How Let’s Enhance uses NVIDIA AI and GKE to power AI-based photo editing
Uttara Kumar
Sr. Product Marketing Manager, Data Center, NVIDIA
Maulin Patel
Group Product Manager, Google Kubernetes Engine
There’s an explosion in the number of digital images generated and used for both personal and business needs. On e-commerce platforms and online marketplaces for example, product images and visuals heavily influence the consumer’s perception, decision making and ultimately conversion rates. In addition, there’s been a rapid shift towards user-generated visual content for ecommerce — think seller-generated product imagery, host-generated rental property photos and influencer-generated social media content. The challenge? These user-generated images are often captured using mobile cameras and vary greatly in terms of their size, quality, compression ratios and resolution, making it difficult for companies to provide consistent high-quality product images on their platforms.
That’s exactly the problem that Let’s Enhance, a computer vision startup with teams across the US and Ukraine, set out to solve with AI. The Let’s Enhance platform improves the quality of any user-generated photo automatically using AI-based features to enhance images through automatic upscaling, pixelation and blur fixes, color and low-light correction, and removing compression artifacts — all with a single click and no professional equipment or photo-editing chops.
“Let’s Enhance.io is designed to be a simple platform that brings AI-powered visual technologies to everyone — from marketers and entrepreneurs to photographers and designers,” said Sofi Shvets, CEO and Co-founder of Let’s Enhance.

To date, Let’s Enhance has processed more than 100M photos for millions of customers worldwide for use-cases ranging from digital art galleries, real estate agencies, digital printing, ecommerce and online marketplaces. With the introduction of Claid.ai, their new API to automatically enhance and optimize user-generated content at scale for digital marketplaces, they needed to process millions of images every month and manage sudden peaks in user demand.
However, building and deploying an AI-enabled service at scale for global use is a huge technical challenge that spans model building, training, inference serving and resource scaling. It demands an infrastructure that’s easy to manage and monitor, can deliver real-time performance to end customers wherever they are and can scale as user-demand peaks, all while optimizing costs.
To support their growing user-base, Let’s Enhance chose to deploy their AI-powered platform to production on Google Cloud and NVIDIA . But before diving into their solution, let’s take a close look at the technical challenges they faced in meeting their business goals.
Architecting a solution to fuel the next wave of growth and innovation
To deliver the high-quality enhanced images that end-customers see, Let’s Enhance products are powered by cutting-edge deep neural networks (DNNs) that are both compute- and memory-intensive. While building and training these DNN models in itself is a complex, iterative process, application performance — when processing new user-requests, for instance — is crucial to delivering a quality end user experience and reducing total deployment costs.
A single inference or processing request i.e., from user-generated image, which can vary widely in size, at the input to the AI-enhanced output image, requires combining multiple DNN models within an end-to-end pipeline. The key inference performance metrics to optimize for included latency (the time it takes from providing an input image to the enhanced image being available) and throughput ( the number of images that can be processed per second)..
Together, Google Cloud and NVIDIA technologies provided all the elements that the Let’s Enhance team needed to set themselves up for growth and scale. There were three main components in the solution stack:
Compute resources: A2 VMs, powered by NVIDIA A100 Tensor Core GPUs
Infrastructure management: Google Kubernetes Engine (GKE)
Inference serving: NVIDIA Triton Inference Server
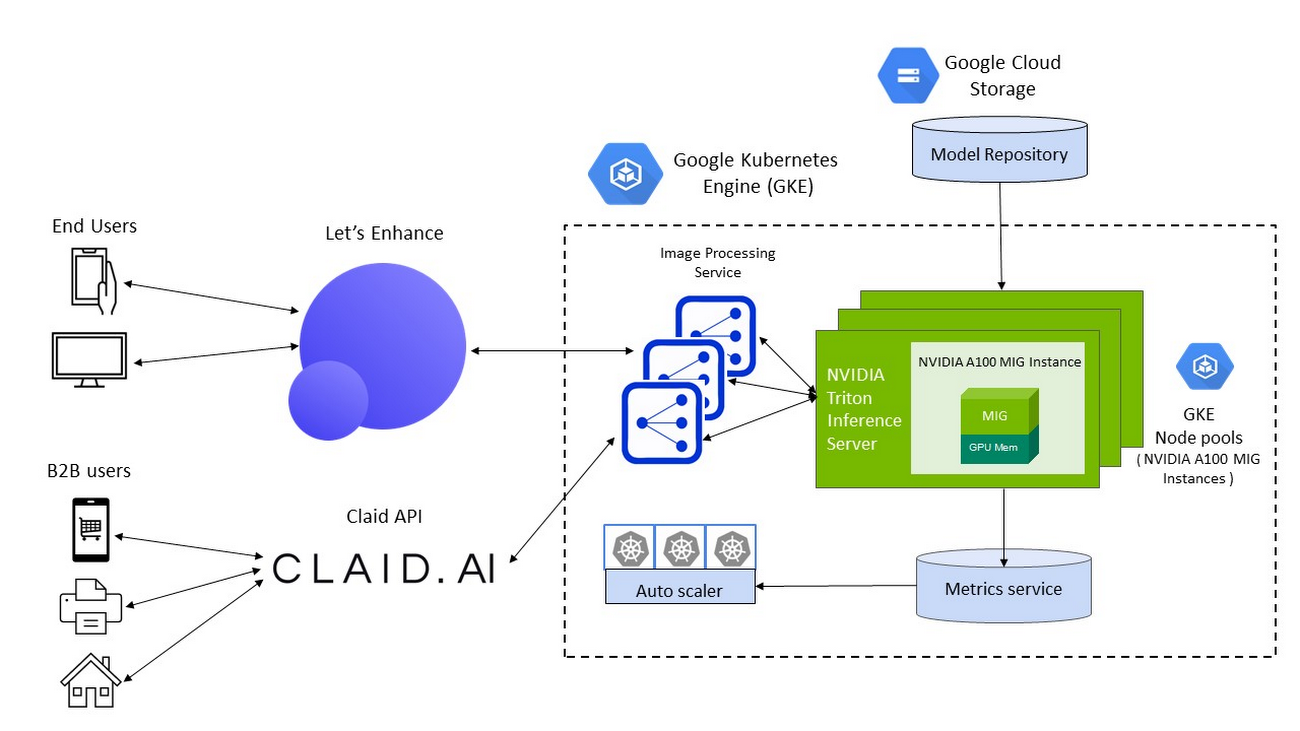
Improved throughput and lower costs with NVIDIA A100 Multi-Instance GPUs (MIG) on Google Cloud
To meet the computational requirements of the DNN models and deliver real-time inference performance to their end-users, Let’s Enhance chose Google Cloud A2 VMs powered by NVIDIA A100 Tensor Core GPUs as their compute infrastructure. A100 GPU’s Multi-Instance GPU (MIG) capability offered them the unique ability to partition a single GPU into two independent instances and simultaneously process two user-requests at a time, making it possible to service a higher volume of user requests while reducing the total costs of deployment.
The A100 MIG instances delivered a 40% average throughput improvement compared to the NVIDIA V100 GPUs, with an increase of up to 80% for certain image enhancement pipelines using the same number of nodes for deployment. With improved performance from the same sized node pools, Let’s Enhance observed a 34% cost savings using MIG-enabled A100 GPUs.
Simplified infrastructure management with GKE
To offer a guaranteed quality-of-service (QoS) to their customers and manage user demand, Let’s Enhance needed to provision, manage and scale underlying compute resources while keeping utilization high and costs low.
GKE offers industry-leading capabilities for training and inference such as support for 15,000 nodes per cluster, auto-provisioning, auto-scaling and various machine types (e.g. CPU, GPU and on-demand, spot), making it the perfect choice for Let’s Enhance.
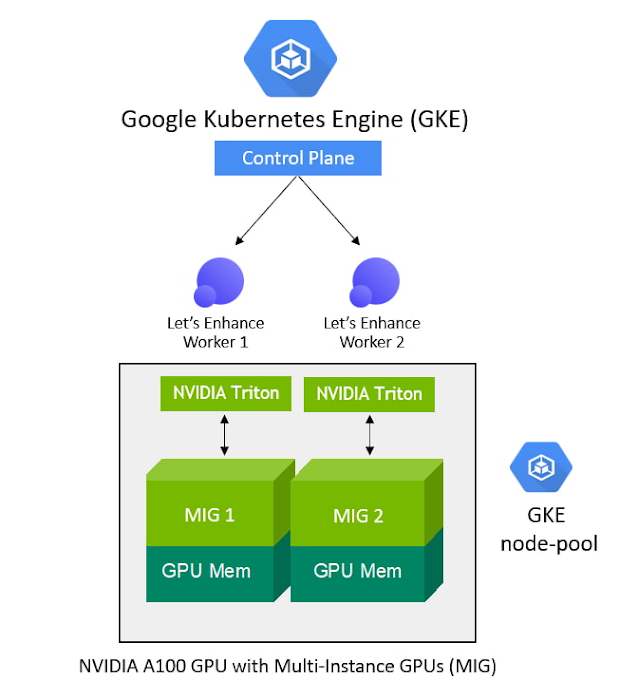
With support for NVIDIA GPUs and NVIDIA GPU sharing capabilities, GKE can provision multiple A100 MIG instances to process user requests in parallel and maximize utilization. As the compute required for the deployed ML pipelines increases (e.g., a sudden surge in inference requests to service), GKE can automatically scale to additional node-pools with MIG partitions — offering finer granularity to provision the right-sized GPU acceleration for workloads of all sizes.
“Our total averaged throughput varied between 10 and 80 images / sec. Thanks to support for NVIDIA A100 MIG and auto scaling mechanisms in GKE we can now scale that up to 150 images/sec and more, based on user-demand and GPU availability,” said Vlad Pranskevičius, Co-founder and CTO, Let’s Enhance.
In addition, GKE’s support for dynamic scheduling, automated maintenance and upgrades, high availability, job API, customizability and fault tolerance simplified managing a production deployment environment, allowing the Let’s Enhance team to focus on building advanced ML pipelines.
High-performance inference serving with NVIDIA Triton Inference Server
To optimize performance and simplify the deployment of their DNN models onto the GKE-managed node pools of NVIDIA A100 MIG instances, Let’s Enhance chose the open-source NVIDIA Triton Inference Server, which deploys, runs and scales AI models from any framework onto any GPU- or CPU-based infrastructure.
NVIDIA Triton’s support for multiple frameworks enabled the Let’s Enhance team to serve models trained in both TensorFlow and PyTorch, eliminating the need to set up and maintain multiple serving solutions for different framework backends. In addition, Triton’s ensemble model and shared memory features helped maximize performance and minimize data transfer overhead for their end-to-end image processing pipeline, which consists of multiple models and large amounts of raw image data transferring between them.
“We saw over 20% performance improvement with Triton vs. custom inference serving code, and were also able to fix several errors during deployment due to Triton’s self-healing features”, said Vlad. “Triton is packed with cool features, and as I was watching its progress from the very beginning, the pace of product development is just amazing.”
To further enhance end-to-end inference performance, the team is adopting NVIDIA TensorRT, an SDK to optimize trained models for deployment with the highest throughput and lowest latency while preserving the accuracy of predictions.
“With the subset of our models which we converted from Tensorflow to NVIDIA TensorRT we observed a speedup of anywhere between 10% and 42%, depending on the model, which is impressive,” said Vlad. “For memory-intensive models like ours, we were also able to achieve predictable memory consumption, which is another great benefit of using TensorRT, helping prevent any unexpected memory-related issues during production deployment.”
Teamwork makes the dream work
By using Google Cloud and NVIDIA, Let’s Enhance addressed the real-time inference serving and infrastructure management challenges of taking their AI-enabled service to production at scale in a secure Google Cloud infrastructure.
GKE, NVIDIA AI software and A2 VMs powered by NVIDIA A100 GPUs brought together all the elements they needed to deliver the desired user experience and build a solution that can dynamically scale their end-to-end pipelines based on user demand.
The close collaboration with the Google Cloud and NVIDIA team, every step of the way, also helped Let’s Enhance get their solution to market fast. “The Google Cloud and NVIDIA teams are incredible to work with. They are highly professional, always responsive and genuinely care about our success,” said Vlad. “We were able to get technical advice and recommendations directly from Google Cloud product and engineering teams, and also have a channel to share our feedback about Google Cloud products, which was really important to us.”
With a solid foundation and solution architecture that can meet their growing business needs, Let’s Enhance is marching towards their goal of bringing AI-enhanced digital images to everyone. “Our vision is to help businesses effectively manage user-generated content and increase conversion rates with next-gen AI tools,” said Sofi. ”Our next step towards that is to expand our offerings to completely replace manual work for photo preparation, including as well as cover pre-stages as image quality assessment and moderation.”
To learn more about the Let’s Enhance products and services, check out their blog here.



