RLHF Tuning with Vertex AI
Erwin Huizenga
AI engineering and evangelism manager
Bethany Wang
Staff Software Engineer and Manager, Google Cloud
Foundation models are large neural network models that can be adapted with minimal tuning to a wide range of tasks and exhibit impressive capabilities in generating high-quality text, images, speech, code, and more. Enterprises are leveraging foundation models to power different generative AI use cases, such as generating creative blog articles or improving customer support.
But the perception of high-quality results varies. For foundation models to best serve specific needs, organizations need to tune them to appropriately behave and deliver responses. Reinforcement Learning from Human Feedback (RLHF) is a popular method through which foundation models like large language models (LLMs), initially trained on a general corpus of text data, can be aligned to complex human values. In the context of enterprise use cases, RLHF leverages human feedback to help the model produce outputs that meet unique requirements.
What is RLHF?
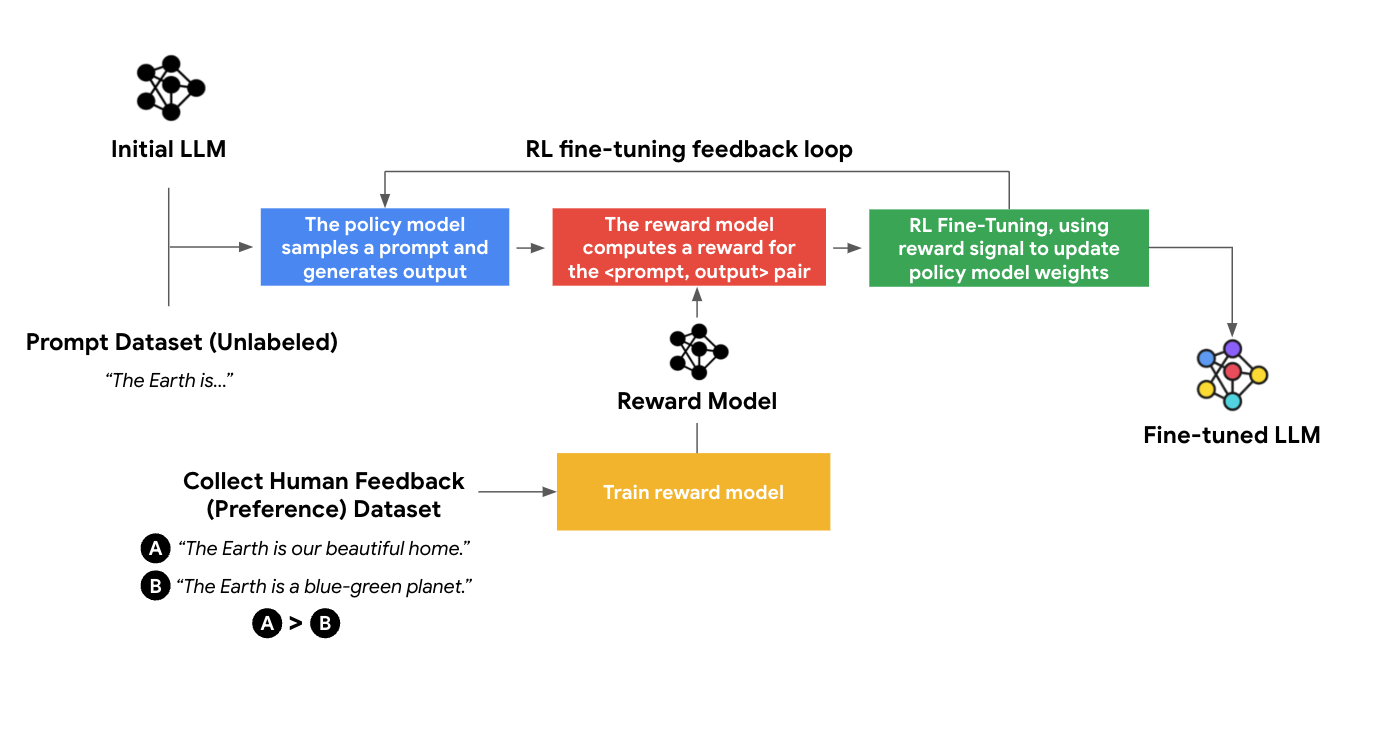
RLHF tuning consists of two phases: reward modeling and reinforcement learning.
1. Reward modeling
For reward modeling, data is collected in the form of comparisons. First off, we feed the same prompt into one or more LLMs to create multiple responses. Then, we ask human raters to rank these responses from good to bad. We take all the possible pairs between these responses and naturally, within each pair, one response is more preferred than the other. We do this for many prompts, and in this way, we have created the “human preference dataset.”
We train the reward model to act as a scoring function, so that it scores how good a response is for a given prompt. Recall that for each prompt, we have a ranked list of multiple responses. The reward model’s scores need to agree with the ranking as much as possible. We formulate this into a loss function and train the reward model to make reward predictions that are consistent with the ground truth ranking.
2. Reinforcement learning
Once we have a reward model, we can score the quality of any arbitrary <prompt, response> pair. In this step, we need the “prompt dataset,” which only contains the prompt (i.e. it is unlabeled). We draw a prompt from the dataset, use the LLM to generate a response, and use the reward model to score the quality of the response. If the response is high-quality, then all the tokens in the response (conditional on the prompt) are going to be “reinforced,”i.e. they will have a higher probability of being generated in the future. In this way, we can optimize the LLM to generate responses that maximize the reward. This algorithm is known as reinforcement learning (RL).
RLHF tuning requires orchestrating these two phases, handling large-scale distributed training on multi-host TPUs or GPUs using data parallelism and model partitioning, and optimizing for efficient throughput via computational graph compilation. The intensive computation also requires top-notch hardware accelerators for fast training. Vertex AI customers can implement RLHF using a Vertex AI Pipeline that encapsulates the RLHF algorithm to tune PaLM 2, FLAN-T5 and Llama 2 models. This helps to marry the LLM with the enterprise’s nuanced preferences and values for specific use cases.
State of the art RLHF with Vertex AI
We now offer a Vertex AI Pipeline template that encapsulates the RLHF algorithm. RLHF is embedded in Generative AI Studio on Vertex AI, making it easy for users to leverage the latest AI technology and enterprise security capabilities, like VPC/SC. Users can use RLHF with the Vertex AI MLOps capabilities like Model Registry and Model Monitoring. RLHF with Vertex AI helps organizations with the following:
- Performance: Improve the performance of LLMs to better align with human preference.
- Access to state of art Google proprietary models
- Accelerate tuning by leveraging latest accelerators like Cloud TPUs, and A100 GPUs
- Safety: RLHF can help LLMs be safer by providing negative sample responses.
Recruit Group
Recruit Group is a global leader in HR technology and business solutions that are transforming the world of work. In the HR Technology Strategic Business Unit, one of the company’s business pillars, their mission is to match job seekers with job opportunities, providing tools throughout the job searching process globally. Within the group, Recruit Co., Ltd. offers a search platform, career consultation, and preparation for job interviews, mainly in Japan. The business goal is to use AI technologies to optimize the communication between job-seekers and employers to make the process faster and simpler for people to get jobs.
Many foundation models have been proposed recently; however, there needs to be more clarity in addressing some specific tasks using general-purpose foundation models. For instance, improving job-seekers resumes requires proofreading and advising them with comprehensive industry knowledge, job types, companies, and hiring processes. It can be challenging for foundation models to generate advice or a comment for improving the resumes due to the generality of LLMs. Such tasks would require better alignment with the model output with human preference and the ability to control the output format.
Recruit Co., Ltd. has been evaluating a foundation model and a model tuned through RLHF. The goal of this experiment is to explore whether those models can get better on resume writing as a text generation task when tuned with HR domain knowledge. The performance was evaluated by HR experts. The experts examined the generated resumes one by one and determined if the resume meets the expectations of the production level quality bar. The success metric is the percentage of the generated resumes that pass the quality bar.
|
Model |
Dataset size |
Score |
|
Foundation Model (text-bison-001) |
- |
70% |
|
Supervised Tuning (text-bison-001) |
Prompt dataset: 4,000 |
76% |
|
RLHF (text-bison-001) |
Prompt dataset: 1,500 Human preference dataset: 4,000 |
87% |
The result shows that RLHF tuning using customer data can boost model performance to drive better outcomes. The Recruit Group plans to evaluate the difference between AI-generated content and content made by expert authors to estimate the benefits and the cost of automation.
What’s next?
To learn more about RLHF with Vertex AI, see the documentation, which provides resources that show you how to use RLHF with Vertex AI. You can also look at the notebook to get started with RLHF.
A special thanks to May Hu and Yossy Maki from Google Cloud for their contributions.



