Getting started with Kubeflow Pipelines
Amy Unruh
Staff Developer Advocate
While model construction and training are essential steps to building useful machine learning-driven applications, they comprise only a small part of what you need to pay attention to when building machine learning (ML) workflows. To address that need, last week we announced AI Hub and Kubeflow Pipelines—tools designed with not only data scientists, but software and data engineers in mind—that help you build and share models and ML workflows within your organization and across teams, for integration into different parts of your business. Pipelines enable you to port your data to an accessible format and location, perform data cleaning and feature engineering, analyze your trained models, version your models, scalably serve your trained models while avoiding training or serving skew, and more. As your and your machine learning team’s expertise grows, you’ll find that these workflows need to be portable and consistently repeatable, yet have many ‘moving parts’ that need to be integrated.
Furthermore, most of these activities recur across multiple workflows, perhaps with only different parameter sets. Sometimes, you’ll run a set of experiments that needs to be performed in an auditable and repeatable manner. Other times, part or all of an ML workflow needs to run on-prem, but in still other contexts, it may be more productive to use managed cloud services, which make it easy to distribute and scale out the workflow steps, and to run multiple experiments in parallel.

Kubeflow is an open source Kubernetes-native platform for developing, orchestrating, deploying, and running scalable and portable ML workloads. It helps support reproducibility and collaboration in ML workflow lifecycles, allowing you to manage end-to-end orchestration of ML pipelines, to run your workflow in multiple or hybrid environments (such as swapping between on-premises and Cloud building blocks depending upon context), and to help you reuse building blocks across different workflows. Kubeflow also provides support for visualization and collaboration in your ML workflow.
Introducing Kubeflow Pipelines
Kubeflow Pipelines are a new component of Kubeflow that can help you compose, deploy, and manage end-to-end (optionally hybrid) machine learning workflows. Because they are a useful component of Kubeflow, they give you a no lock-in way to advance from prototyping to production. Kubeflow Pipelines also support rapid and reliable experimentation, so users can try many ML techniques to identify what works best for their application.
In this article, we’ll describe how you can tackle ML workflow operations with Kubeflow Pipelines, and then we’ll highlight some examples that you can try yourself. The examples revolve around a TensorFlow ‘taxi fare tip prediction’ model, with data pulled from a public BigQuery dataset of Chicago taxi trips.
We’re running the examples on Google Kubernetes Engine (GKE). GKE allows easy integration of GCP services that are relevant for ML workflows, including Cloud Dataflow, BigQuery, and Cloud ML Engine. (If you need to keep your ML workflows on-premises, you may also be interested in GKE On-PremALPHA).
The examples make use of TensorFlow Transform (TFT) for data preprocessing and to avoid training (or serving) skew, Kubeflow’s TFJob CRD (Custom Resource Definitions library) for supporting distributed training, and TensorFlow Model Analysis (TFMA) for analysis of learned models in conjunction with Kubeflow’s JupyterHub notebooks installation. These examples draw some of their code from the example in the TFMA repo.
These workflows also include deployment of the trained models to both Cloud ML Engine's online prediction service, and to TensorFlow Serving via Kubeflow.
We’ll describe all of these components in more detail below, then show how we can compose and reuse these building blocks to create scalable ML workflows that exhibit consistency, reproducibility, and portability.
Kubeflow components
The examples highlight how Kubeflow can help support your ML lifecycle, and make it easier to support hybrid ML solutions.
Kubeflow’s components include:
Support for distributed TensorFlow training via the TFJob CRD
The ability to serve trained models using TensorFlow Serving
A JupyterHub installation with many commonly-required libraries and widgets included in the notebook installation, included those needed for TensorFlow Model Analysis (TFMA) and TensorFlow Transform (TFT)
We use all of these in our examples, and describe them in more detail below. (Kubeflow also includes support for many other components not used in our examples.)
TFX building blocks
TensorFlow Extended (TFX) is a TensorFlow-based platform for performant machine learning in production, first designed for use within Google, but now mostly open sourced. You can find more of an overview here.
Kubeflow and our example ML workflows use three TFX components as building blocks: TensorFlow Transform, TensorFlow Model Analysis, and TensorFlow Serving.
TensorFlow Transform
TensorFlow Transform (TFT) is a library designed to preprocess data for TensorFlow—particularly for feature engineering. tf.Transform is useful for transformations that require a full pass of the dataset, such as normalizing an input value by mean and standard deviation, converting a vocabulary to integers by looking at all input examples for values, or categorizing inputs into buckets based on the observed data distribution.
Importantly, its use can also prevent training-serving skew, which is a problem that occurs when the feature preprocessing run on training data is not the same as that run on new data prior to prediction. It is easy for this inconsistency to arise when training and serving are managed by different teams, often using different compute resources and different code paths.
However, by using TFT for preprocessing, the output of tf.Transform is exported as a TensorFlow graph to use for both training and serving, and this TFT graph is exported as part of the inference graph. This process prevents training-serving skew, since the same transformations are applied in both stages. The example pipelines use TFT to support preprocessing, and this means that after the trained models are deployed for serving and we send a prediction request, the prediction input data is being processed in exactly the same way as was done for training, without the need for any client-side preprocessing framework.
TFT uses Apache Beam to run distributed data pipelines for analysis. Beam is an open source framework with a unified programming model for both batch and streaming use cases. Essentially, you build Beam pipelines that use the TFT transformations you want to perform.
Beam allows you to run your workloads on a choice of different execution engines, including a local runner, and Google Cloud Dataflow (Google Cloud’s managed service for running Beam pipelines). By default, the example pipelines use Beam’s local runner, but can transparently use Cloud Dataflow instead, by setting a configuration parameter. (For these examples, the default datasets are small, so running locally works fine, but for processing larger datasets, Cloud Dataflow lets you automatically scale out your processing across multiple workers.)
TensorFlow Model Analysis (and JupyterHub on Kubeflow)
The second TFX component used in the example workflows is TensorFlow Model Analysis (TFMA). TFMA is a library for evaluating TensorFlow models. It allows users to evaluate their models on large amounts of data in a distributed manner, using the same metrics defined for training. These metrics can be computed over different slices of data and visualized in Jupyter notebooks.
TFMA makes it easy to visualize the performance of a model across a range of circumstances, features, and subsets of its user population, helping to give developers the analytic insights they need to be confident their models will treat all users fairly.
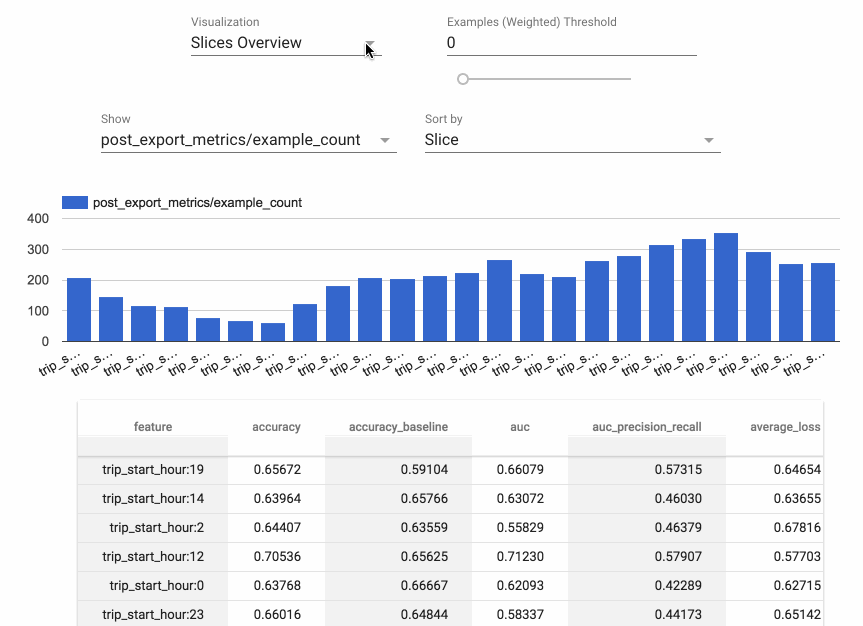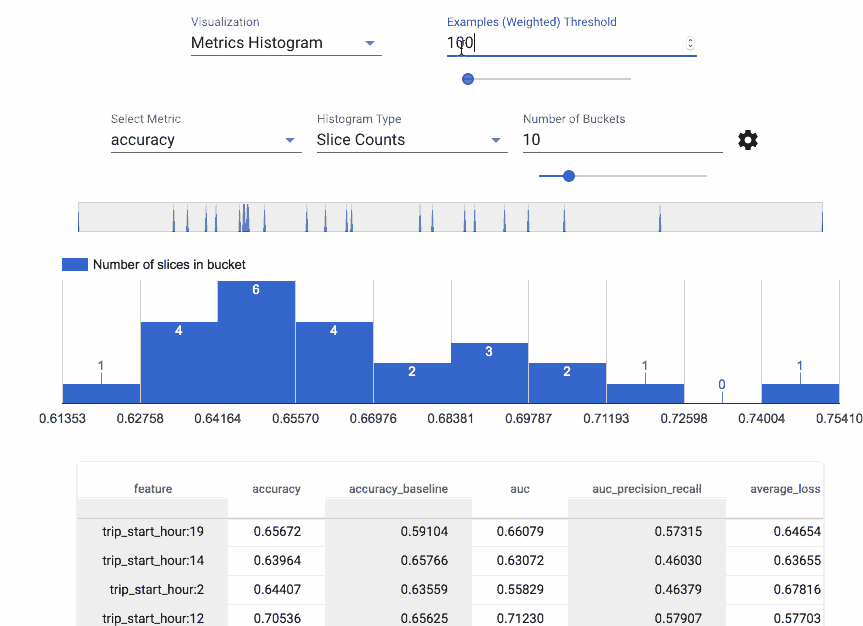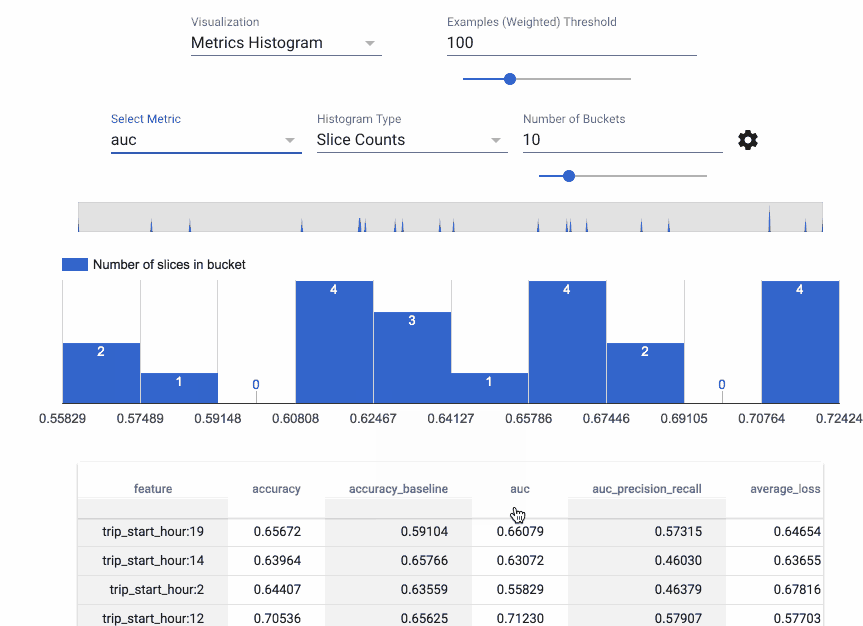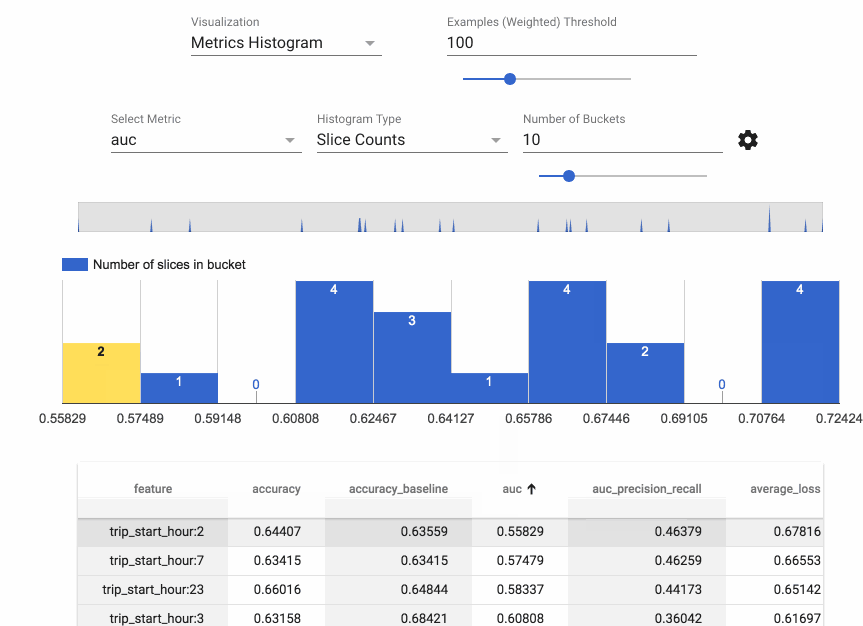
You can compute slices of interest as part of your main ML workflow, so that the results are ready to examine in a notebook environment—just as we demonstrate in these example workflows. Kubflow includes a JupyterHub installation with the necessary TFMA libraries and widgets installed, and this makes it very straightforward to explore the analysis results in a Kubeflow-supported Jupyter notebook. (Other TFX libraries are also installed, along with many other libraries useful to data scientists.)
As with TFT, Apache Beam is required to run distributed analysis, and just as with TFT, the example workflows support use of the Beam local runner, and can also be run on Cloud Dataflow. For the small example datasets, running Beam locally works fine.
TensorFlow Serving
TensorFlow Serving (often abbreviated as “TF-Serving”) is another TFX component, consisting of an open source library, binaries, and images for serving machine learning models. It deals with the inference aspect of machine learning, managing and serving trained models, and can even help if you need to serve your TensorFlow models on-prem. TensorFlow Serving is a Kubeflow core component, which means that it is installed by default when you deploy Kubeflow. One example shows how to deploy trained models to TF-Serving, and the example repo includes a client script that lets you make requests to the deployed TF-Serving models.
TensorFlow Data Validation
TensorFlow Data Validation (TFDV) is a library for exploring and validating machine learning data. It is designed to be highly scalable and to work well with TensorFlow and TensorFlow Extended (TFX). Its features include automated data schema generation to describe expectations about data like required values, ranges, and vocabularies. While the example pipelines do not invoke TFDV directly, the schema used by the TFT and TFMA pipeline steps was generated by TFDV.
Cloud ML Engine Online Prediction
Google Cloud ML Engine is a managed service for training and serving ML models: not only TensorFlow, but scikit-learn and XGBoost as well. Cloud ML Engine makes it easy to do distributed training and scalable serving, and it provides monitoring, logging, and model version management. You can use Cloud ML Engine services as key building blocks for many ML workflows.
For the examples described in this post, since we’re highlighting Kubeflow’s TFJob API, we’re not using Cloud ML Engine for training (though we could). However, we’re deploying the trained TensorFlow models to Cloud ML Engine online prediction service, which provides scalable serving—for example, if you’re accessing a model via an app you built, and the app becomes popular, you have no worries about your model serving infrastructure falling over when it gets a barrage of inbound requests.
The workflow deploys the trained models as versions of a specific model, in this case named taxifare. Once the model versions are deployed, we can make prediction requests against a specific version. The Google Cloud Platform Console lets you browse through the deployed versions of your different models, set one to be the default, and get information about when each was deployed and last accessed.
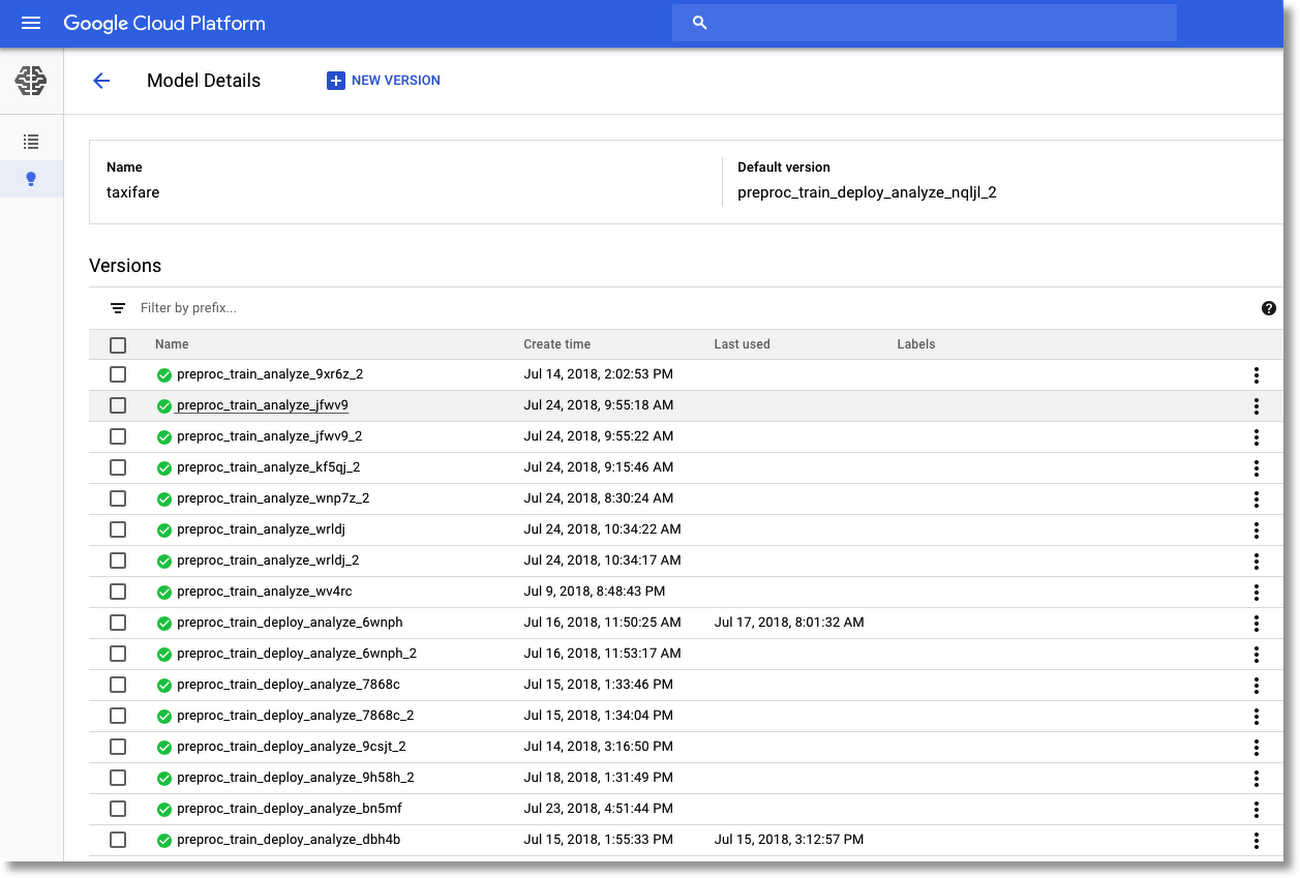
As mentioned above, our workflows use TensorFlow Model Analysis to analyze and compare the learned models, and we can use that information to select the best version as the default, the version served when you make an API request using just the taxifare model name. You can set the default version from the GCP Console, or via the gcloud command line utility.
Building workflows using Kubeflow Pipelines
The building blocks described above can be composed to support common and useful ML workflow patterns. They let you build pipelines that support data ingestion, feature pre-processing, distributed training, evaluation, and serving. Our examples show variants on this basic workflow, and illustrate how easy it is to create these variants via reusable building blocks. In this section, we’ll take a closer look at one of them.
Constructing a workflow using the Kubeflow Pipelines SDK
The Pipelines SDK lets you specify your ML workflows in a high-level language. Then, you compile and run your specifications.
Our first example workflow illustrates how you can use an ML workflow to experiment with TFT-based feature engineering, and how you can support a hybrid ML flow that serves your trained model from both on-prem and cloud endpoints.
The workflow runs two paths concurrently, using a different TFT preprocessing function for each path (preprocessing.py vs. preprocessing2.py). By designing the TFT workflow component to take the preprocessing function definition as an argument, it effectively becomes a reusable component that you can incorporate into any pipeline.
Then you can train each model variant, using Kubeflow’s TFJob CRD. For example purposes, distributed training is used for one path, leveraging TFJob’s support for easy distribution, and single-node training is used for the other. This distinction is made by specifying the number of workers and parameter servers to use for the training job.
Then, the workflow runs TFMA analysis on both trained models, so that they can be evaluated and compared, and at the same time deploys the trained models to both Cloud ML Engine and TF-Serving. With the use of TFT, the deployed models include the TFT-generated preprocessing graphs, so we don’t have to worry about training or serving skew, and by using modular building blocks, it becomes much easier to assemble experiments like these.
This example shows how you can support hybrid workflows, where, for example, your training runs on-premises (maybe you have some sensitive training data), and then you deploy to both your on-prem TensorFlow Serving cluster and Cloud ML Engine Online Prediction. It also shows how easy it is to scale out a Kubeflow TensorFlow training job, from a single-node to a large distributed cluster, by merely changing the job parameters.
The workflow graph looks like this:
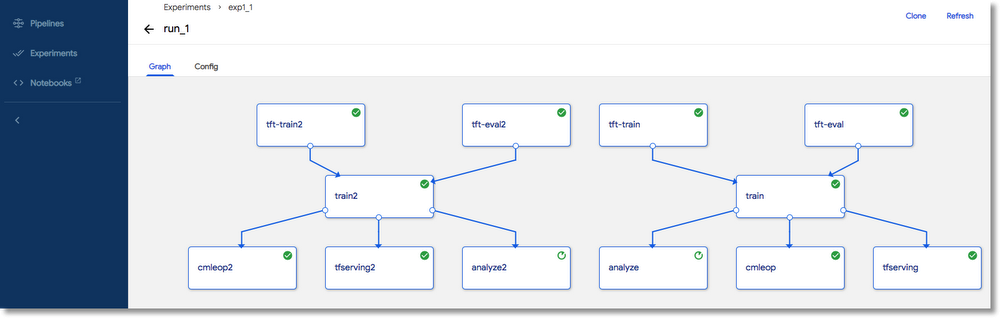
A rendering of a workflow for TFT-based feature engineering experimentation, via the Kubeflow Pipelines UI.
We’ll build this pipeline using the Kubeflow Pipelines SDK as follows. First, we define the workflow’s input parameters and defaults:
Next, we define the workflow’s component steps and their dependencies. For each component, we’re specifying a Docker container image, and the arguments to pass to the container’s endpoint. While not used here, you can also override the container endpoint by specifying a command to run, or specify output files written during the component’s execution. We will very soon be providing utilities that will, in many cases, eliminate the need for you to worry about Docker container creation. You will just provide your code and specify a base image to use, and Pipelines will take care of the rest.
We can now specify dependencies between the steps with the op.after() construct. See the Kubeflow Pipelines documentation for more explanation. For brevity, we omit detail for most of the step definitions, but the full Python script is here.
We’ll first define the TensorFlow Transform steps. There are four in total: two for each processing pipeline, to process train and evaluate data. We’re not specifying any dependencies between them, so they all run concurrently:
Next, we’ll define the ‘train’ steps. There are two, one for each TFT feature engineering variant. We’ll require that they run after their respective TFT components:
After the models are trained, we will run TFMA-based analysis on the results, and deploy the trained models to both the Cloud ML Engine online prediction service, and to TensorFlow serving. We again use the op.after() construct to indicate that all of these activities can happen concurrently after training of each model has finished.
See the Pipelines repo for more examples. It is also possible to author and deploy pipelines and pipeline components from within a notebook. We’ll describe that in a follow-on blog post.
Monitoring a workflow using the Pipelines UI
The Kubeflow Pipelines UI (user interface) provides support for monitoring and inspecting Pipeline specifications, experiments based on a given Pipeline, and multiple runs of an experiment. A specification like the one above is compiled, then uploaded via the UI.
After you’ve uploaded a pipeline definition, you can view the pipeline graph derived from your specification. (For pipelines with dynamically-generated steps, this initial graph will be refined at run-time). Then, you can start experiments based on that pipeline, and initiate or schedule multiple experimental runs.
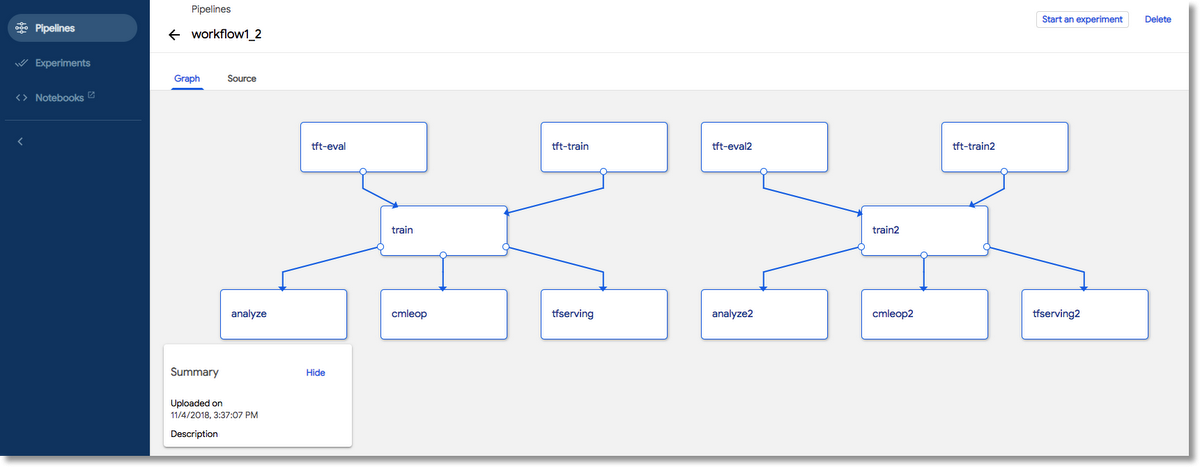
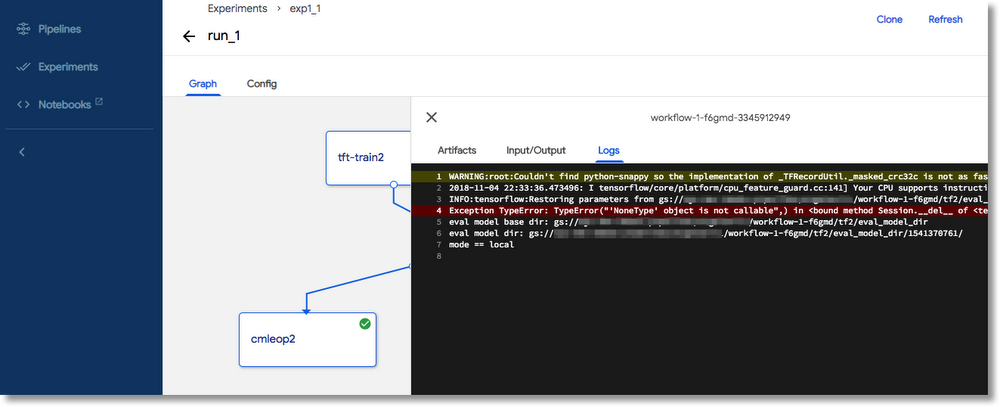
While an experiment run is in progress, or after it has finished, you can inspect the dynamically-generated graph, configuration parameters, and logs for the pipeline steps.
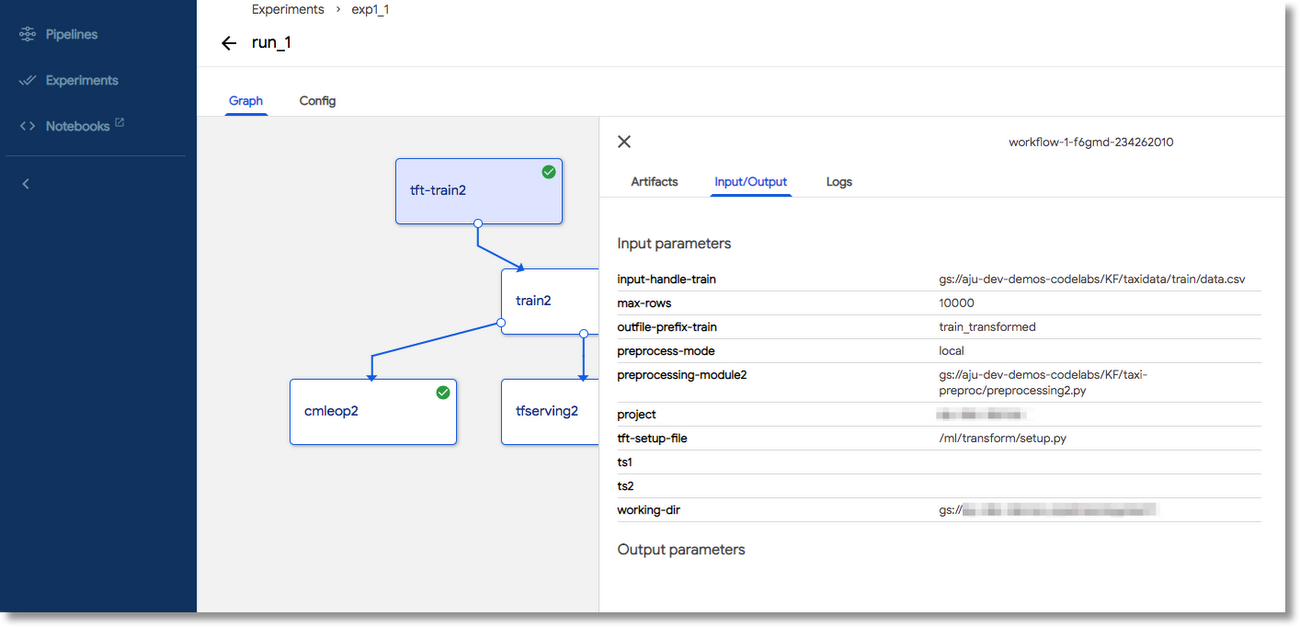
Inspecting the configuration of a TFT transformation step.
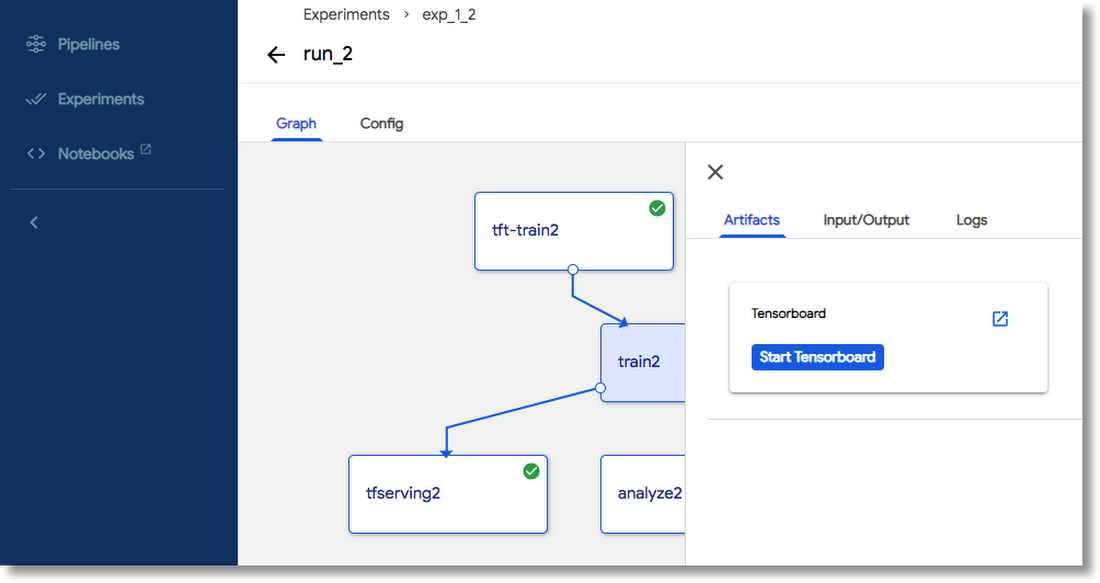
Use TensorBoard from the Kubeflow Pipelines UI
TensorBoard is a suite of web applications that help you inspect and understand your TensorFlow runs and graphs. If your pipeline includes TensorFlow training components, you can define these components to write metadata that indicates the location of output consumable by TensorBoard. The Pipelines UI uses this information to launch TensorBoard servers from the UI.
Here, we’re using TensorBoard to view the results of one of the training steps in the workflow above.
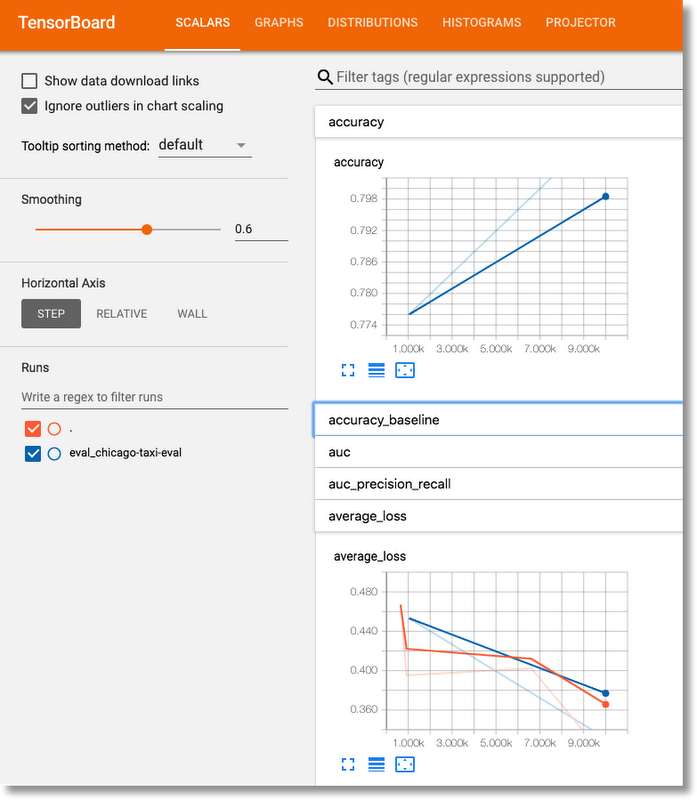
Use Kubeflow to visualize model analysis results in a Jupyter notebook
In our example workflows, we run TensorFlow Model Analysis (TFMA) on the trained models, using a provided specification of how to slice the data.
At any time after this workflow step has been run, you can visualize the TFMA results in a Jupyter notebook, making it easy to assess model quality or compare models.
Kubeflow’s JupyterHub installation makes this easy to do, via a port-forward to your Kubernetes Engine (GKE) cluster. The necessary libraries and visualization widgets are already installed. If you’re playing along, see the instructions here on connecting to JupyterHub via the Kubeflow Dashboard. Then load and run the tfma_expers.ipynb notebook to explore the results of your TFMA analysis.
Running the example workflows
To run the example workflows yourself, see the README, which walks you through the necessary installation steps and describes the code in more detail.
Above, we showed Workflow 1. We’ll take a quick look here at Workflow 2, which uses the same workflow components, but combines them in a different way.
Workflow 2
Workflow 2 shows how you might use TFMA to investigate relative accuracies of models trained on different datasets, evaluating against ‘new’ data. As part of the preprocessing step, it pulls data directly from the source BigQuery Chicago taxi dataset, with differing `min` and `max` time boundaries, effectively training on ‘recent’ data vs a batch that includes older data. Then, it runs TFMA analysis on both learned models, using the newest data for evaluation.
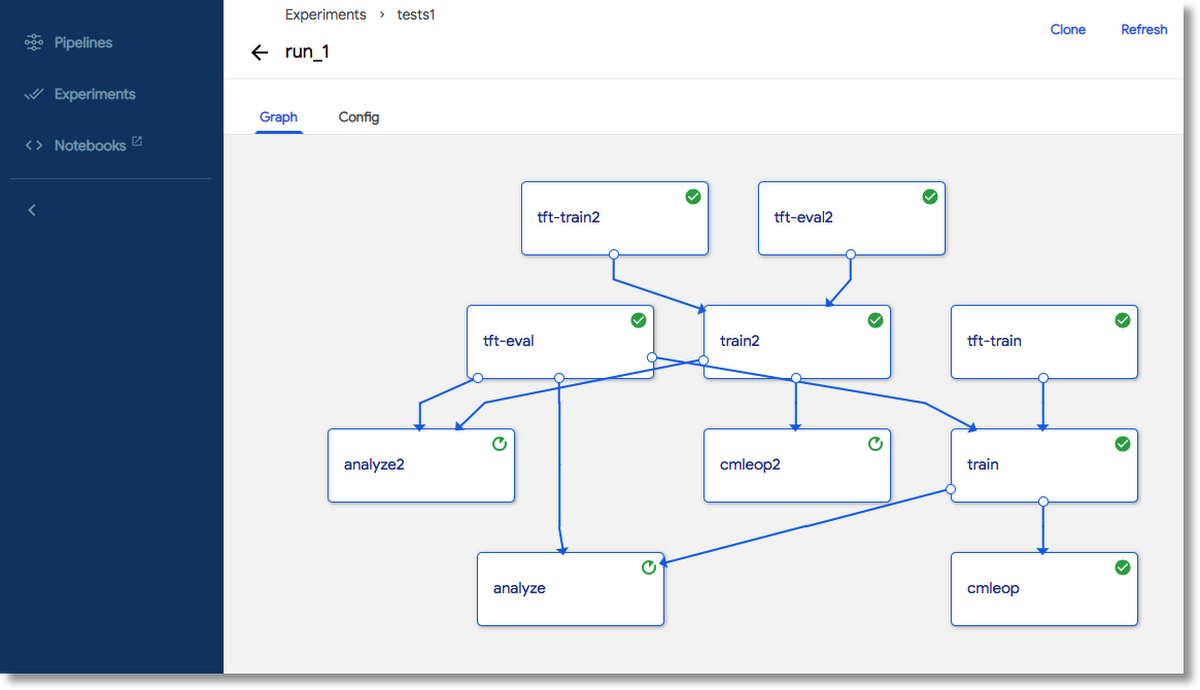
As with Workflow 1 above, the trained models are deployed to Cloud ML Engine Online Prediction, where you can then select the most accurate ones to use for prediction.
This example shows how you can define workflows to support consistent model regeneration and re-evaluation over sliding time windows of your data, to determine whether the characteristics of your new prediction data have changed. (While not shown as part of this example, you could alternatively use a similar workflow to support incremental training of an existing model on successive new datasets, and then compare that model with new models trained ‘from scratch.’)
The Pipelines SDK specification for Workflow 2 is here.
Use your models for online prediction with Cloud ML Engine
As part of both example workflows, the trained models are deployed to Cloud ML Engine’s online prediction service. The model name is taxifare, and the version names are derived from the workflow names. As shown above, you can view the deployed versions of the taxifare model in the GCP Console.
If you’re following along, it is easy to make a prediction using one of the deployed Cloud ML Engine model versions. Follow the instructions in this section of the README, then run the following command, replacing <CMLE_MODEL_VERSION_NAME>.
(This command requires that you have the gcloud sdk installed, or as described in the README, you can use your project’s Cloud Shell instead).
Make predictions using TF-Serving endpoints
The first example pipeline deployed the trained models not only to Cloud ML Engine, but also to TensorFlow Serving, which is part of the Kubeflow installation.
To facilitate a simpler demo, the TF-Serving deployments use a Kubernetes service of type LoadBalancer, which creates an endpoint with an external IP. However, for a production system, you’d probably want to use something like Cloud Identity-Aware Proxy.
You can view the TF-Serving endpoint services created by the pipeline by running:
from the command line. For this particular pipeline, look for the services with prefix workflow1 (its prefix), and note their names and external IP addresses.
It is easy to make requests to the TensorFlow Serving endpoints using a client script: you can find more detail in the README.
Should you want to scale a TF-Serving endpoint to handle a large number of requests, this is easy to do via Kubernetes' underlying capabilities: scale the Deployment backing the endpoint service.
Learn or contribute
We hope these examples encourage you try out Kubeflow and Kubeflow Pipelines yourself, and even become a contributor. Here are some resources for learning more and getting help:
More Kubeflow examples
Kubeflow’s weekly community meeting
Kubeflow Pipelines documentation
Please submit bugs and tell us what features you’d like to see!



