What is Optical Character Recognition? OCR explained by Google
Jill Daley
Product Manager
Esther Adediran
Product Manager, Google Research
If you have ever used Google Translate to understand a menu while traveling, deposit a check through your bank's mobile app, or search your photo storage for a screenshot, you’ve used Optical Character Recognition (OCR).
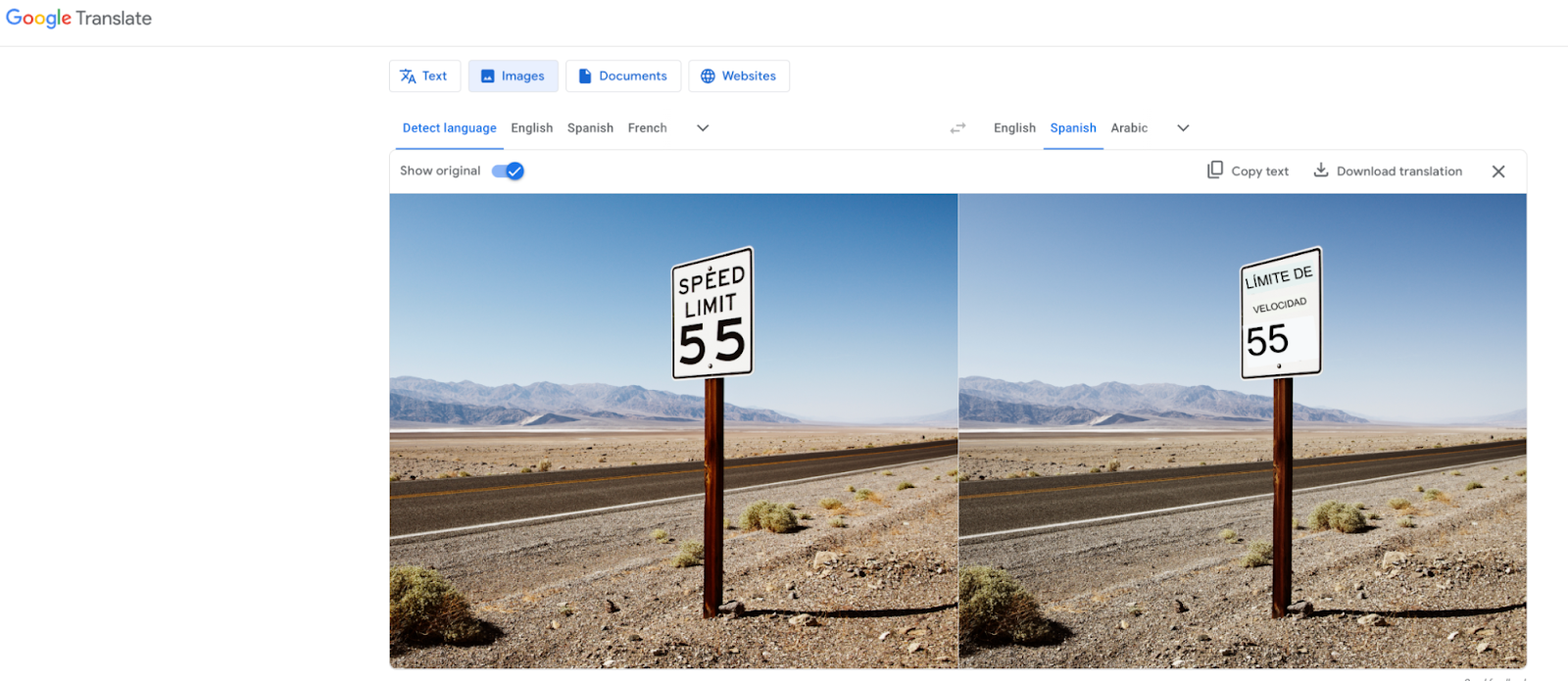
OCR has become the standard way developers extract and utilize text and layout data from PDFs and images. In this blog, we will discuss the history of OCR, where the technology is headed, and how it is more important than ever with the rise of large language models (LLMs).
The progression of OCR systems
Computerized systems for optical character recognition have existed for over 50 years, and the capabilities and technologies empowering these systems have changed dramatically over this time period.
The earliest OCR systems were limited to very narrow domains. For example, in the 1960s, specialized machine-readable fonts such as OCR-A and OCR-B were developed with the purpose of simplifying the task of OCR, enabling customized optical character recognition systems that were capable of reading these typefaces. These OCR-optimized fonts continue to be employed today in bank checks, where fields like the routing number and account number are typically printed using a specific magnetic ink character recognition code.
Over time, OCR systems generalized beyond these font-specific approaches, with Ray Kurzweil often credited as the developer of the first omni-font OCR system in the 1970s. While these systems were capable of recognizing many different typefaces, as opposed to a limited set of OCR-specific fonts, they were limited in their support for the world’s languages.
Three developments in the ensuing decades enabled advances. Approaches pioneered in speech recognition allowed OCR to operate at the phrasal level rather than on individual characters, putting within reach connected scripts like Arabic and cursive handwriting. Second, the development and adoption of The Unicode Standard provided a well-defined and consistent target representation for most of the world’s writing systems. Finally, the adoption of data-driven development allowed improvements in one language without risking regressions in others.
Currently, many OCR systems are capable of recognizing text in hundreds of languages. Most employ a pipeline of task-specific models, which typically includes a model that detects lines of text in images and enables cropped line images to be processed by subsequent stages; one or more classification models that determine the language or script of each line image; and a set of text line recognition models that output the sequence of characters (as Unicode points) in each line image. The earliest multilingual OCR systems adopted a language-specific approach, whereby a specific text line recognition model was trained for each supported language. In some cases, different model architectures were used for different modalities, such as printed versus handwritten text.
Over time, the capabilities of the underlying model architectures advanced, and it became possible for a single recognition model to support multiple languages and even multiple modalities. Script-based OCR approaches became common, with each model supporting multiple languages that shared a common writing system (script). Instead of training separate models for English, French, and Spanish, for example, a single Latin-script recognition model would be trained on multilingual data from all languages that shared this script. This both simplified the OCR pipeline and led to better OCR accuracy by enabling the use of larger recognition models trained on more data.
This progression towards a smaller number of larger, unified, generalized models has continued, following similar trends in other machine learning and artificial intelligence disciplines. Examples include OCR systems that utilize multi-script line recognition models capable of recognizing many scripts, as well as fully end-to-end models that sequentially recognize text in a full image without using an explicit text line detection step. As the number of distinct models in these OCR pipelines has decreased over time, the size and capabilities of the models has increased, fuelling improvements in accuracy and bringing the ultimate goal of universal OCR ever closer.
What sets Google OCR apart
Google Cloud offers two standalone OCR products, Vision API Text Detection and Document AI Enterprise Document OCR, which allow users to perform high-quality extraction across a wide range of languages, advanced features, and an enterprise-ready API. This is in large part due to the close partnership between Google Cloud and Google Research to develop and employ the latest advancements in OCR technology. María Victoria Sasse, Product Fintech Supervisor at Mercado Libre, and user of Google OCR, said this about the importance of secure, high-quality OCR to power their document processing workflows:
At Mercado Crédito, we strive to offer our users customized credit options that best suit their needs. Our integration with Google's OCR capability has provided a user-friendly and secure tool that quickly enables the scrapping of financial documents, improving our credit risk analysis. Together with Google, we continue to work towards democratizing credit access in LATAM.
Vision API Text Detection is Google Cloud’s standard OCR offering. As an enterprise-ready API, Text Detection can globally support high-capacity workloads with low latency for easy integration into business applications for text and layout extraction from images.
Document AI Enterprise OCR is Google Cloud’s OCR specialized for document use cases. With advanced features like image quality scores for more effective downstream processing, language hints to improve text detection, and rotation correction to improve model accuracy, users can go beyond traditional text and layout recognition. In addition, OCR is also used concurrently with Document AI processors to help structure data from documents.
Why OCR is important when building LLM-based applications
The combination of LLMs and OCR marks a significant advancement in data processing and analysis. By leveraging LLMs' contextual understanding and OCR's text and layout extraction capabilities, businesses can unlock valuable insights from data and streamline workflows.
Rich, secure, highly accurate text and layout extraction becomes critical when building applications powered by LLMs. If the model does not have the appropriate textual context from an image or PDF, it will struggle to provide a high-quality response. Ryan Walker, Chief Technology Officer at Casetext, provides a great example of why high-quality OCR is important to the development of successful LLM applications:
As a creator of legal AI solutions—most recently our AI legal assistant, CoCounsel—we build products that must correctly process large, complex collections of legal documents. These might be thousands of pages long, contain images, or be poorly scanned. Missing even a single word can make the difference between winning or losing a case. Google's OCR accurately extracts text from files far better than every other system we've evaluated. Incorporating this technology into our products lets us deliver the highest-quality answers for the lawyers who rely on us, which in turn means they’re able to deliver the best possible service and results for their clients.
How can Google help with OCR
Learn more about how Google Cloud AI and OCR work together and how to get started with the product that is right for you. Click here to learn how you can use Google’s OCR technologies together with our Document AI solutions suite to automate document processing workflows.



