How a steel distributor reinvents its data science & ML workflows with Vertex AI
Alex Erfurt
Sr. Machine Learning Specialist, Google Cloud
Soohyun Kim
Sr. DevOps Engineer, Klöckner
Try Google Cloud
Start building on Google Cloud with $300 in free credits and 20+ always free products.
Free trialNowadays, many companies have to ask themselves: Do we want to wait until a startup disrupts our business model or will we just do it on our own? Klöckner, a German steel and metal distributor, chose the second option, leveraging the power of Google Cloud to bring a more customer-focused, agile approach to an industry often mired in costly, antiquated, and time-consuming processes.
In this blog post, you will learn how Klöckner used Google Cloud Vertex AI services such as AutoML and Vertex AI Pipelines to improve internal processes through machine learning (ML), including increasing velocity in ML model building, reducing time to production, and providing solutions for production-level ML challenges such as versioning, lineage, and reproducibility. To put it in the words of the customer: “Vertex provided solutions for problems we were not aware of yet,” said Matthias Berkenkamp, the engineer who spearheaded Klöckner’s use of the AI service.
Klöckner implemented a webshop, offering a solution for their customers to purchase products through a digital channel. Although the shop was very well perceived, Klöckner discovered that a significant portion of their customers still ordered through phone calls, emails and submitted PDFs. The order then required manual processing to get the data into their order systems—taking up valuable time and creating both inefficiencies and frequent errors. Klöckner recognized that ML could help improve and automate the purchase entry process.
From the first ML model to the complexity of ML in production
Klöckner’s data science team came up with different ideas and developed models for various use cases, such as automated extraction of text from PDF files that were attached to purchase order emails. However, they didn’t have experience on how to implement the model into their first ML application, which was called IEPO (Information Extraction from Purchase Orders). Moreover, Klöckner experienced communication challenges between data scientists and the DevOps team. There was neither a software build pipeline nor documentation about the model training, which was an absolute no-go for a team living the GitOps approach: if it’s not in Git, it cannot go to production. After many delays, the model was finally deployed but couldn’t handle heavy loads such as orders with 20+ PDFs. No one tested these edge cases before as there were so many other problems to solve first. This neglected part between creating a model and finally running it in production was an underestimated beast.
How Vertex AI provided the right tools
AutoML was the eye-opening entry point
Klöckner identified a new use case to be tested: a model that matches mail content (e.g. product numbers, descriptions or specific parameters such as “80/60/4mm, Alu-Rechteckrohr”) to specific internal products. They adopted Vertex AI Auto ML for this task. Because AutoML enabled faster model development and easier collaboration, it simple for everyone to start: no internal processes to get a budget (the initial $300 credit is often enough to train first models), staffing of data scientists or anything like that was not needed for a first try, and considerably less data was already sufficient to test it out. Surprisingly, for the little effort it took, the results were decent and accessible for everyone. This experience turned the switch for many people involved (from data science through product owners to DevOps), which led to assessing Vertex AI to solve the challenges of bringing ML models into production.
ML in production requires special tooling
After struggling with ML in production initially, the DevOps team started to look for and compare different tools that could help in handling the complexity. That was when they came across the open-source software Kubeflow Pipelines (KFP), an ML workload orchestrator. At first glance it seemed to be a good fit, as Klöckner already used Kubernetes clusters. There was still too much time consuming overhead operating clusters manually, however. Additionally, knowledge about Docker containers and Kubernetes is required to use Kubeflow—which is overkill for most data scientists and areas in which the company’s team was inexperienced.
After having a closer look into Vertex AI, Klöckner encountered Kubeflow Pipelines again, but this time they were able to run their ML workloads on the fully-managed service, Vertex AI Pipelines. The provided software development kit (SDK) by Google made it easy to use Kubeflow Pipelines, even for data scientists with little experience. This let the data science team and the DevOps team focus on the pipelines themselves, instead of managing Kubernetes clusters or the overall infrastructure underneath. Further, the DevOps team felt better prepared this time, as they collectively had finished Coursera's ML Engineering for Production course. Hence, they better understood ML and MLOps concepts and practices. This helped them to realize what went wrong the first time and what they could do to improve operating a project of this size better across teams. It was critical to not reproduce issues from prior projects and Vertex AI offered everything needed in an integrated bundle. From managed datasets over pipelining to metadata versioning, governance and so much more. Let alone the helping hand of other Google Cloud services such as Cloud Build and Artifact Registry for building, storing, and retrieving Docker container images.
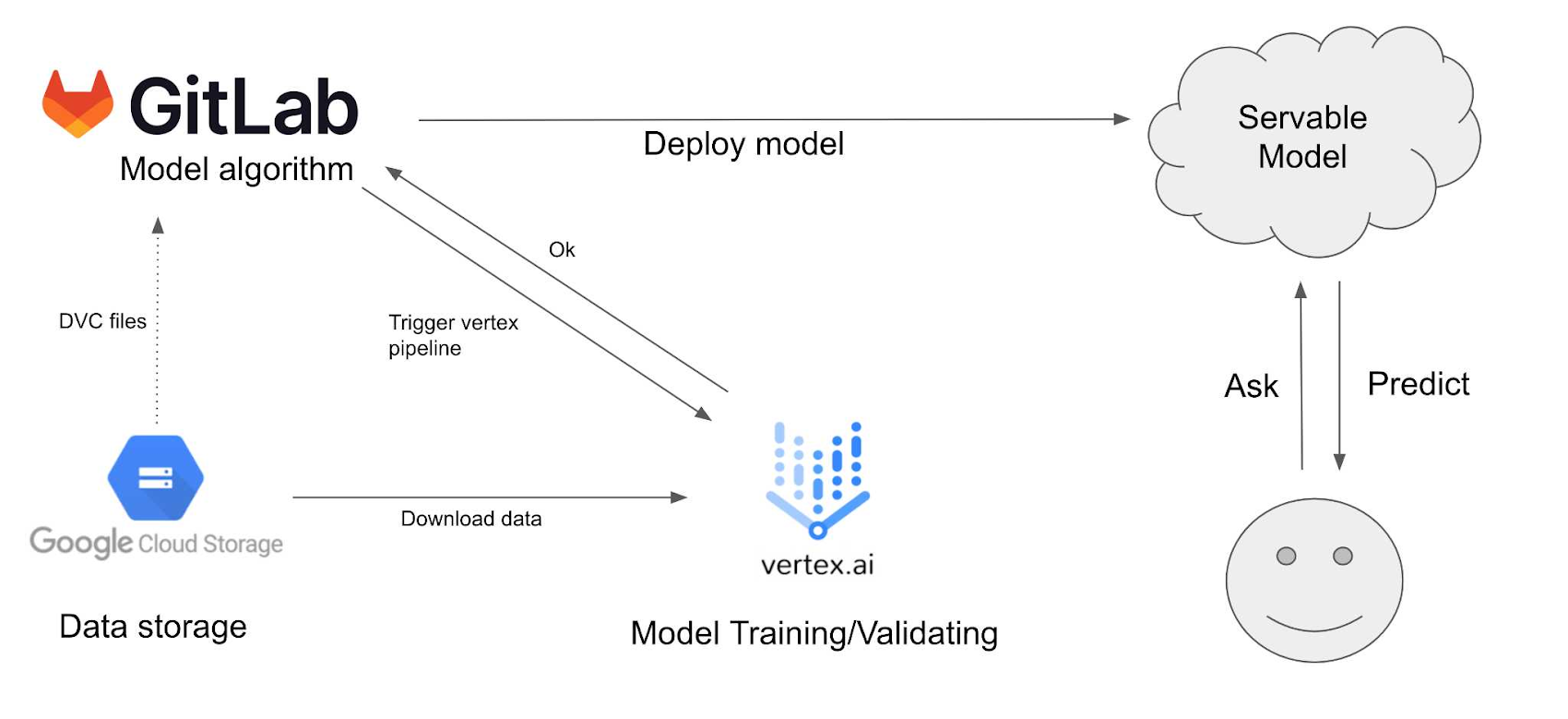
The initial workflow: a good start but imperfect
In their first attempt for the IEPO solution, each GitLab build pipeline started with the commit of a fully trained model. Data scientists manually did all training steps before on their manually managed and long running VM instances in Google Cloud. There were some scripts (e.g., for creating the train/test/validation data split or downloading PDFs to the respective machine), but each scientist needed to have the workflow in mind or consult the different places where it was hopefully correctly written down. The contributors to the software build pipeline in GitLab cared about building a Docker image and the serving infrastructure around the model. In fear of breaking the model build and training, the data scientists did not upgrade their machines in the cloud. A simple change in environment (e.g a simple library update) might have broken their VMs and the model training for several days. They felt that having mostly mathematical backgrounds and more interest in preparing data and improving machine learning models, the maintenance of a VM should be none of their duties. They realized that most packages on used VMs were outdated for two years or more and partly publicly accessible—a real security nightmare for every administrator. Hence, the goal was to go away from everyone developing/hosting on their own, resulting in different software versions etc. There was a clear need for some harmonization across all users and environments.
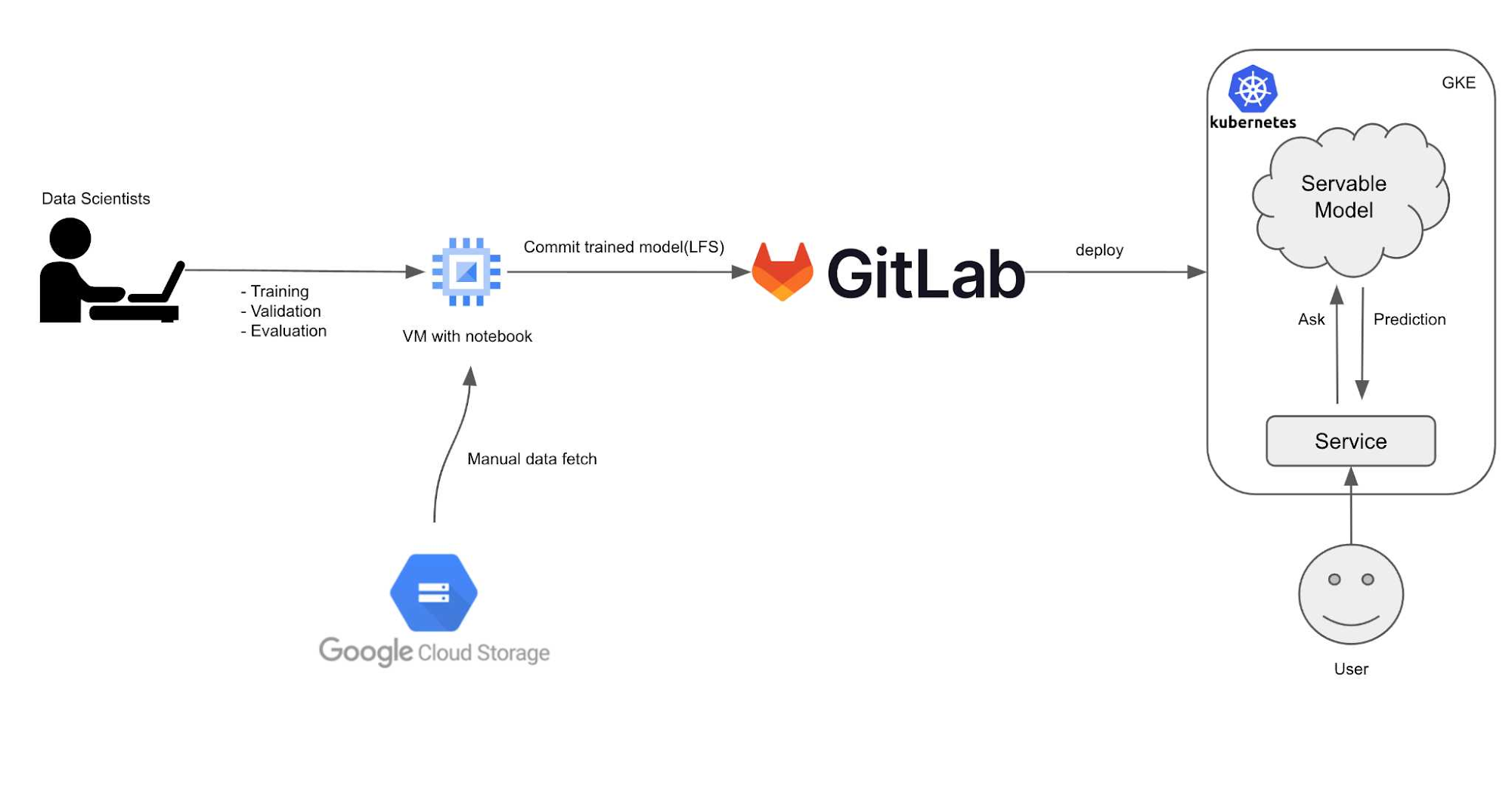
The result: more standardized & automated workflows for end-to-end ML in production
Trust and patience paid out. The new workflow using Vertex AI Pipelines addresses their previous problems. Everything that goes to production needs to go via Git, otherwise it won’t be deployed. Data scientists needed to understand and learn how to work more like DevOps. A handful of workshops and trainings later, the data science team was convinced and understood the benefits of working through Git-based processes, such as working better collaboratively, faster, consistent, etc.
Now, each commit to the Git repository is triggering a GitLab pipeline. There, the model code gets dockerized and uploaded to the Google Artifact Registry to which the Kubeflow Pipelines components have easy access. The subsequent build step defines the ML pipeline and creates it in Vertex AI. Data cleanup and splits, model training and validation are all is written in python code with the help of the Vertex AI SDK for Python. Each Kubeflow Pipeline component can request access to a GPU for faster training or more memory for preprocessing of the data. When the model training is finished, the GitLab pipeline continues and deploys the model onto a Kubernetes cluster for serving.
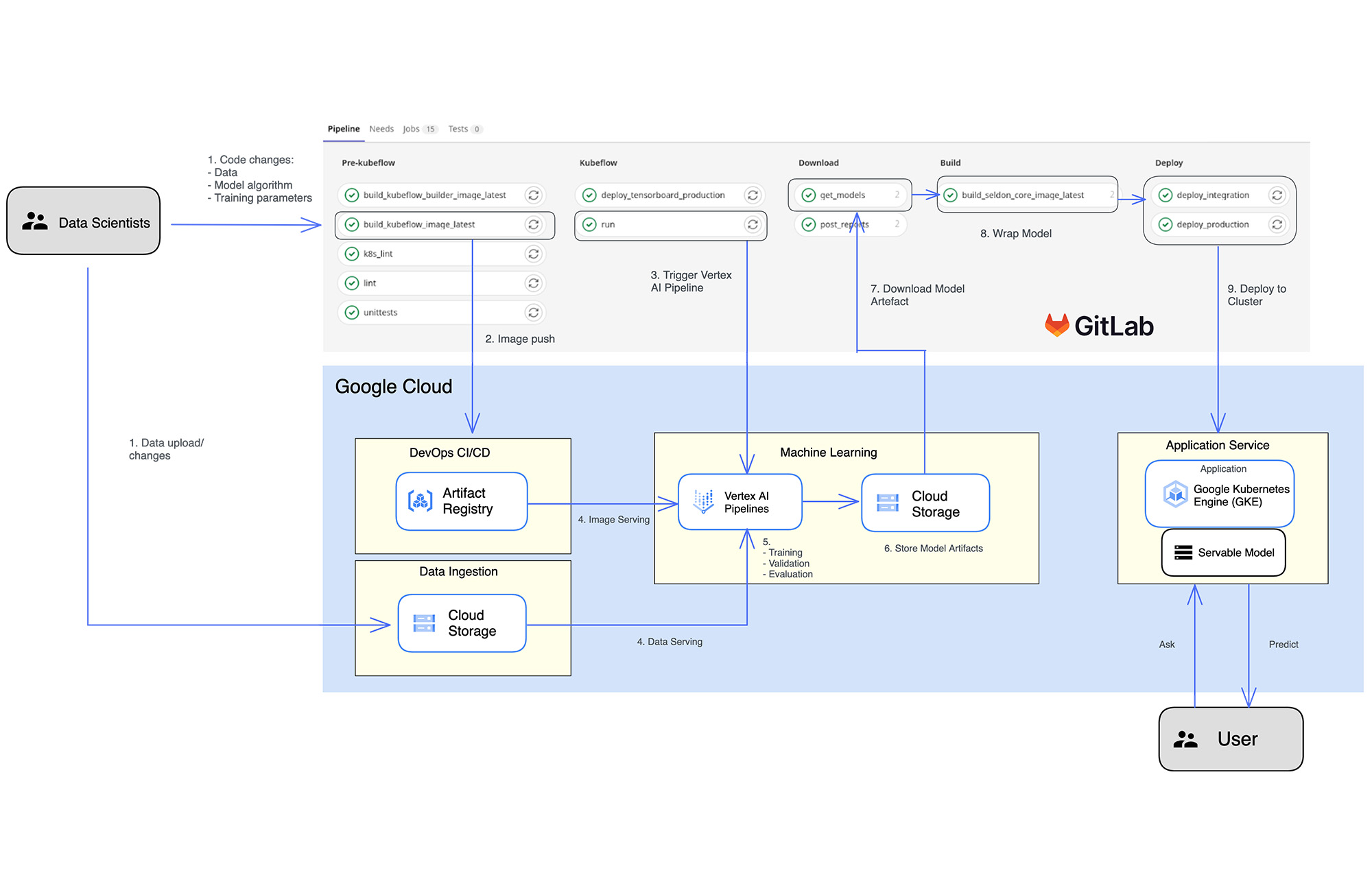
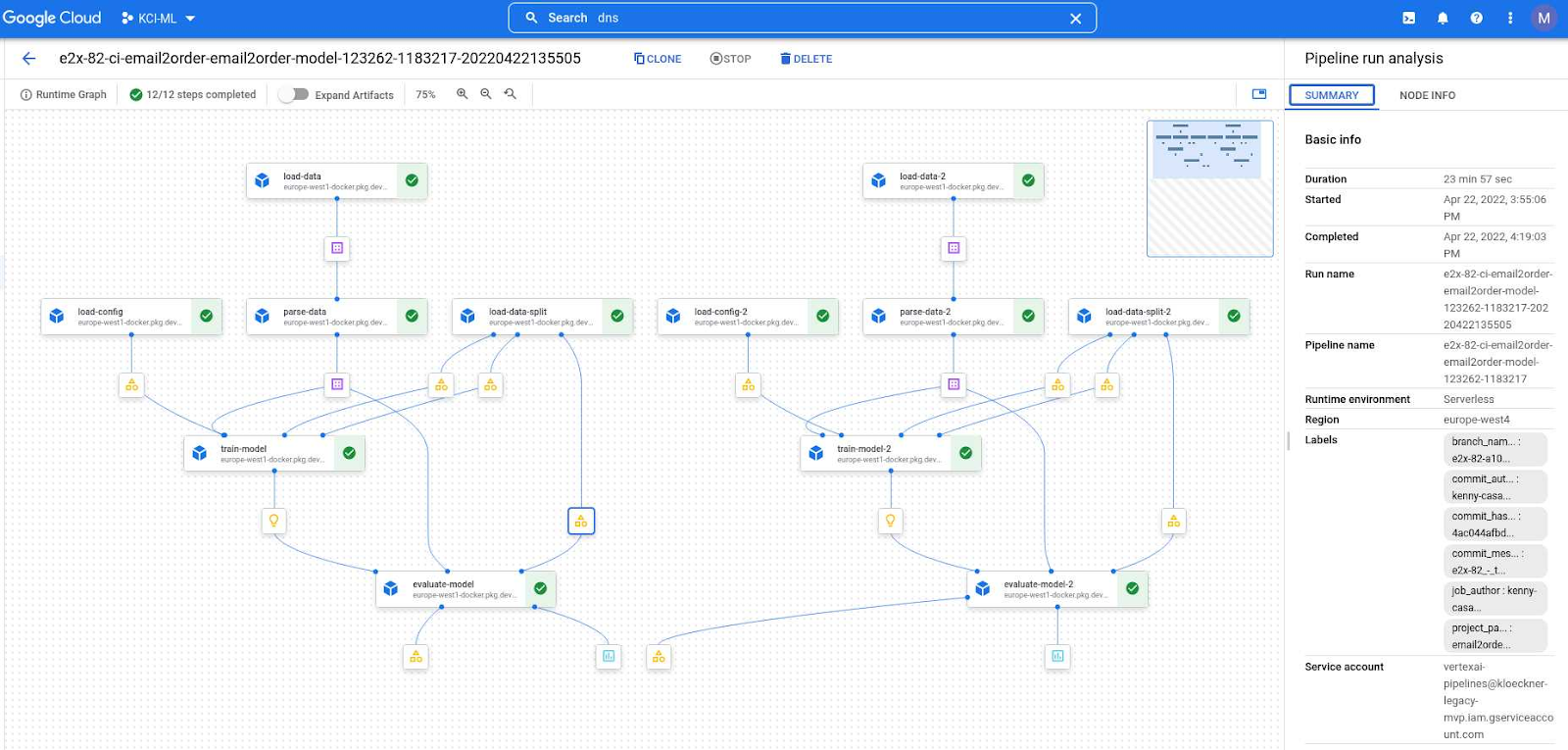
The data science team learned to use Vertex AI Pipelines with the KFP SDK. It took a bit of training on how to use it most efficiently, such as having several pipelines in parallel instead of one big one. It is being done with splitting pipelines automatically depending which language the data has (i.e. split by label that represent language/country) as seen below:
To overcome the security issues with virtual machines, data scientists only use short-termed Jupyterlab instances on Vertex AI Workbench. By convention, the lifetime of such an instance is limited to one ticket or task (whenever someone creates a new ticket, they will receive the latest version). Google manages the machine images (as well as security updates) and data scientists can concentrate on their actual work again.
The improvements that Vertex AI brought to Klökner’s ML workflows have been significant. Experiments that are formalized into components are easier to share and reproduce. Also, parallel training is straightforward to set up using the predefined components and pipelines that they build with the help of their partner, dida. Moreover, the impact gets even more tangible looking at concrete process improvements. With Vertex AI, the time required for developing and training models was significantly reduced. Whereas the initial IEPO model, developed on machines of individual ML experts, could take many days or weeks, it now takes hours to get through first iterations. And with a defined workflow and standard components that have transparent inputs and outputs, human errors are significantly reduced. There are fewer hidden black boxes and more sharing and collaborations. All of this helped to have a purchase order fully processed into their ERP system in several minutes instead of half a day on average.
What’s next?
The teams at Klöckner don’t see their work done yet. Now that they have declared workflows including Vertex AI as their “gold standard,” the plan is to port other ML workloads and previously trained models to Vertex AI. And of course, there is plenty of room for further improvement and optimization in their ML pipelines, such as automatically triggering continuous training pipelines when new data arrives. Similarly, on the serving side, model registration and live deployment of an improved model if committed to master (after metrics comparison and acceptance test) could be brought fully onto Vertex AI and automated as well (e.g., via Model Registry & Vertex AI Endpoints). Additionally, runtime metrics can be tracked to know how a model behaves and data drift detection can provide better understanding of when it's time for retraining.
And last but not least, Klöckner has many ideas already for new ML use cases to simplify and accelerate their processes (e.g., a model that understands when a customer says “Hey, please execute the same order as last time”). With whatever comes next, one thing is for sure: with Google Cloud and its Vertex AI platform they have powerful technologies and resources to continue being a front runner of their industry.
Further Links / Material:
Coursera course - ML Engineering for Production
More MLOps related articles / best practices…
We would like to thank Matthias Berkenkamp (former Sr. DevOps employee of Klöckner), Martin Schneider (Klöckner), Kenny Casagrande (Klöckner) and Kai Hachenberg (Google Cloud) for their help in creating this blog post.



