How Wayfair is improving its feature engineering system with Vertex AI
Anh Do
Staff Machine Learning Engineer, Wayfair
Roger Bock
Staff Machine Learning Engineer, Wayfair
Here at Wayfair, our data scientists rely on multiple sources of data to obtain features for model training. An ad hoc approach to feature engineering led to multiple versions of feature definitions, making it challenging to share features between different models. Most of the features were stored and used with minimal oversight on freshness, schema, and data guarantees. As a result, our data scientists frequently encountered discrepancies in model performance between development and production environments, making the feedback loop for retraining cumbersome. The whole process of curating new stable features and developing new model versions often took several months.
To address these issues, the Service Intelligence team at Wayfair decided to create a centralized feature engineering system. Our goal was to standardize feature definitions, automate ingestion processes, and simplify maintenance. We worked with Google to adopt different Vertex AI offerings, especially Vertex AI Feature Store and Vertex AI Pipelines. The former provides a centralized repository for organizing, storing, and serving ML features, and the latter helps to automate, monitor, and manage ML workflows. These offerings became the two main components of our feature engineering architecture.
On the data side, we developed workflows to streamline the flow of raw features data into BigQuery tables. We created a centralized repository of feature definitions that specify how each feature should be pulled, processed, and stored in the feature store. Using the Vertex AI Feature Store’s API, we automatically create features based on the given definitions. We use GitHub’s PR approval process to enforce governance and track changes.

Sample feature definition
We set up Vertex AI Pipelines to transform raw data in BigQuery into features in the feature store. These pipelines run SQL queries to extract the data, transform it, and then ingest it into the feature store. The pipelines run on different cadences depending on how frequently the features change, and what level of recency is required by the models that consume them. The pipelines are triggered by Cloud Functions that listen for Pub/Sub messages. These messages are generated both on a static schedule from Cloud Scheduler, and dynamically from other pipelines and processes.
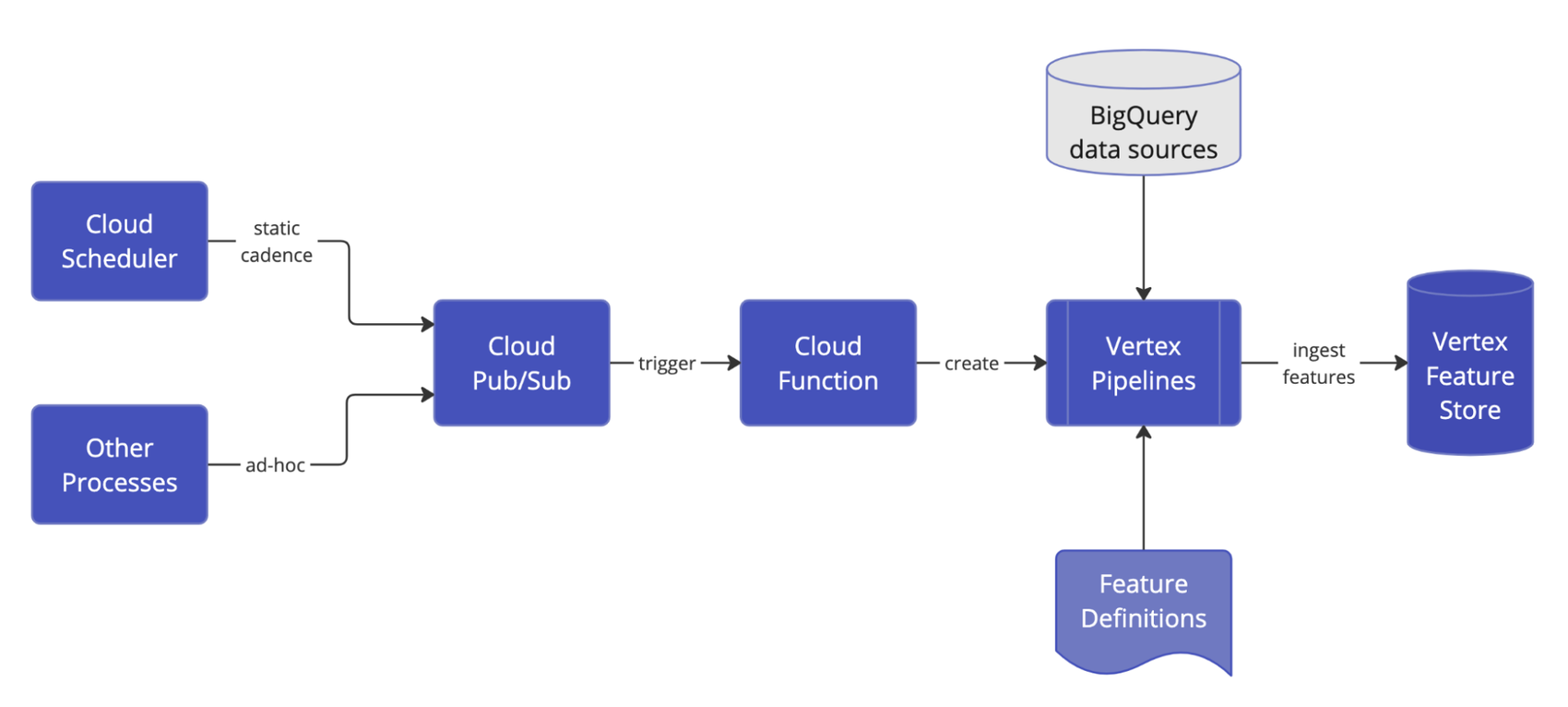
Feature Engineering System Diagram
The Vertex AI Feature Store enables both training and inference. For training it allows data scientists to export historical feature values via point-in-time lookup to retrain their models. For inference it serves features at low latency to production models that make their predictions in real-time. Furthermore, it ensures consistency between our development and production environments, avoiding training-serving skew. Data scientists are able to confidently iterate on new model versions without worrying about data-related issues.
Our new feature engineering system makes it easy for data scientists to share and reuse features, while helping to provide guarantees around offline-online consistency and feature freshness. We are looking forward to adopting the new version of Vertex AI Feature Store that is now in public preview, as it will provide more transparent access to the underlying data and should reduce our cloud costs by allowing us to use BigQuery resources dedicated to our project.
The authors would like to thank Duncan Renfrow-Symon and Sandeep Kandekar from Wayfair for their technical contributions and Neela Chaudhari, Kieran Kavanagh, and Brij Dhanda from Google for their support with Google Cloud.



