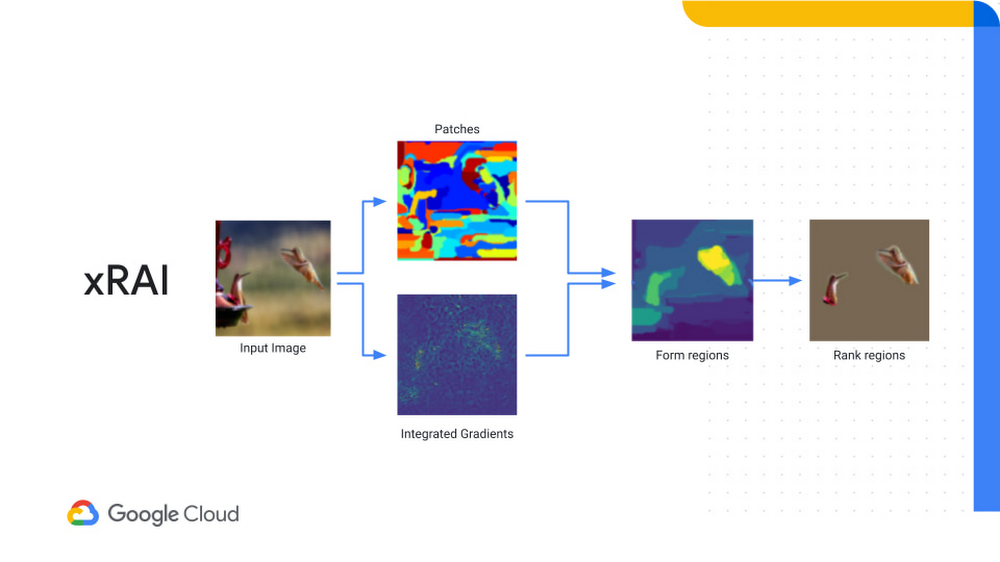
XRAI is a technique that combines all of the three methods mentioned above, combining patch identification with integrated gradients to show salient regions that have the most impact on a decision, rather than individual pixels. The larger regions in this approach tend to deliver better results.
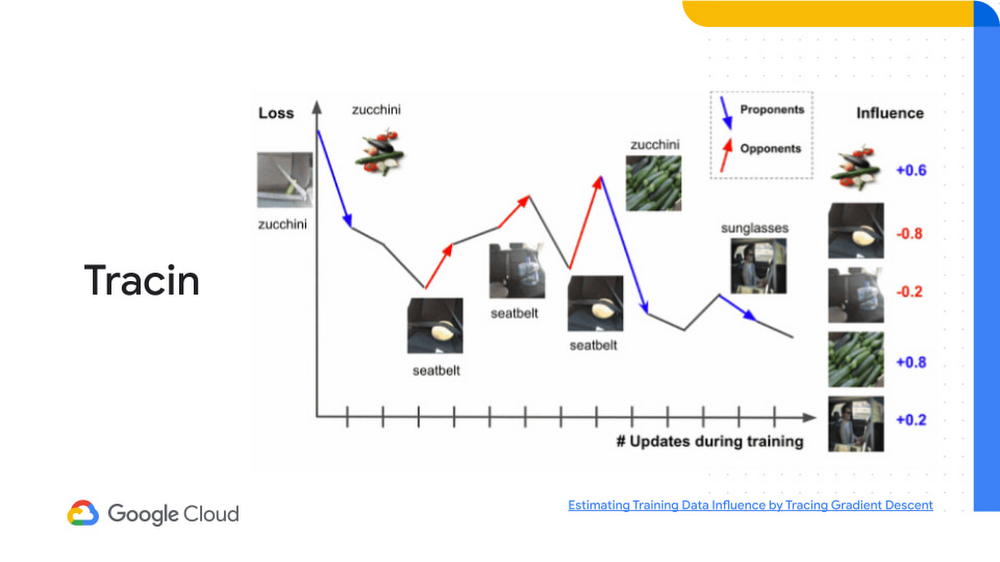
Another emerging method that we’re starting to incorporate at Google Cloud is TracIn—a simple, scalable approach that estimates training data influence. The quality of ML model’s training data can have a huge impact on a model’s performance. TracIn tracks mislabeled examples and outliers from various datasets and helps explain predictions by assigning an influence score to each training example.
If you are training a model to predict whether images have zucchinis, you would look at the gradient changes to determine which reduce loss (proponents) and increase loss (opponents). TracIn allows you to identify what images allow the model to learn to identify a zucchini and which are used to distinguish what’s not a zucchini.
Using Explainable AI in Google Cloud
We launched Vertex Explainable AI to help data scientists not only improve their models but provide insights that make them more accessible for decision-makers. Our aim is to provide a set of helpful tools and frameworks that can help data science teams in a number of ways, such as explaining how ML models reach a conclusion, debugging models, and combating bias.
With Vertex Explainable AI platform, you can:
Design interpretable and inclusive AI. Build AI systems from the ground up with Vertex Explainable AI tools designed to help detect and resolve bias, drift, and other gaps in data and models. With AI Explanations, data scientists can use AutoML Tables, Vertex Predictions, and Notebooks to explain how much a factor contributed to model predictions, helping to improve datasets and model architecture. The What-If Tool enables you to investigate model performance across a wide range of features, optimize strategies, and even manipulate individual datapoint values.
Deploy ML models with confidence by providing human-friendly explanations. When deploying a model on AutoML Tables or Vertex AI , you can reflect patterns found in your training data to get a prediction and a score in real time about how different factors affected the final output.
Streamline model governance with performance monitoring and training. You can easily monitor predictions and provide ground truth labels for prediction inputs with the continuous evaluation feature. Vertex Data Labeling compares predictions with ground truth labels to incorporate feedback and optimize model performance.
AI continues to be an exciting frontier that will continue to shape and inspire the future of enterprises across all industries. But in order for AI to reach its full potential and gain wider adoption, it will require that all stakeholders, not just data scientists, understand how ML models work. That’s why, we remain committed to ensuring that no matter where AI goes in the future, it will serve everyone—be it customers, business users, or decision-makers.
Next steps
Learn how to serve out explanations alongside predictions by running this Jupyter notebook on Cloud AI Platform. Step-by-step instructions are also available on Qwiklabs. And if you are interested in what’s coming in machine learning over the next five years, check out our Applied ML Summit to hear from Spotify, Google, Kaggle, Facebook and other leaders in the machine learning community.




