Dataflow and Vertex AI: Scalable and efficient model serving
Barbara Amoros
AI Engineer, Google Cloud Consulting
If you're considering using Vertex AI to train and deploy your models, you're on the right track! Data is essential for machine learning, and the more data a model has and the higher quality it is, the better the model will perform. Before training a model, the data must be preprocessed, which means cleaning, transforming, and aggregating it into a format that the model can understand. Data preprocessing is also important when serving a model, but it can be more complex due to factors such as real-time streaming data, hardware scalability, and incomplete data.
When you're handling large amounts of data, you need a service that's both scalable and reliable. Dataflow fits the bill perfectly, as it can process data in both real-time and batch mode, and it’s ideal for models with high throughput and low latency requirements.
Dataflow and Vertex AI work great together, so keep reading to learn how to use these two powerful services to serve models for streaming prediction requests.
Use Case: Streaming Prediction Requests
Certain applications, such as anomaly detection in sensor data and predictive maintenance for industrial equipment, demand real-time predictions from machine learning models. Surprisingly, implementing real-time prediction systems doesn't require an overly complex setup. If your machine learning model needs to make predictions on real-time data, a straightforward approach involves utilizing a Pub/Sub topic to capture real-time data, a Dataflow pipeline to preprocess and transform the data, and a Vertex AI endpoint to execute the machine learning model and generate predictions. Additionally, you can enable model monitoring to track any data or model changes that could impact prediction accuracy. The following diagram illustrates the workflow of this solution:
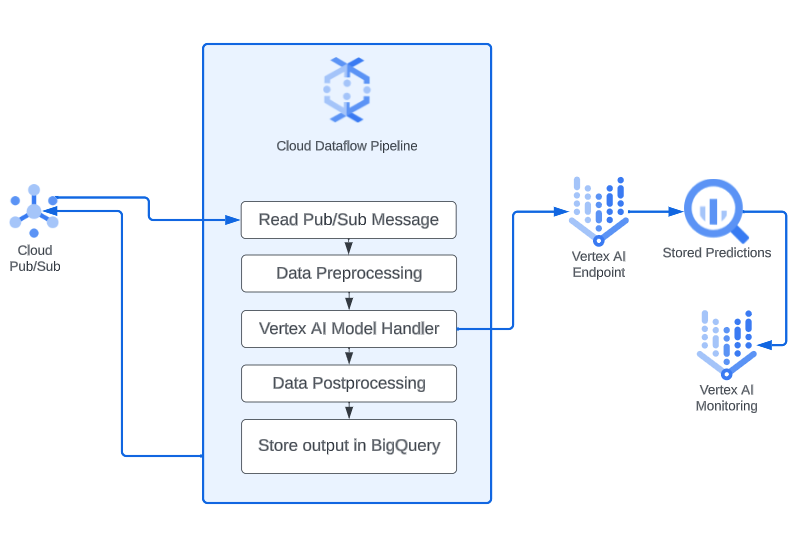
Deploy Model to Vertex AI Endpoint
First, we will need a trained model stored in Vertex AI Model Registry before the serving solution can be implemented. This can be done by either training a model in Vertex AI or importing a pre-trained model.
Now, with just a few clicks (or API calls), you can deploy your model to an endpoint in Vertex AI, so it can serve online predictions. You can enable model monitoring without writing any additional custom code, which helps ensure that there is no skew between the training and serving data.
Instead of deploying the model to an endpoint, you can use the RunInference API to serve machine learning models in your Apache Beam pipeline. This approach has several advantages, including flexibility and portability. However, deploying the model in Vertex AI offers many additional benefits, such as the platform's built-in tools for model monitoring, TensorBoard, and model registry governance.
Vertex AI also provides the ability to use Optimized TensorFlow runtime in your endpoints. To do this, simply specify the TensorFlow runtime container when you deploy your model.
The Optimized TensorFlow runtime is a runtime that can improve the performance and cost of TensorFlow models. You can learn more about how to use it to speed up model inference here. This blog post contains benchmark data that shows how well it performs.
Data Processing Dataflow Pipeline
Apache Beam has built-in support for sending requests to a remotely deployed Vertex AI endpoint by using the VertexAIModelHandlerJSON class. With just a couple of lines of code, we can send the preprocessed message for inference.
Now, we’ll use Dataflow for the data preprocessing part. Below, you can find a code snippet of a python Apache Beam Pipeline which
1. Reads messages from Pub/Sub
2. Preprocesses the message. This can include the following:
a. Cleaning the data
b. Handling missing values
c. Encoding categorical data
d. Feature scaling
3. Sends a prediction request to the Vertex AI endpoint using the Vertex AI model handler
4. Processes the output. In this instance, we transform the raw output of the model into a format that is easily interpretable.
5. Write to BigQuery. Store the output in BigQuery so it can be easily retrieved.
What’s next?
The Apache Beam pipeline can be easily converted into a Flex Template, which allows multiple teams in the same company with similar use cases to reuse it. You can read more about flex templates here. Also, the Dataflow streaming pipeline can be run as one step of a Vertex AI Pipeline (take a look at some of the pre-built components).
In conclusion, Dataflow + Vertex AI is a powerful combination for serving machine learning models for both batch and streaming prediction requests. Dataflow can process data in both real-time and batch mode, and it's ideal for use cases that require high throughput and low latency. Vertex AI provides a platform for deploying and managing models, and it also offers many additional benefits, such as built-in tools for model monitoring, the ability to leverage the Optimized Tensorflow Runtime, and Model Registry.
To learn more about how to use Dataflow and Vertex AI to serve machine learning models, please visit the following resource for detailed code samples: Apache Beam RunInference with Vertex AI.
Ready to discuss your cloud needs? Learn how Google Cloud Consulting can help you implement an end-to-end solution. Visit cloud.google.com/consulting.



