Reimagining AutoML with Google research: announcing Vertex AI Tabular Workflows

Alex Martin
Product Manager, Vertex AI
Earlier this year, we shared details about our collaboration with USAA, a leading provider of insurance and financial services to U.S. military members and veterans, who leveraged AutoML models to accelerate the claims process. Boasting a peak 28% improvement relative to baseline models, the automated solution USAA and Google Cloud produced can predict labor costs and car part repair/replace decisions based on photos of damaged vehicles, potentially redefining how claims are assessed and handled.
This use case combines a variety of technologies that extend well beyond the insurance industry, among them a particularly sophisticated approach to tabular data, or data structured into tables with columns and rows (e.g., vehicle make/model and points of damage, in the case of USAA). Applying machine learning (ML) to tabular data can unlock tremendous value for businesses of all kinds, but few tools have been both user-friendly and appropriate for enterprise-scale jobs. Vertex AI Tabular Workflows, announced at Google Cloud Applied ML Summit, aims to change this.
Applying Google AI research to solving customer problems
Google’s investment in rigorous artificial intelligence (AI) and ML research makes cutting-edge technologies not only more widely available, but also easier to use, faster to deploy, and efficient to manage. Our researchers publish over 800 papers per year, generating hundreds of academic citations. Google Cloud has successfully turned the results of this research into a number of award-winning, enterprise-grade products and solutions.
For example, Neural Architecture Search (NAS) was first described in a November 2016 research paper and later became Vertex AI NAS, which lets data science teams train models with higher accuracy, lower latency, and low power requirements. Similarly, Matching Engine was first described in an August 2019 paper before translating into an open-sourced TensorFlow implementation called ScaNN in 2020, and then into Vertex AI Matching Engine in 2021, which helps data teams address the “nearest neighbor search” problem. Other recent research-based releases include the ability to run AlphaFold, DeepMind’s revolutionary protein-folding system, on Vertex AI.
In tabular data, the research into evolutionary and “learning-to-learn” methods led to the creation of AutoML Tables and AutoML Forecast in Vertex AI. Data scientists and analysts have enjoyed using AutoML for its ability to abstract the inherent complexity of ML into simpler processes and interfaces without sacrificing scalability or accuracy. They can train models with fewer lines of code, harness advanced algorithms and tools, and deploy models with a single click. A number of high-profile customers have already successfully reaped the benefits of our AutoML products.
For example, Amaresh Siva, senior vice president for Innovation, Data and Supply Chain Technology at Lowe's said, “Using Vertex AI Forecast, Lowe's has been able to create accurate hierarchical models that balance between SKU and store-level forecasts. These models take into account our store-level, SKU-level, and region-level inventory, promotions data and multiple other signals, and are yielding more accurate forecasts.”
These and many other success stories helped Vertex AI AutoML become the leading Automated Machine Learning Framework in the market, according to the Kaggle “State of Data Science and Machine Learning 2021” report.
Expanding AutoML with Vertex AI Tabular Workflows
While we have been thrilled by adoption of our AI platforms, we are also well aware of requests for more control, flexibility and transparency in AutoML for tabular data. Historically, the only solution to these requests was to use Vertex AI Custom Training. While it provided the necessary flexibility, it also required engineering the entire ML pipeline from scratch using various open source tools, which would often need to be maintained by a dedicated team. It was clear that we needed to provide options “in the middle” between AutoML and Custom Training—something that is powerful and leverages Google’s research, yet is flexible enough to allow many customizations.
This is why we are excited to announce Vertex AI Tabular Workflows - integrated, fully managed, scalable pipelines for end-to-end ML with tabular data. These include AutoML products and new algorithms from Google Research teams and open source projects. Tabular workflows are fully managed by the Vertex AI team, so users don’t need to worry about updates, dependencies and conflicts. They easily scale to large datasets, so teams don’t need to re-engineer infrastructure as workloads grow. Each workflow is paired with an optimal hardware configuration for best performance. Lastly, each workflow is deeply integrated with the rest of Vertex AI MLOps suite, like Vertex Pipelines and Experiments tracking, allowing teams to run many more experiments in less time.
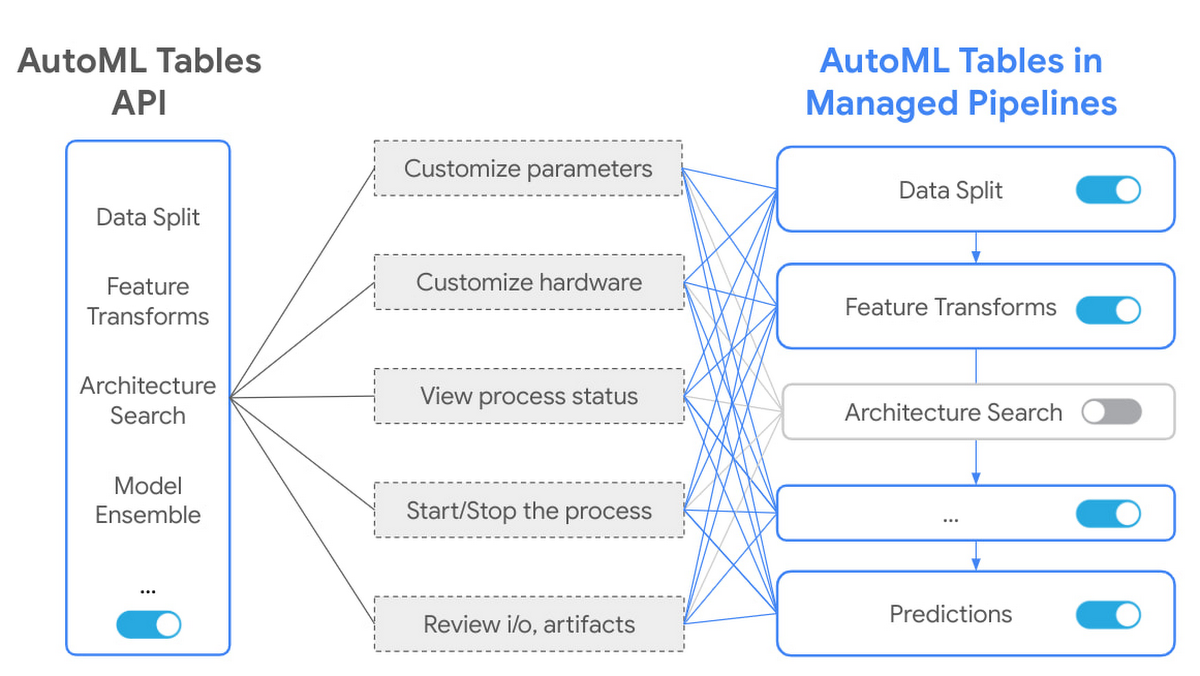
AutoML Tables workflow is now available on Vertex AI Pipelines, bringing many powerful improvements, such as support for 1TB datasets with 1,000 columns, and the ability to control model architectures evaluated by the search algorithm and change the hardware used in the pipeline to improve training time. Most importantly, each AutoML component can be inspected in a powerful pipelines graph interface that lets customers see the transformed data tables, evaluated model architectures and many more details.
Every component now also gets extended flexibility and transparency, such as being able to customize parameters, hardware, view process status, logs and more. Customers are taken from a world with controls for the whole pipeline into a world with controls for every step in the pipeline.
Google’s investment in tabular data ML research has also led to the creation of multiple novel architectures such as TabNet, Temporal Fusion Transformers and Wide & Deep. These models have been well received by the research community, resulting in hundreds of academic citations. We are excited to offer fully managed, optimized pipelines for TabNet and Wide & Deep in Tabular Workflows. Our customers can experience the unique features of these models, like built-in explainability tools, without worrying about implementation details or selecting the right hardware.
New workflows are added to help improve and scale feature engineering work. For example, our Feature Selection workflow can quickly rank the most important features in datasets with over 10,000 columns. Customers can use it to explore their data or combine it with TabNet or AutoML pipelines to enable training on very large datasets. We hope to see many more interesting stories of customers using multiple Tabular Workflows together.
Vertex AI Tabular Workflows makes all of this collaboration and research available to our customers, as an enterprise-grade solution, to help accelerate the deployment of ML in production. It packages the ease of AutoML along with the ability to interpret each step in the workflow and choose what is handled by AutoML versus by custom engineering. Managed AutoML pipeline is glassbox, letting data scientists and engineers see and interpret each step in the model building and deployment process, including the ability to flexibly tune model parameters and more easily refine and audit models.
Elements of Vertex AI Tabular Workflows can also be integrated into existing Vertex AI pipelines. We’ve added new managed algorithms including advanced research models like TabNet, new algorithms for feature selection, model distillation and much more. Future noteworthy components will include implementation of Google advanced models such as Temporal Fusion Transformers, and popular open source models like XGBoost.
Today’s research projects are tomorrow’s enterprise ML catalysts
We look forward to seeing Tabular Workflows improve ML operation across multiple industries and domains. Marketing budget allocations can be improved because feature ranking can identify well performing features from a large variety of internal datasets. These new features can boost the accuracy of user churn prediction models and campaign attributions. Risk and fraud operations can benefit from models like TabNet, where built-in explainability features allow for better model accuracy while satisfying regulatory requirements. In manufacturing, being able to train models on hundreds of gigabytes of full, unsampled sensor data can significantly improve the accuracy of equipment breakdown predictions. A better preventative maintenance schedule means more cost-effective care with fewer breakdowns. There is a tabular data use case in virtually every business and we are excited to see what our customers achieve.
As our history of AI and ML product development and new product launches demonstrate, we’re dedicated to research collaborations that help us productize the best of Google and Alphabet AI technologies for enterprise-scale tasks and workflows. We look forward to continuing this journey and invite you to check out the keynote from our Applied ML Summit to learn more.




