Improve training time of distributed machine learning with NCCL Fast Socket
Winston Chiang
AI/ML Product Manager
Melody Ma
AI/ML Software Engineer
Large Machine Learning (ML) models – such as large language models, generative AI, and vision models – are dramatically increasing the number of trainable parameters and are achieving state-of-the-art results. Increasing the number of parameters results in the model being too large to fit on a single VM instance thus demands distributed compute to spread the model across multiple nodes. Google Kubernetes Engine (GKE) has built-in support for NCCL Fast Socket, to help improve the time to train large ML models with distributed, multi-node clusters.
Enterprises are looking for faster and cheaper performance to train their ML models. With distributed training, communicating gradients across nodes is a performance bottleneck. Optimizing inter-node latency is critical to reduce training time and costs. Distributed training uses collective communication as a transport layer over the network between the multiple hosts. Collective communication primitives such as all-gather, all-reduce, broadcast, reduce, reduce-scatter, and point-to-point send and receive are used in distributed training in Machine Learning.
The NVIDIA Collective Communication Library (NCCL) is commonly used by popular ML frameworks such as TensorFlow and PyTorch. It is a highly optimized implementation for high bandwidth and low latency between NVIDIA GPUs. Google developed a proprietary version of NCCL called NCCL Fast Socket to optimize performance for deep learning on Google Cloud.
NCCL Fast Socket uses a number of techniques to achieve better and more consistent NCCL performance.
Use of multiple network flows to attain maximum throughput. NCCL Fast Socket introduces additional optimizations over NCCL’s built-in multi-stream support, including better overlapping of multiple communication requests.
Dynamic load balancing of multiple network flows. NCCL can adapt to changing network and host conditions. With this optimization, straggler network flows will not significantly slow down the entire NCCL collective operation.
Integration with Google Cloud’s Andromeda virtual network stack.This increases overall network throughput by avoiding contentions in virtual machines (VMs).
We tested (NVIDIA NCCL tests) the performance of NCCL Fast Socket vs NCCL on various machine shapes with 2 node GKE clusters.
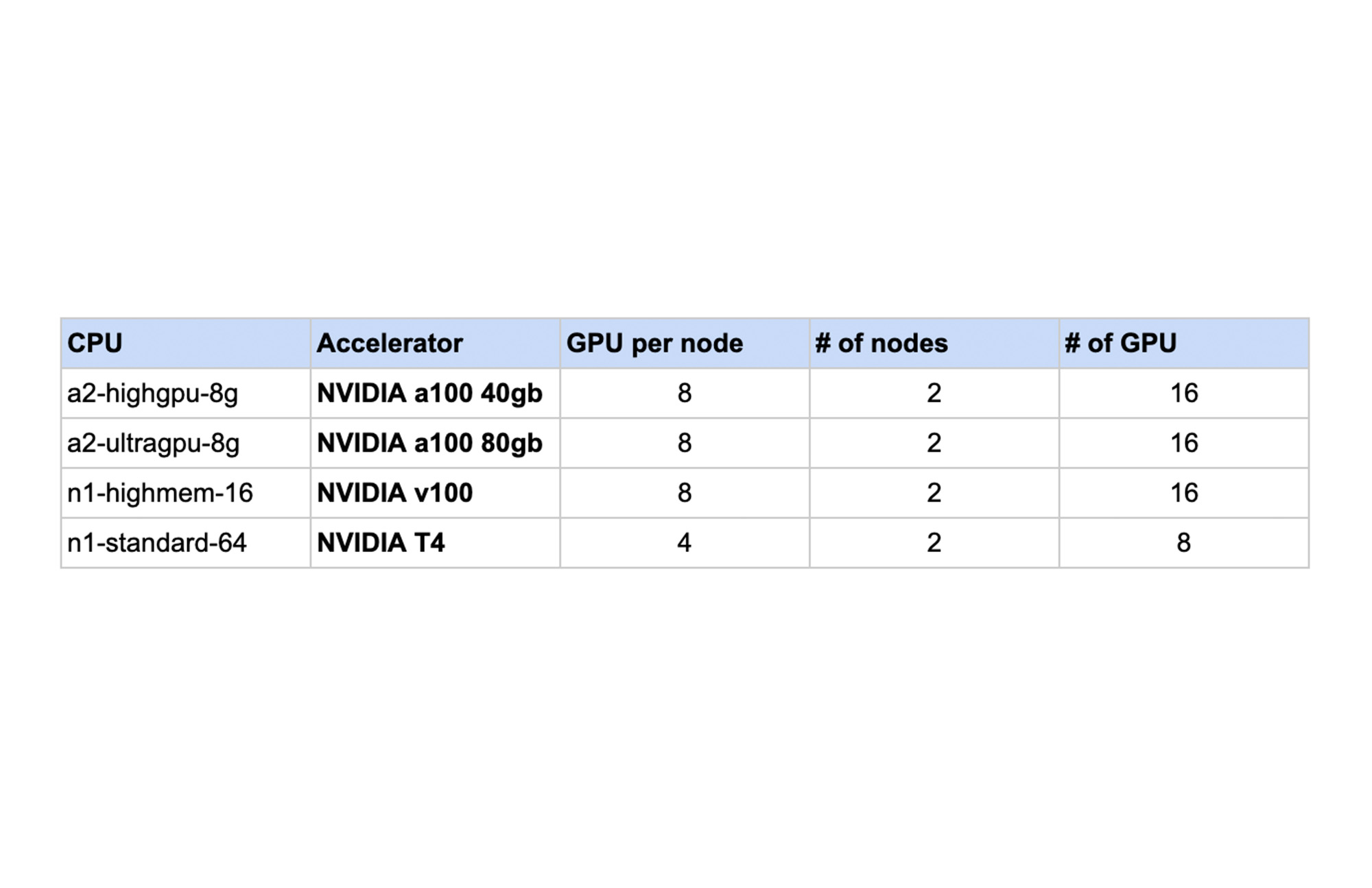
The following chart shows the results. For each machine shape, the NCCL performance without Fast Socket is normalized to 1. In each case, using NCCL Fast Socket demonstrated increased performance in a range of 1.3 to 2.6 times faster internetwork communication speed.

As a built-in feature, GKE users can take advantage of NCCL Fast Socket without changing or recompiling their applications, ML frameworks (such as TensorFlow or PyTorch), or even the NCCL library itself. To start using NCCL Fast Socket, create a node pool that uses the plugin with the --enable-fast-socket and --enable-gvnic flags. You can also update an existing node pool using gcloud container node-pools update.
To achieve better network throughput with NCCL, Google Virtual NICs (gVNICs) must be enabled when creating VM instances. For detailed instructions on how to use gVNICs, please refer to the gVNIC guide.
To verify that NCCL Fast Socket has been enabled, view the kube-system pods:
And the output should b similar to:
To learn more visit GKE NCCL Fast Socket documentation. We look forward to hearing how NCCL Fast Socket improves your ML Training experience on GKE.