How Glance is collaborating with Google to build a next-level recommendation engine for its gaming platform, Nostra
Paul Duff
Consultant, Data Sciences, Glance, Nostra, InMobi
Gopala Dhar
AI Engineering Lead, Google Cloud Consulting
Mobile gaming has exploded in popularity in recent years, with billions of people around the world playing games on their smartphones and tablets. Glance, a subsidiary of InMobi, is one of the world’s largest lock screen platforms with over 220 million active users. Redefining the way people use their mobile phone lock screen, over 400 million smartphones now come enabled with Glance’s next-generation internet experience. Glance aims to increase user adoption of Nostra, their mobile gaming platform, by providing personalized game recommendations to users. Nostra currently has a few hundred games, with over 75 million monthly active users and a rapidly-growing user base.
Glance and Nostra had an urgent need to recommend and personalize the games displayed on the user's lock screen, in order to improve the overall user experience. They turned to Google Cloud to build recommendation systems to personalize their gaming content according to the user's preferences.
Let’s take a deep dive into the recommendation system and the various Google AI technologies that were implemented to build the solution.
The historical dataset
Historical interactions on Glance that users had voluntarily provided, compliant with privacy guidelines, produced the following datasets:
User metadata: Information on the user, such as the unique user ID, the handset details, and the manufacturer details.
Game metadata: Information regarding the games, such as their name, version, description, and unique game ID. The dataset also contained secondary information, such as which regions the game was released in and the game’s category and subcategory.
User-Game interaction data: Interaction data, i.e. data capturing the unique user ID, the unique game ID, the interaction start time, the duration of interaction, and the game version.
These were the primary data sources used further for analysis, experimentation, and ultimately modeling. These datasets were partitioned by time, and in the spirit of experimentation, we considered a data chunk of 30 days for the solution approach.
Identifying data trends
We observed the plots of session duration vs. the number of events. From those, we decided to remove user interaction events that were less than two seconds long, as these events were likely unintentional or accidental.
Another interesting trend we observed was that the majority of the sessions occurred at night, followed by events that occurred after midnight.
We also observed that some games had a relatively higher median session interaction duration compared to other games, which was expected.
Dealing with the outliers
For the given interaction dataset, the observed value of the session duration varied across the board. Consequently, we observed outliers on both ends of the session duration spectrum.
As mentioned earlier, the minimum possible session duration was capped at two seconds, and any lower values were discarded. Through mathematical analysis, we also affixed a certain maximum session duration to be the representative value for a single session interaction; any value higher than this was considered spurious.
Splitting the data
We used 30 days' worth of data, but to fairly and accurately access the recommendation system, we needed to fix the data split methodology.
We considered several approaches, including the following:
Random split in 80/10/10 fashion. This might lead the model to preemptively learn trends from the future and ultimately cause data leakage.
Split stratified based on unique games/users. This would lead to the cold-start problem with a collaborative filtering approach.
Split based on a “last one out” strategy, which would imply we consider only (N-1) games with which the user interacted, keeping the last game for the test set. This would cause data leakage across the temporal dimension.
Data split stratified over N weeks, as we did explore some weekly trends. Hence, the first N weeks can be considered as a training set, and subsequent sets can be for testing and validation. This split type is also known as global-temporal-split.
Since the number of games was less than the number of users, we considered all the games across sets, i.e., all N games should be considered that have at least *one* user interaction per each set train/test/validation (or at least three user interactions in total).
We chose the fourth approach, global temporal split, where we first ordered the data chronologically, then defined the split interval and created the train, test, and evaluation splits. This way, we could avoid temporal data leakage and ensure that the trends were being captured properly across all users.
Preprocessing the data
The next logical step was to scale the values. However, due to the non-normal nature of the distribution, we could not perform any normalization, so we thus went with the approach of median centering over the aggregated duration.
The aggregated duration was calculated by summing the total interaction time between a unique user-game pair across all sessions, per split set, so each set had train, test, and evaluation.
In this approach, we selected the median sum of the duration of the training distribution and used it within a formula to scale the values down. Scaling the values ensured that the model we trained would be able to converge swiftly; it also ensured that all values that were lesser than the median were transformed as negative numbers and that all values above the median were transformed as positive numbers.
Experimentation and modeling approaches
We experimented deep and wide to find the best-fit solution for this use case. The experiments that we conducted included methods such as matrix factorization, two tower modeling through Vertex AI and TFRS implementation, and reinforcement learning.
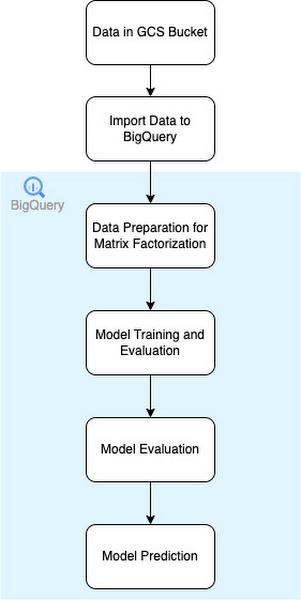
Matrix factorization through BQML - Matrix factorization is a class of collaborative filtering algorithms used in recommender systems. Matrix factorization algorithms work by decomposing the user-item interaction matrix into the product of two lower-dimensionality rectangular matrices. BQML offers matrix factorization out of the box. This model only requires us to write SQL scripts to create a model and start training the same. BQML implements the WALS algorithm to decompose the user-item interaction matrix.
This was the baseline model that was created and trained, and the feature we considered was the aggregate session duration for each user-game interaction.
This model performed quite well, and after hyper-parameter tuning, it was the model with the best scores for test and evaluation sets. The following diagram describes the flow of data in the BigQuery pipeline:
Two Tower Embedding Algorithm with Vertex AI matching engine - This is an embedding-based approach to build the recommendation system. The two-tower approach is a ranking model that uses a query tower and a candidate tower to generate embeddings of the query and its related candidate passed on to their respective towers. The generated embeddings are then represented in a vector embedding space.
Embedding-based models use the user and the item context to create a well-informed embedding in a shared vector space. In our experimentation approach, we considered numerous combinations of user features and game features to construct the embeddings. The best results were observed when the game embeddings included the category and the user embeddings included the temporal features, such as the day of the week and the time of the day.
After these embeddings were created, we created a Vertex AI Matching Engine Index. Vertex AI Matching Engine provides the industry's leading high-scale low latency vector database (a.k.a, vector similarity-matching or approximate nearest neighbor service). More specifically, given the query item, Matching Engine finds the most semantically similar items from a large corpus of candidate items.
Utilizing this, we created indexes for Bruteforce search and Approximate Nearest Neighbour Search. Then, we performed a series of experimentations with various distance metrics, including dot product, cosine similarity, etc. The results from these experimentations concluded that we may require additional modeling and additional contextual data to make the embedding model perform better.
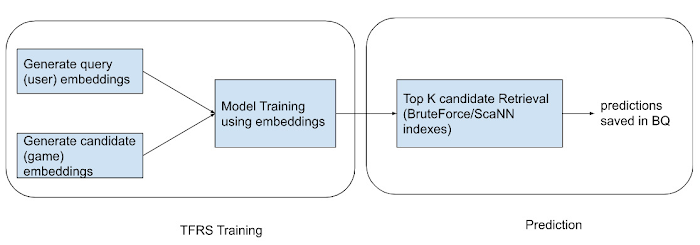
Custom modeling with TFRS - TensorFlow Recommenders (TFRS) is a library for building recommender system models. It is built on top of TensorFlow and streamlines the process of building, training, and deploying recommender systems.
The TFRS retrieval model built for this approach was composed of two sub-models viz, a query model (UserModel) computing the query representation using query features, and a candidate model (GameModel) computing the candidate representation using the candidate features. The outputs of the two models were used to give a query-candidate affinity score, with higher scores expressing a better match between the candidate and the query. Similar to the VertexAI Two Tower approach, we conducted multiple experiments defining various user features and game features to create the embeddings, and created Indexes on Vertex AI Matching Engine.
Best results and generalization was observed when only the user features were considered and the no game feature was considered, so only the unique game ID was used as a reference to embed the unique games in the vector space. The index used for the analysis was a Brute Force one to recommend top K games. We used Brute Force as the search space was limited.
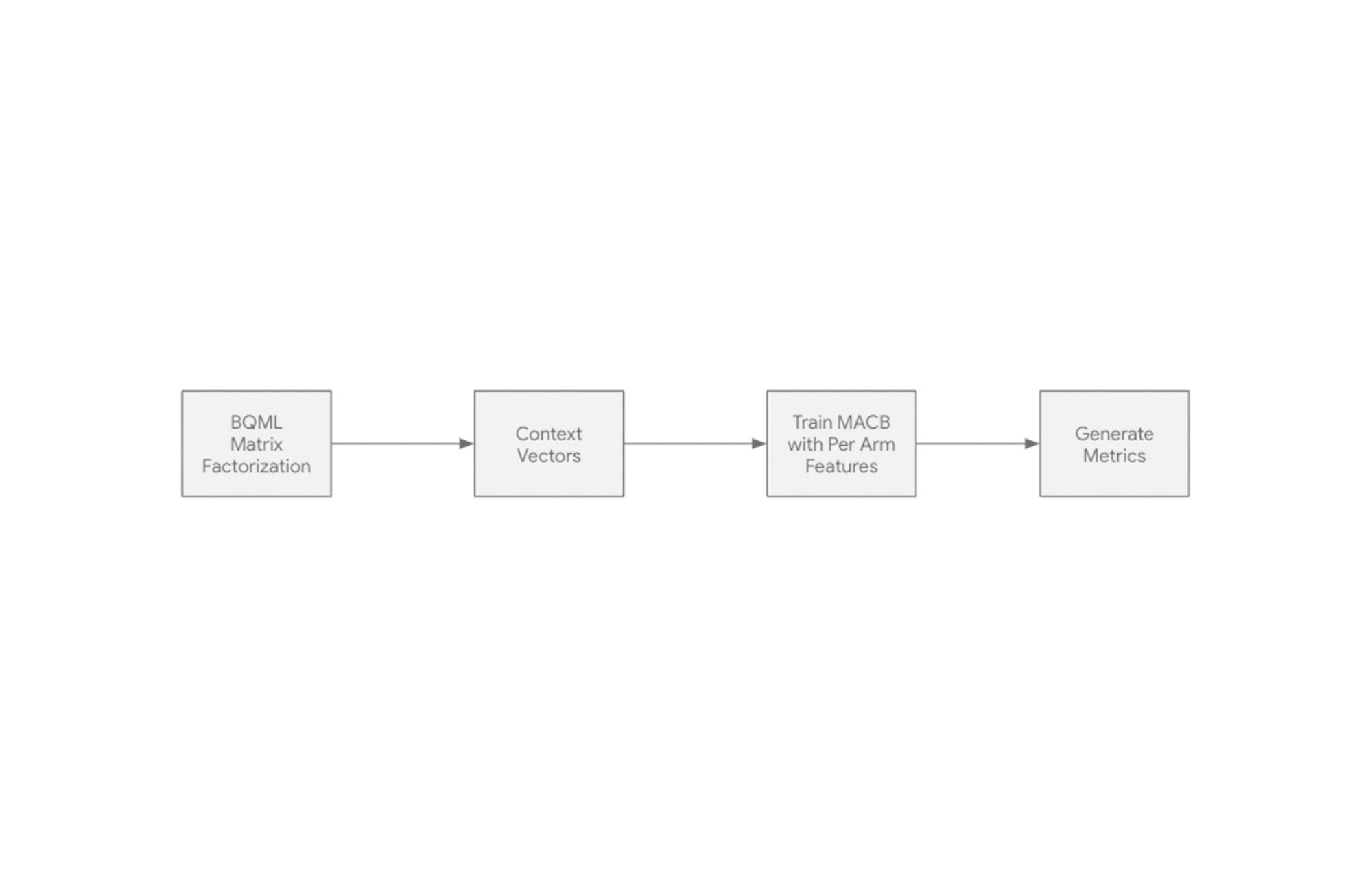
Reinforcement learning through contextual bandits - We implemented a multi-armed contextual bandit algorithm implemented through tf-agents. Multi-Armed Bandit (MAB) is a machine learning framework in which an agent has to select actions (arms) to maximize its cumulative reward in the long term. In each round, the agent receives some information about the current state (context), and then it chooses an action based on this information and the experience gathered in previous rounds. At the end of each round, the agent receives the reward associated with the chosen action.
In this approach, we utilize the Multi-Armed Contextual Bandit (MACB) modeling, with per-arm features, i.e. the learning agent has the option to choose games from one of the "arms" having their respective features. This helps in generalization as the user and the game context are embedded through a neural network.
In the methodology, the context was derived from the BQML matrix factorization model. We used an epsilon Greedy agent with a prespecified exploration factor, which ensured that the model is capable of learning trends as well as exploring beyond.
This model gave surprisingly good results, considering that it was only trained on a subset of 1 million unique users. The model gained exceptional generalizability from the limited training samples and was able to understand and map out the context space for a total of 19 million unique users.
This model was one of the top performers throughout this engagement, wherein it aimed at optimizing model metrics like the Sub-Optimal Arms Metrics and the Regret Metric. For experimentation of MACB we followed the following approach:
Experimentation metrics
In all of these experimentations we calculated four metrics:
Mean Average Precision at K (MAP)
Normalized Discounted Cumulative Gain at K (NDCG)
Average Rank
Mean Squared Error
The "K" here represents the number of results to be recommended. We experimented with values of K being 5, 10 and All.
These metrics were used to rank models across different modeling methodologies. However, out of these four metrics, we mainly focused on comparing the MAP and NDCG values, as they do a better job of representing the problem statement at hand.
Results and observations
With our best model, we observed a significant performance improvement compared to the baseline model used previously. The BQML Matrix Factorization model was the best performer, followed by the Contextual Bandits model, VertexAI Two Tower, and finally the TFRS approach. The embedding-based models suffered because of the lack of certain user demographic features in the given dataset. We also observed that as the K value increased, the model performance also increased, which is expected behavior.
Explaining the productionization and scaling approach of these models, the Nostra team initially deployed new models on a small percentage of traffic, comparing engagement metrics with control traffic in an A/B testing fashion. This deployment was tuned to ensure low latency output and to gain a deeper understanding of the key drivers behind user engagement. Once the model showed good performance, Nostra was positioned for further cost optimisations if required, and to scale the model to a larger percentage of traffic.
After this engagement, the Nostra team decided to implement the BQML Matrix Factorization model in production, after which they observed a preliminary increase in the time spent by the users interacting with the games on their platform.
Fast track end-to-end deployment with Google Cloud AI Services (AIS)
The partnership between Google Cloud and Glance is just one of the latest examples of how we’re providing AI-powered solutions to solve complex problems to help organizations drive the desired outcomes. To learn more about Google Cloud’s AI services, visit our AI & ML Products page.
Paul Duff, Consultant - Data Sciences with Nostra emphasized how happy he is with Cloud AIS and out-of-the-box products like BQML that helped get to productionable models in just a few weeks, stating, “The Google team was able to exceed our agreed objective to develop an offline recommendation system for Nostra, completing all milestones on or before time and delivering four fully documented working models. We were able to deploy the first of these in production (beyond the agreed project scope) and saw an uplift in our key metrics before the project end date. The organization of the team was exemplary with excellent communication throughout.”
We’d like to give special thanks to Naveen Poosarla and Charu Shelar for their support and guidance throughout the project. We are grateful to the Nostra team (Gaurav Konar, Rohit Anand and Rohith Kalyan) and our partner team from Wipro and Capgemini (Tulluru Durga Pravallika and Viral Gorecha) who partnered with us in delivering this successful project. And a special shout out to our super awesome leader Nitin Aggarwal.
Disclaimer: The information presented in this blog is intended to provide insights into a specific subset of data related to product usage metrics. It is important to note that the findings presented here may not necessarily reflect the overall product usage metrics.



