Optimize PyTorch training performance with Reduction Server on Vertex AI
Nikita Namjoshi
Developer Advocate
Eric Dong
Developer Programs Engineer
As deep learning models become increasingly complex and datasets larger, distributed training is all but a necessity. Faster training makes for faster iteration to reach your modeling goals. But distributed training comes with its own set of challenges.
On top of deciding what kind of distribution strategy you want to use and making changes to your training code, you need a way to manage infrastructure, optimize usage of your accelerators, and deal with limited bandwidth between nodes. This added complexity can slow your progress.
In this post, we’ll show you how to speed up training of a PyTorch + Hugging Face model using Reduction Server, a Vertex AI feature that optimizes bandwidth and latency of multi-node distributed training on NVIDIA GPUs for synchronous data parallel algorithms.
Overview of Distributed Data Parallel
Before diving into the details of Reduction Server and how to submit jobs on the Vertex AI training service, it’s useful to understand the basics of distributed data parallelism. Data parallelism is just one way of performing distributed training and can be used when you have multiple accelerators on a single machine, or multiple machines each with multiple accelerators.
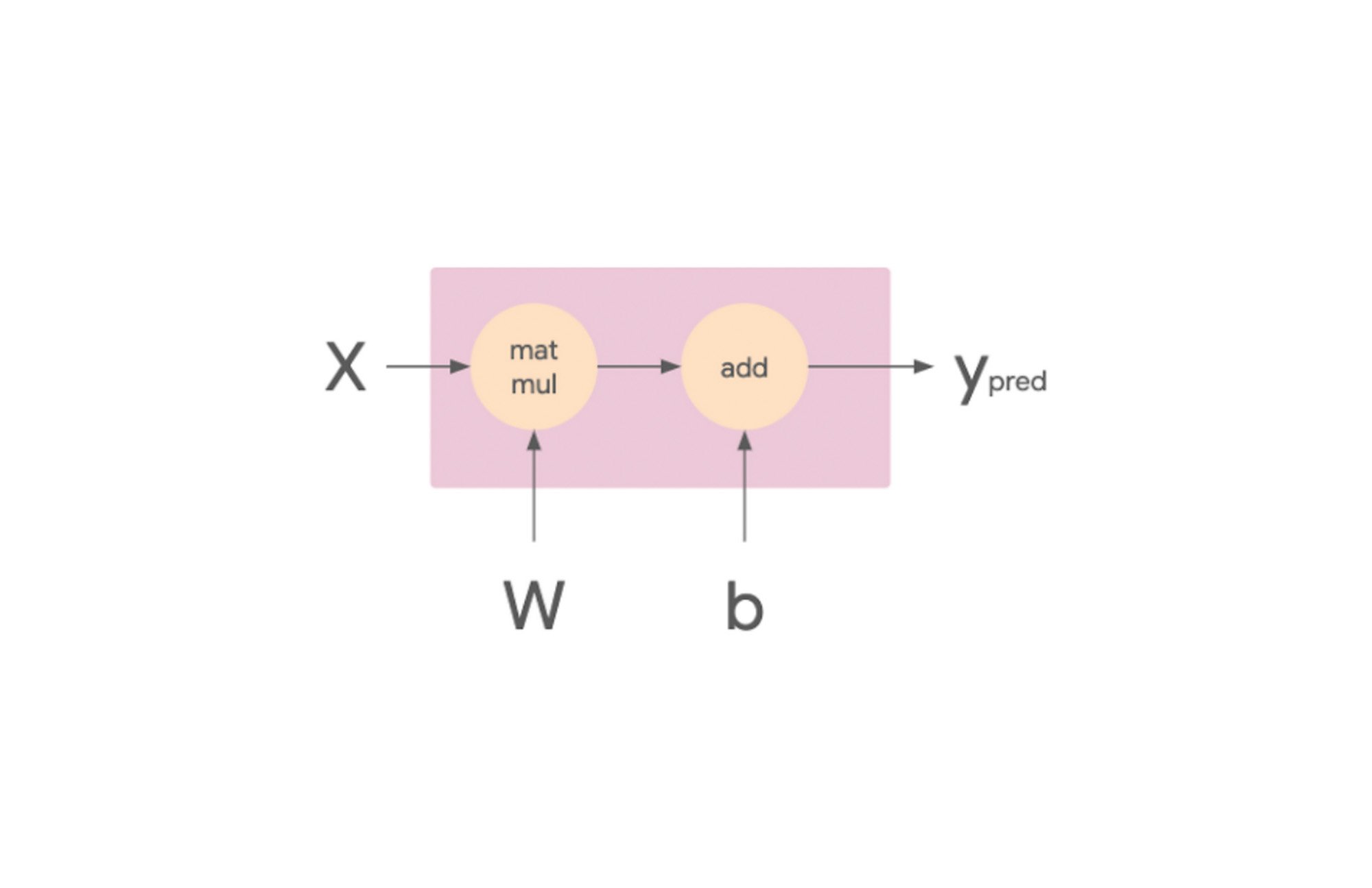
To get an understanding of how data parallelism works, let’s start with a linear model. We can think of this model in terms of its computational graph. In the image below, the matmul op takes in the X and W tensors, which are the training batch and weights respectively. The resulting tensor is then passed to the add op with the tensor b, which is the model’s bias terms. The result of this op is Ypred, which is the model’s predictions.
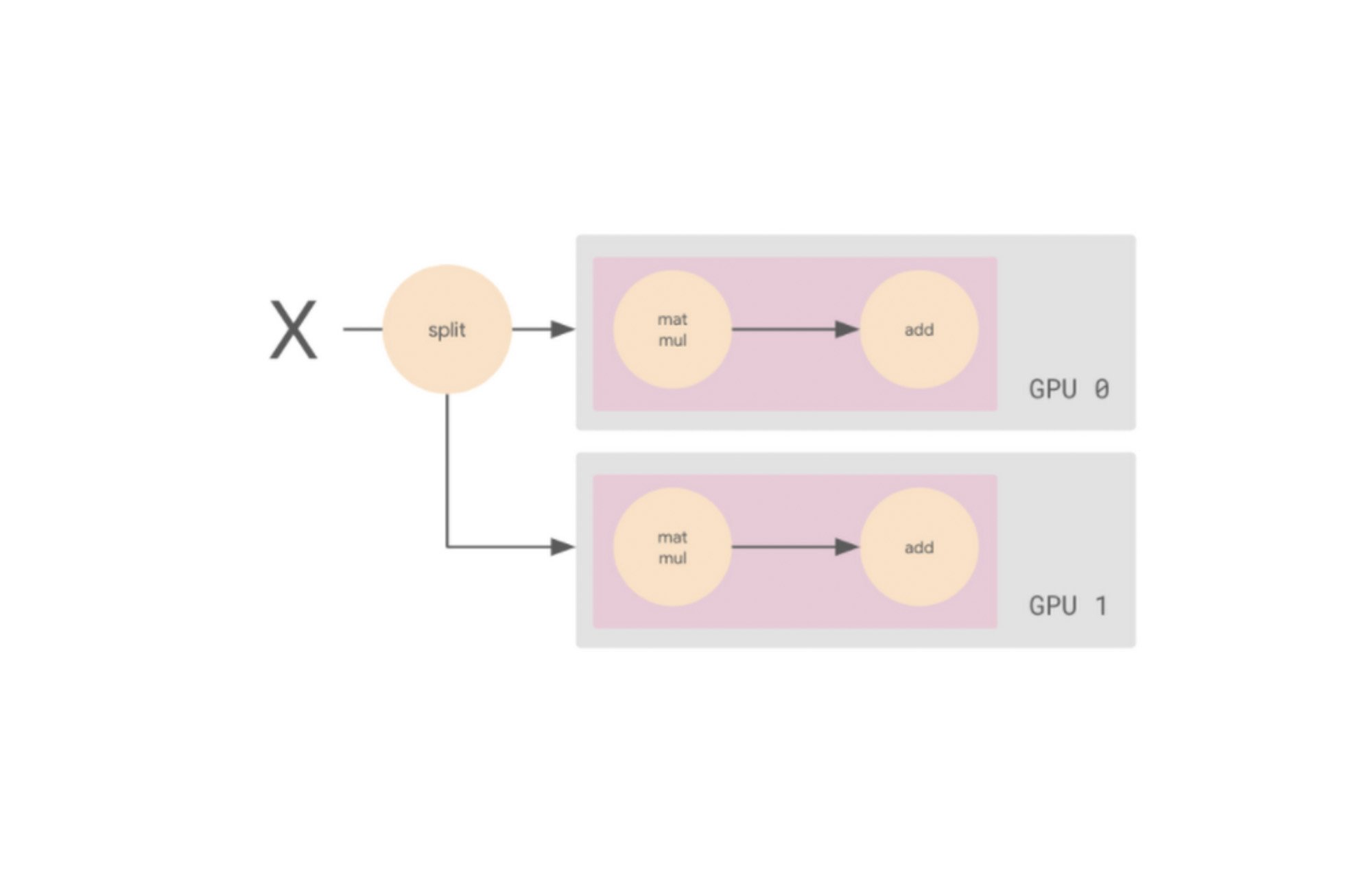
We want a way of executing this computational graph such that we can leverage multiple workers. One way we might do this is by splitting the input batch X in half, and sending one slice to GPU 0 and the other to GPU 1. In this case, each GPU worker calculates the same ops but on different slices of the data.
Adding this additional worker allows us to double the batch size. Each GPU gets a separate slice of data, they calculate the gradients, and these gradients are averaged. So effectively, with two GPUs your batch size becomes 64, and with 4 GPUs it would become 128. By adding more GPUs, your model sees more data on each training step. Which means that it takes less time to finish an epoch, which is just a full pass through the training data. And this is the core idea of data parallelism.
But, we’ve glossed over a key detail here. If both workers calculate the gradients on a different slice of data, then they will compute different gradients. So at the end of the backwards pass, we now have two different sets of gradients.
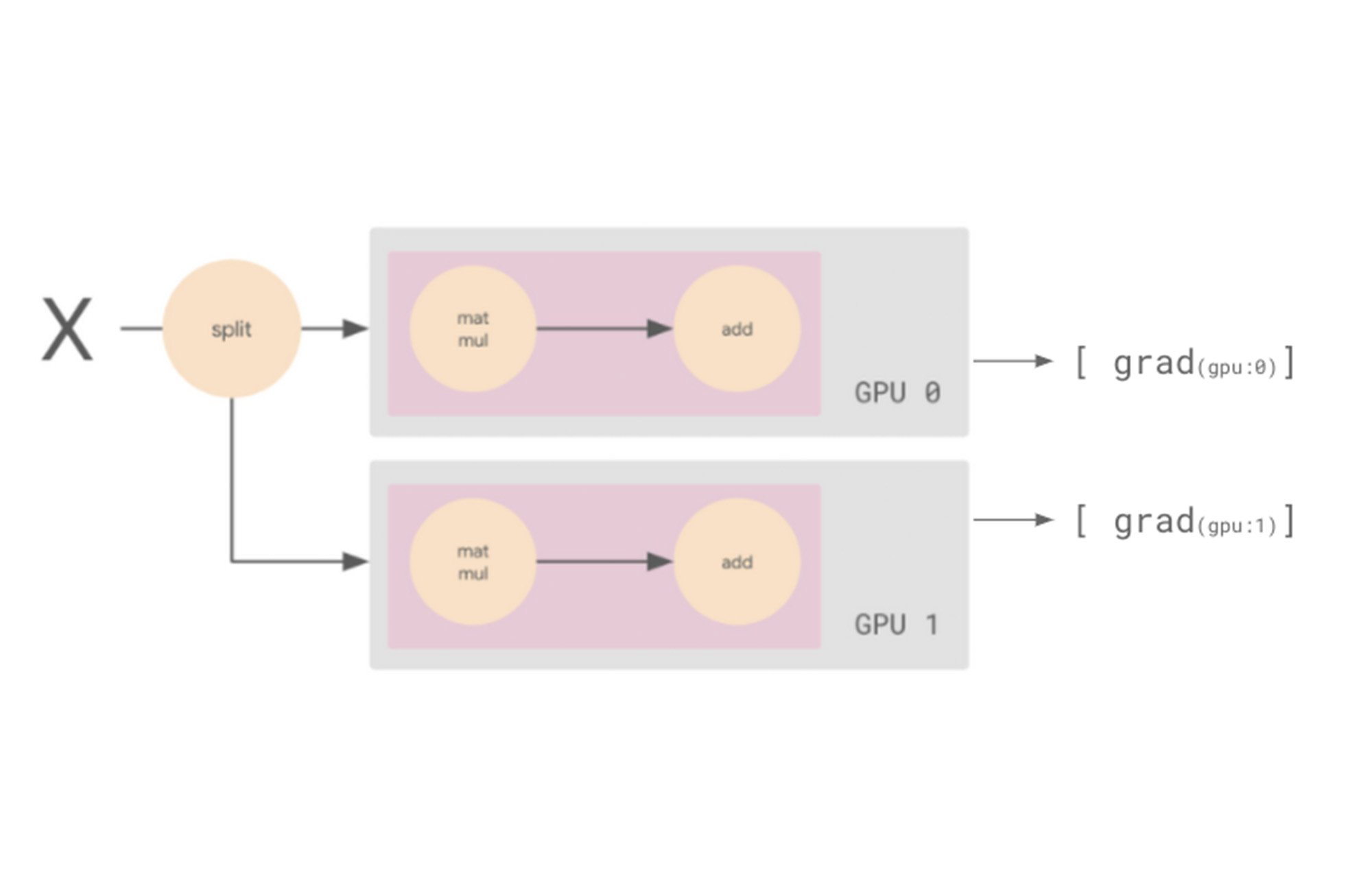
When you’re doing synchronous data parallel training, you want to take these multiple sets of gradients and turn them into one set. We’ll do this by averaging the gradients in a process known as AllReduce, and use these averaged gradients to update the optimizer.
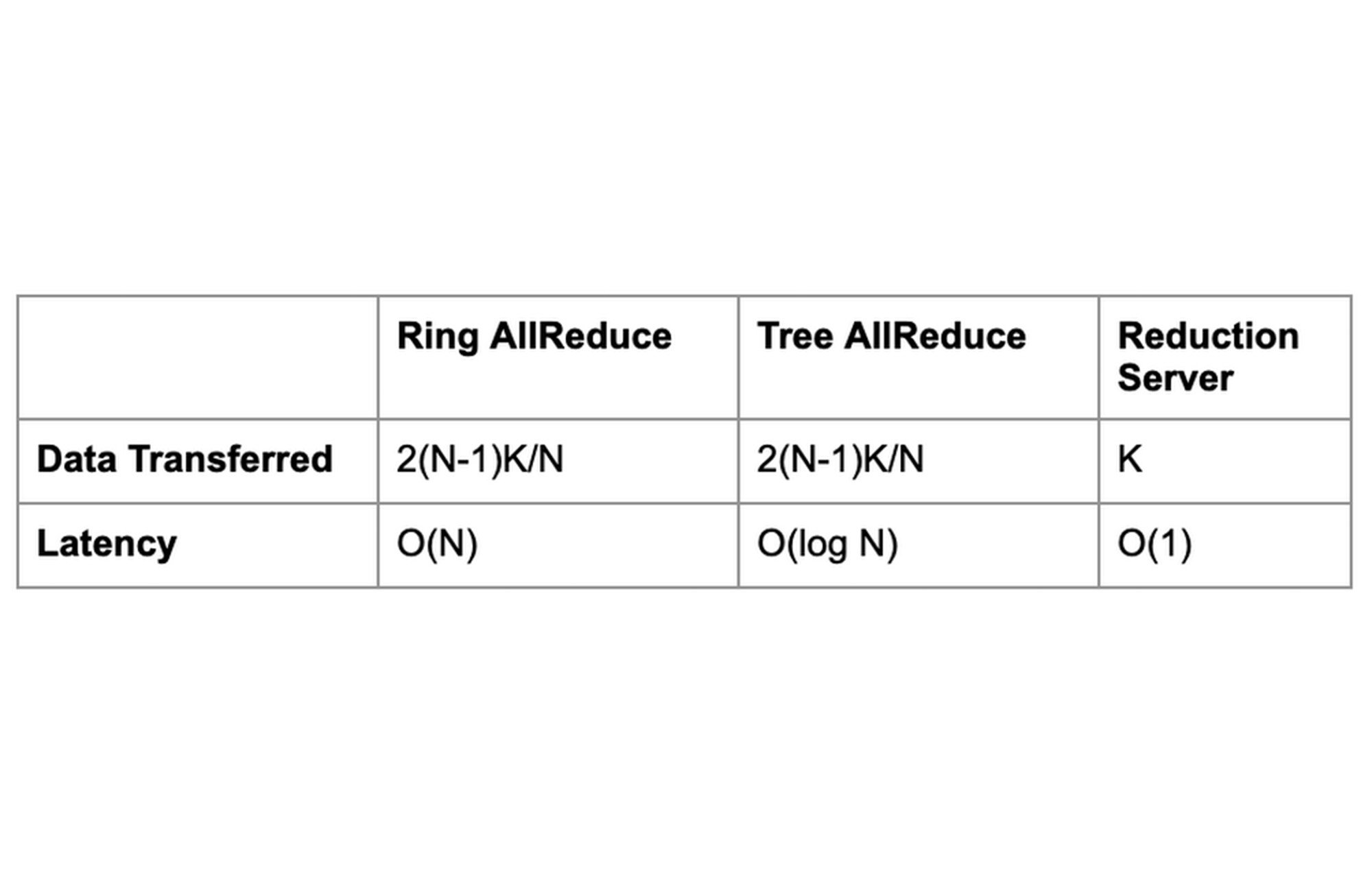
In order to compute the average, each worker needs to know the values of the gradients computed by all other workers. We want to pass this information between these nodes as efficiently as possible and use as little bandwidth as possible. There are many different algorithms for efficiently implementing this aggregation, such as Ring AllReduce, or other tree based algorithms. On Vertex AI, you can use Reduction Server, which optimizes bandwidth and latency of multi-node distributed training on NVIDIA GPUs for synchronous data parallel algorithms.
To summarize, a distributed data parallel setup works as follows:
Each worker device performs the forward pass on a different slice of the input data to compute the loss.
Each worker device computes the gradients based on the loss function.
These gradients are aggregated (reduced) across all of the devices.
The optimizer updates the weights using the reduced gradients, thereby keeping the devices in sync.
Vertex AI Reduction Server
Note that while data parallelism can be used to speed up training across multiple devices on a single machine, or multiple machines in a cluster, Reduction Server works specifically in the latter case.
Vertex Reduction Server introduces an additional worker role, a reducer. Reducers are dedicated to one function only: aggregating gradients from workers. And because of their limited functionality, reducers don’t require a lot of computational power and can run on relatively inexpensive compute nodes.
The following diagram shows a cluster with four GPU workers and five reducers. GPU workers maintain model replicas, calculate gradients, and update parameters. Reducers receive blocks of gradients from the GPU workers, reduce the blocks and redistribute the reduced blocks back to the GPU workers.
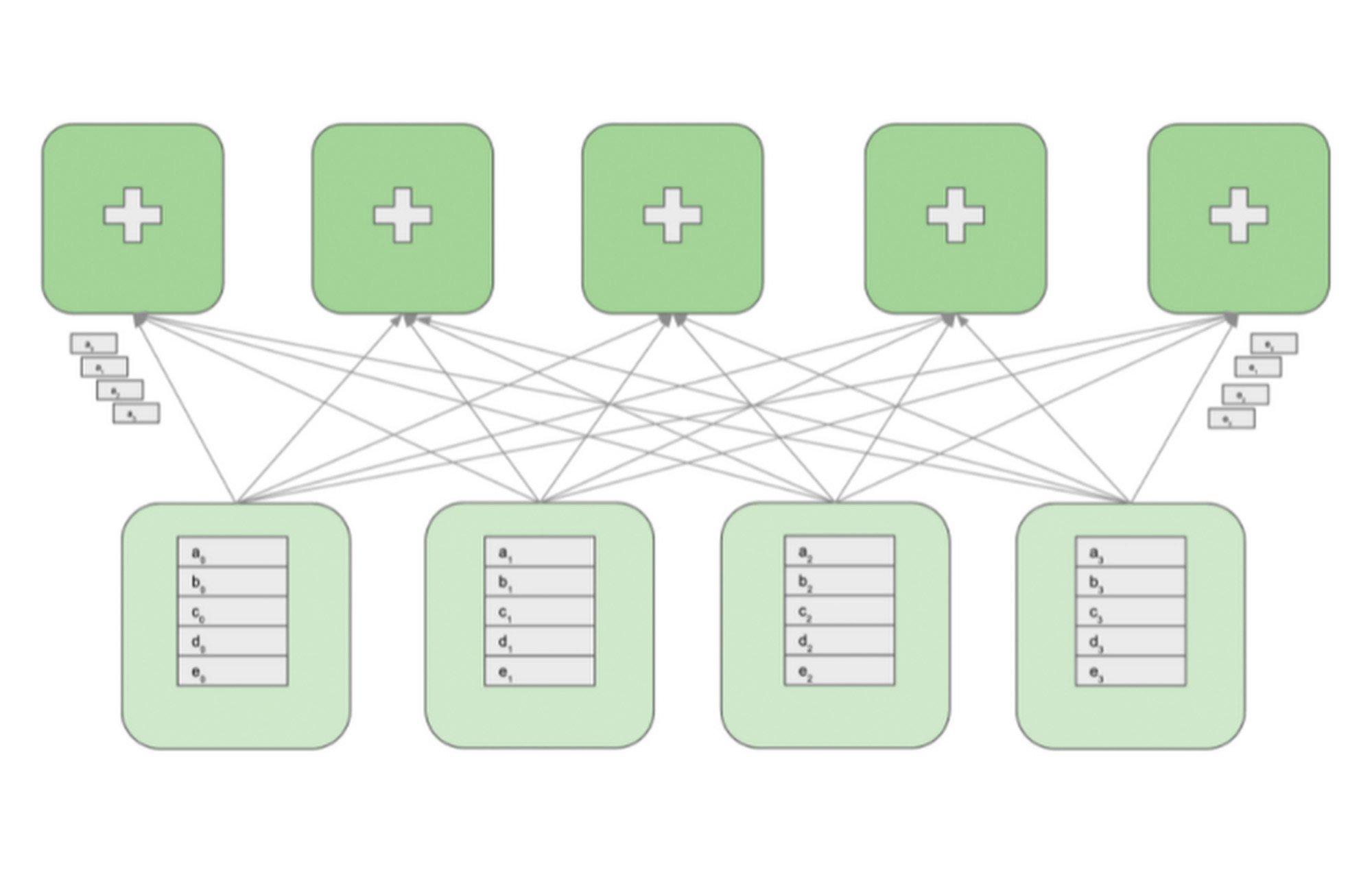
To perform the all-reduce operation, the gradient array on each GPU worker is first partitioned into M blocks, where M is the number of reducers. A given reducer processes the same partition of the gradient from all GPU workers. For example, as shown on the above diagram, the first reducer reduces the blocks a0 through a3 and the second reducer reduces the blocks b0 through b3. After reducing the received blocks, a reducer sends back the reduced partition to all GPU workers.
If the size of a gradient array is K bytes, each node in the topology sends and receives K bytes of data. That is almost half the data that the Ring and Tree based all-reduce implementations exchange. An additional advantage of Reduction Server is that its latency does not depend on the number of workers.
Using Reduction Server with PyTorch
Reduction Server can be used with any distributed training framework that uses the NVIDIA NCCL library for the all-reduce collective operation. You do not need to change or recompile your training application.
In the case of PyTorch, you could use the DistributedDataParallel (DDP) or FullyShardedDataParallel (FSDP) distributed training strategies. Once you’ve made the necessary changes to your PyTorch training code, you can leverage Reduction Server by:
Installing the Reduction Server NVIDIA NCCL transport plugging in your training container image.
Configuring a Vertex AI Training custom job that includes a Reduction Server worker pool.
Installing the Reduction Server NVIDIA NCCL transport plugin
Reduction Server is implemented as an NVIDIA NCCL transport plugin. This plugin must be installed on the container image that is used to run your training application. The plugin is included in the Vertex AI pre-built training containers.
Alternatively, you can install the plugin yourself by including the following in your Dockerfile
Configuring and submitting your training job
Vertex AI provides up to 4 worker pools to cover the different types of machine tasks you would encounter when doing distributed training. You can think of a worker as a single machine. And each worker pool is a collection of machines performing similar tasks.
Worker pool 0 configures the Primary, chief, scheduler, or "master". This worker generally takes on some extra work such as saving checkpoints and writing summary files. There is only ever one chief worker in a cluster, so your worker count for worker pool 0 will always be 1.
Worker pool 1 is where you configure the rest of the workers for your cluster.
Worker pool 2 manages Reduction Server reducers. When choosing the number and type of reducers, you should consider the network bandwidth supported by a reducer replica’s machine type. In Google Cloud, a VM’s machine type defines its maximum possible egress bandwidth. For example, the egress bandwidth of the n1-highcpu-16 machine type is limited at 32 Gbps.
First, you define the job. The example below assumes your code is structured as a Python source distribution, but a custom container would work as well.
After defining the job, you can call run and specify a cluster configuration that includes reduction server reducers.
The above run config specifies a cluster of 7 machines total:
- One chief worker
- Two additional workers
- Four reducers.
Note that the reducers need to run the reduction server container image provided by Vertex AI.
If you’d like to see sample code, check out this notebook.
Analyzing performance benefits
In general, computationally intensive workloads that require a large number of GPUs to complete training in a reasonable amount of time, and where the trained model has a large number of parameters, will benefit the most from Reduction Server. This is because the latency for standard ring and tree based all-reduce collectives is proportional to both the number of GPU workers and the size of the gradient array. Reduction Server optimizes both: latency does not depend on the number of GPU workers, and the quantity of data transferred during the all-reduce operation is lower than ring and tree based implementations.
One example of a workload that fits this category is pre-training or fine-tuning language models like BERT. Based on exploratory experiments, we saw more than 30% reduction in training time for this type of workload.
The diagrams below show the training performance comparison of a PyTorch distributed training job in a multi-nodes and multi-processing environment with and without Reduction Server. The PyTorch distributed training job was to fine-tune the pretrained BERT large model bert-large-cased from Hugging Face on the imdb dataset for sentiment classification.
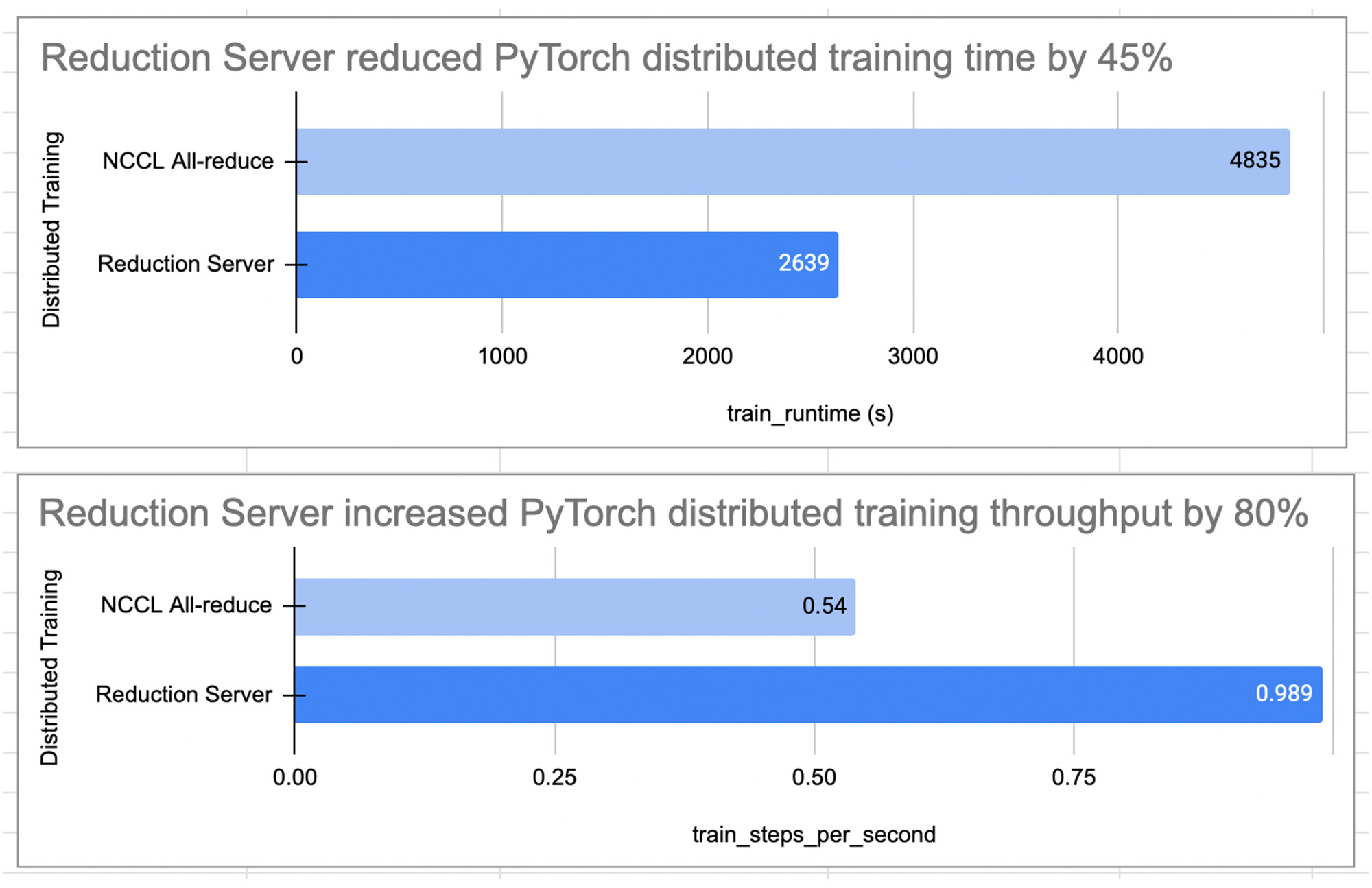
In this experiment, we observed that Reduction Server increased the training throughput by 80%, and reduced the training time and therefore the training cost by more than 45%.
This benchmark result highlights Reduction Server’s ability to optimize PyTorch distributed training on GPUs but we understand that the exact impact that Reduction Server could have on the training time and throughput depends on the characteristics of your training workload.
What’s next
In this article you learned how the Vertex AI Reduction Server architecture provides an AllReduce implementation that minimizes latency and data transferred by utilizing a specialized worker type that is dedicated to gradient aggregation. If you’d like to try out a working example from start to finish, you can take a look at this notebook, or take a look at this video to learn more about distributed training with PyTorch on Vertex AI.
It’s time to use Reduction Server and run some experiments of your own!




