Making the machine: the machine learning lifecycle
Andrew Ferlitsch
Developer Programs Engineer
As a Googler, one of my roles is to educate the software development community on machine learning (ML). The first introduction for many individuals is what is referred to as the ‘model’. While building models, tuning them, and evaluating their predictive abilities has generated a great deal of interest and excitement, many organizations still find themselves asking more basic questions, like how does machine learning fit into their software development lifecycle?
In this post, I explain how machine learning (ML) maps to and fits in with the traditional software development lifecycle. I refer to this mapping as the machine learning lifecycle. This will help you as you think about how to incorporate machine learning, including models, into your software development processes.
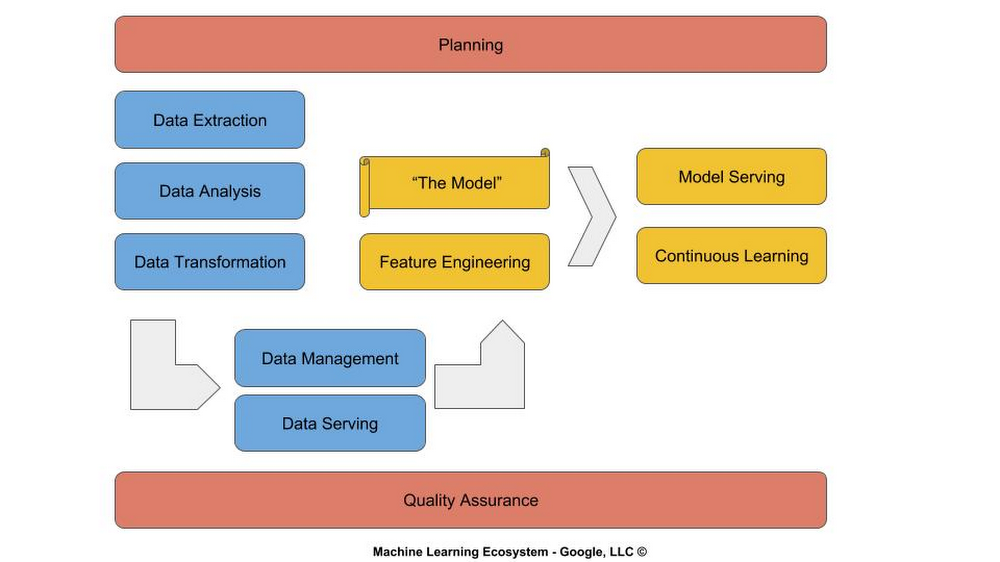
The machine learning lifecycle consists of three major phases: Planning (red), Data Engineering (blue) and Modeling (yellow).
Planning
In contrast to a static algorithm coded by a software developer, an ML model is an algorithm that is learned and dynamically updated. You can think of a software application as an amalgamation of algorithms, defined by design patterns and coded by software engineers, that perform planned tasks. Once an application is released to production, it may not perform as planned, prompting developers to rethink, redesign, and rewrite it (continuous integration/continuous delivery).
We are entering an era of replacing some of these static algorithms with ML models, which are essentially dynamic algorithms. This dynamism presents a host of new challenges for planners, who work in conjunction with product owners and quality assurance (QA) teams.
For example, how should the QA team test and report metrics? ML models are often expressed as confidence scores. Let’s suppose that a model shows that it is 97% accurate on an evaluation data set. Does it pass the quality test? If we built a calculator using static algorithms and it got the answer right 97% of the time, we would want to know about the 3% of the time it does not.
Similarly, how does a daily standup work with machine learning models? It’s not like the training process is going to give a quick update each morning on what it learned yesterday and what it anticipates learning today. It’s more likely your team will be giving updates on data gathering/cleaning and hyperparameter tuning.
When the application is released and supported, one usually develops policies to address user issues. But with continuous learning and reinforcement learning, the model is learning the policy. What policy do we want it to learn? For example, you may want it to observe and detect user friction in navigating the user interface and learn to adapt the interface (Auto A/B) to reduce the friction.
Within an effective ML lifecycle, planning needs to be embedded in all stages to start answering these questions specific to your organization.
Data engineering
Data engineering is where the majority of the development budget is spent—as much as 70% to 80% of engineering funds in some organizations. Learning is dependent on data—lots of data, and the right data. It’s like the old software engineering adage: garbage in, garbage out. The same is true for modeling: if bad data goes in, what the model learns is noise.
In addition to software engineers and data scientists, you really need a data engineering organization. These skilled engineers will handle data collection (e.g., billions of records), data extraction (e.g., SQL, Hadoop), data transformation, data storage and data serving. It’s the data that consumes the vast majority of your physical resources (persistent storage and compute). Typically due to the magnitude in scale, these are now handled using cloud services versus traditional on-prem methods.
Effective deployment and management of data cloud operations are handled by those skilled in data operations (DataOps). The data collection and serving are handled by those skilled in data warehousing (DBAs). The data extraction and transformation are handled by those skilled in data engineering (Data Engineers), and data analysis are handled by those skilled in statistical analysis and visualization (Data Analysts).
Modeling
Modeling is integrated throughout the software development lifecycle. You don’t just train a model once and you’re done. The concept of one-shot training, while appealing in budget terms and simplification, is only effective in academic and single-task use cases.
Until fairly recently, modeling was the domain of data scientists. The initial ML frameworks (like Theano and Caffe) were designed for data scientists. ML frameworks are evolving and today are more in the realm of software engineers (like Keras and PyTorch). Data scientists play an important role in researching the classes of machine learning algorithms and their amalgamation, advising on business policy and direction, and moving into roles of leading data driven teams.
But as ML frameworks and AI as a Service (AIaaS) evolve, the majority of modeling will be performed by software engineers. The same goes for feature engineering, a task performed by today’s data engineers: with its similarities to conventional tasks related to data ontologies, namespaces, self-defining schemas, and contracts between interfaces, it too will move into the realm of software engineering. In addition, many organizations will move model building and training to cloud-based services used by software engineers and managed by data operations. Then, as AIaaS evolves further, modeling will transition to a combination of turnkey solutions accessible via cloud APIs, such as for Cloud Vision and Cloud Speech-to-Text, and customizing pre-trained algorithms using transfer learning tools such as AutoML.
Frameworks like Keras and PyTorch have already transitioned away symbol programming into imperative programming (the dominant form in software development), and incorporate object-oriented programming (OOP) principles such as inheritance, encapsulation, and polymorphism. One should anticipate that other ML frameworks will evolve to include object relational models (ORM), which we already use for databases, to data sources and inference (prediction). Common best practices will evolve and industry-wide design patterns will become defined and published, much like how Design Patterns by the Gang of Four influenced the evolution of OOP.
Like continuous integration and delivery, continuous learning will also move into build processes, and be managed by build and reliability engineers. Then, once your application is released, its usage and adaptation in the wild will provide new insights in the form of data, which will be fed back to the modeling process so the model can continue learning.
As you can see, adopting machine learning isn’t simply a question of learning to train a model, and you’re done. You need to think deeply about how those ML models will fit into your existing systems and processes, and grow your staff accordingly. I, and all the staff here at Google, wish you the best in your machine learning journey, as you upgrade your software development lifecycle to accommodate machine learning. To learn more about machine learning on Google Cloud here, visit our Cloud AI products page.



