Document AI Workbench is now powered by generative AI to structure document data faster
Derek Egan
Product Manager, Vertex AI
Document AI helps businesses structure document data to automate processes, improve SLAs, reduce costs, and unlock insights by making analysis across documents possible. A critical part of document processing is the ability to customize results for enterprise-specific documents.
That’s why we launched Document AI Workbench. Document AI Workbench enables users to customize models for document processing tasks. In February 2023, we launched the Custom Extractor in General Availability (GA) to help users extract structured data from documents. In March 2023, we launched the Custom Classifier in GA to help automatically classify document types. In July, we launched the Custom Splitter in GA to help automatically split and classify multiple documents within a single file.
And now we are bringing powerful, new generative AI technologies to help make these custom document processing workflows even more productive. At Google Next ’23, we spoke about mobilizing document insights using generative AI and announced the public preview launches of two generative AI powered features in Document AI Workbench: Custom Extractor with generative AI and the Summarizer.
Custom Extractor with generative AI
Generative AI-powered extraction is now available, in public preview, within the Custom Extractor. Generative AI can help extract data from documents with lots of free form text (like contracts), with complex layouts (such as invoices, w2s, and bills of lading), or with little or no training data available.
The Custom Extractor with generative AI adds unique value:
- Faster time to market: post a document and fields you want to extract to an API endpoint to get structured data in return–no model training required to get started. An early customer was able to achieve within one hour what used to require days of effort to train a custom model. Plus, you don’t need to worry about converting documents to text, choosing or tuning a foundation model for documents, or chaining multiple generative AI tools together.
- Simple path to customize generative AI results for your documents (no generative AI expertise required) by simply confirming document content that Workbench automatically uses to improve your accuracy via few-shot predictions.
- Extract data from documents up to 200 pages long, out-of-the-box, without worrying about underlying models’ context windows or individual document chunks.
To get started, go to Document AI Workbench and create a Custom Extractor. Because a foundation model is now available in the Custom Extractor, you can call the endpoint out of the box with any document and the fields you want to extract to get structured data in return.
Or you can quickly customize and preview results for your documents. First, define fields that you want to extract and upload a sample document to preview results. Here are examples of what the generative model can extract from a couple of different documents without any training:
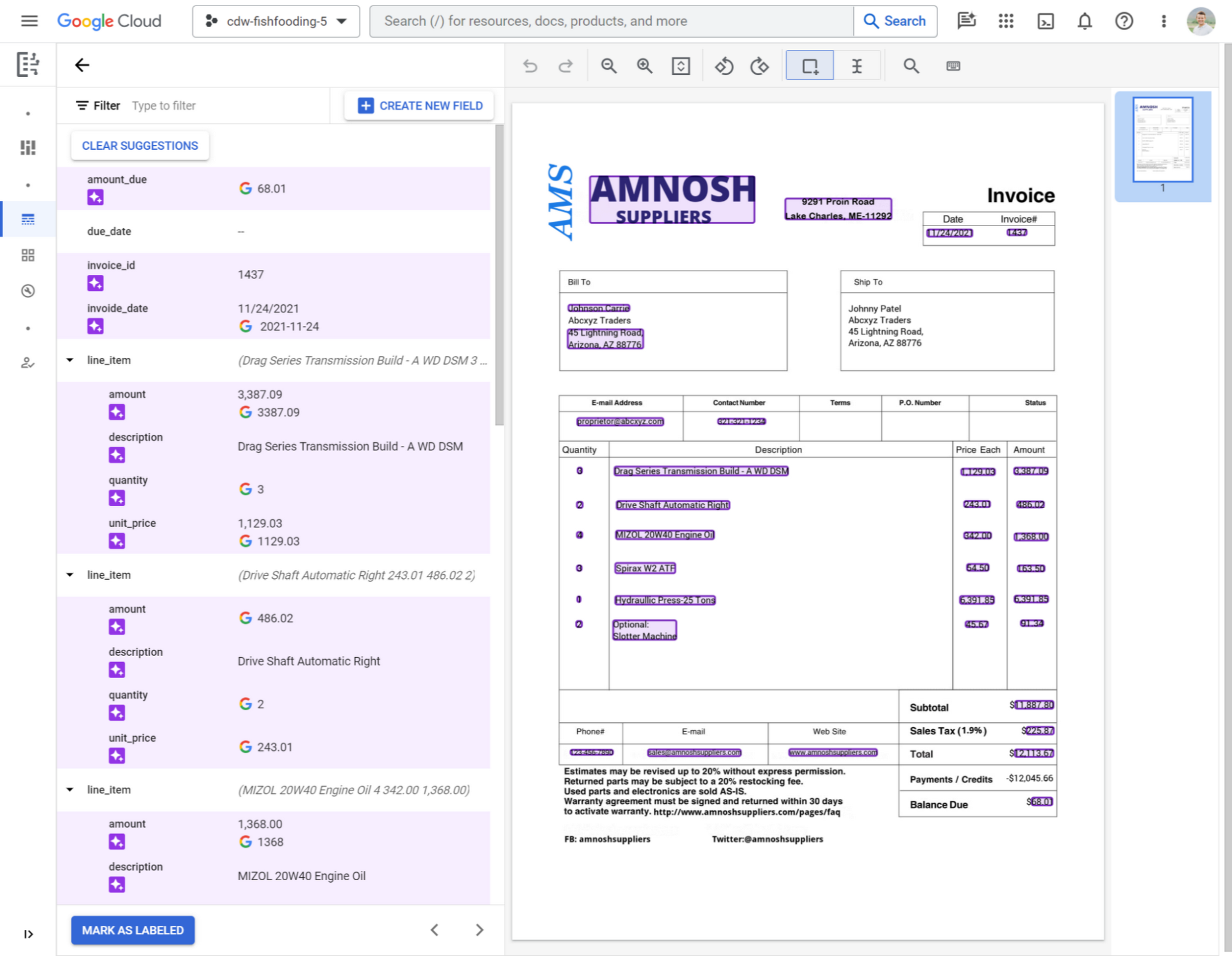
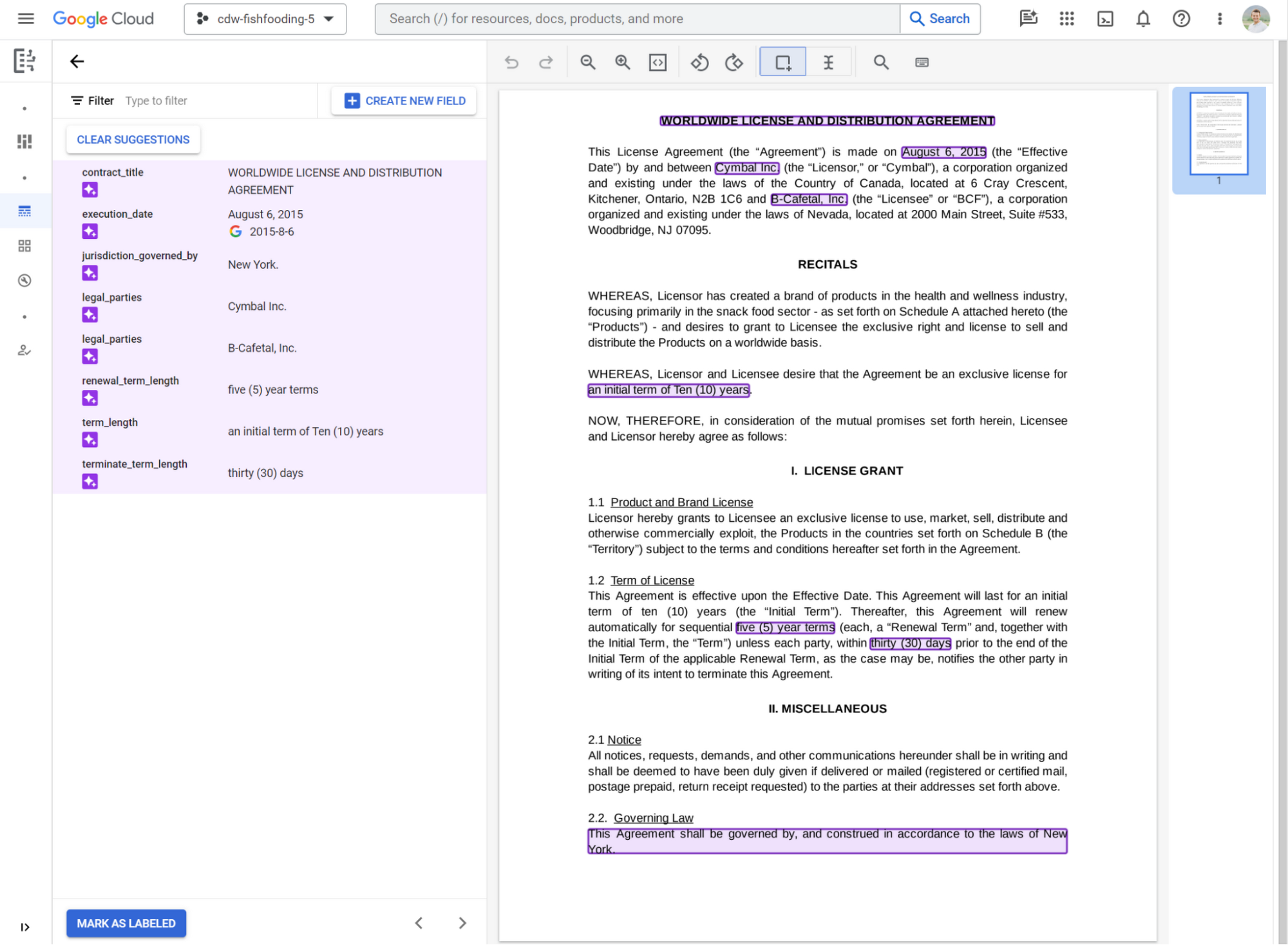
To improve accuracy, confirm or correct predictions and mark documents as labeled. If you import and confirm predictions for ~5 documents, Workbench automatically leverages the examples to improve model accuracy, for your exclusive use.
If you like the performance, then go to the build page and create a new version to call the foundation model using the fields defined and the document examples labeled in the dataset to power few-shot predictions. This way, you will get consistent performance from the model from your version’s endpoint.
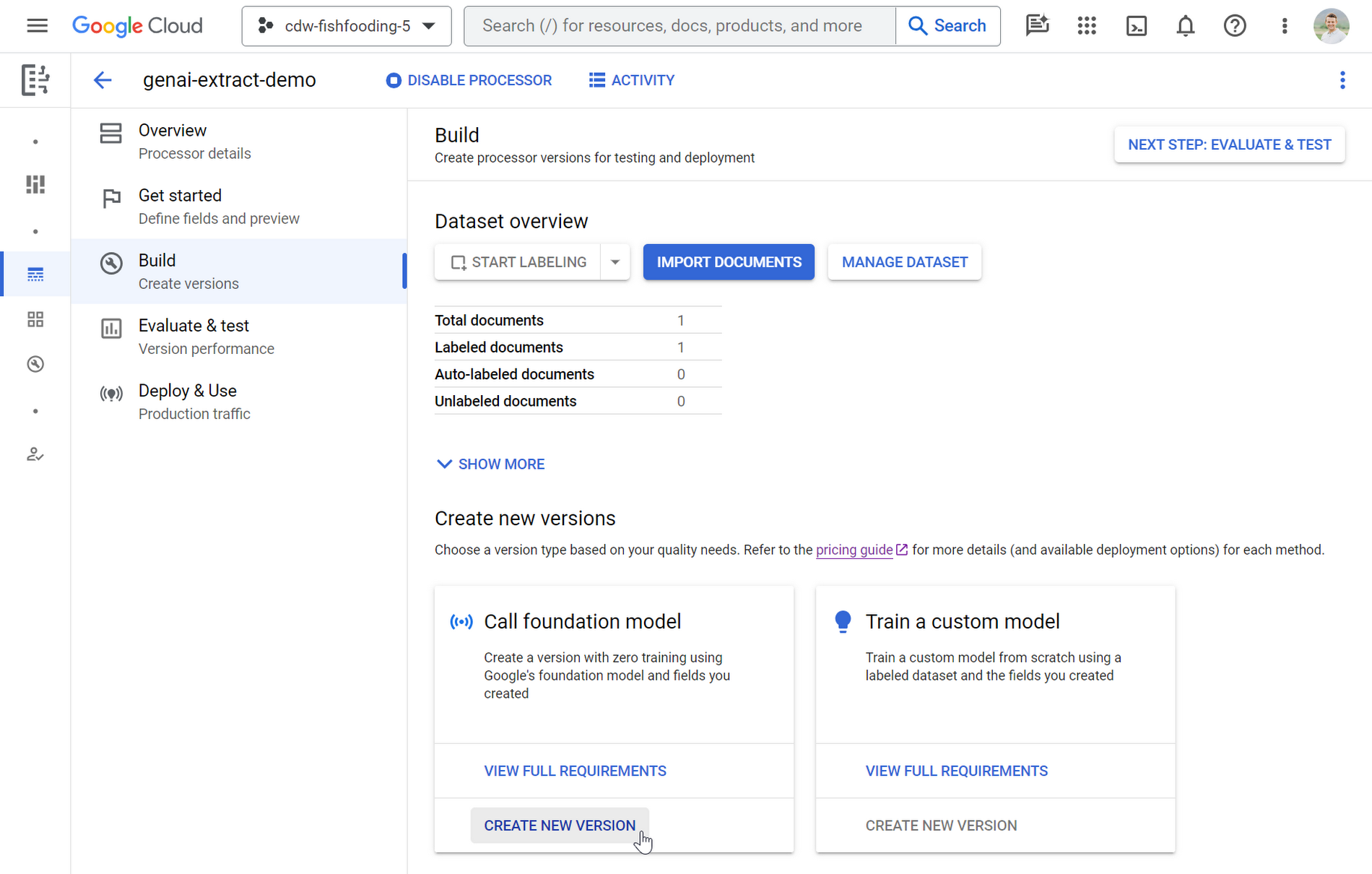
Use it to auto-label
To take quality to the next level, prepare a larger dataset. Use the foundation model to automatically label documents as you import them. Then review and confirm predictions in your dataset. A test set can be used to run evaluations of the generative-powered model. A training set can be used to continue training custom and template-based models within the “Train a custom model” option. Soon, you will be able to use your training set to perform parameter efficient fine tuning for the generative model.
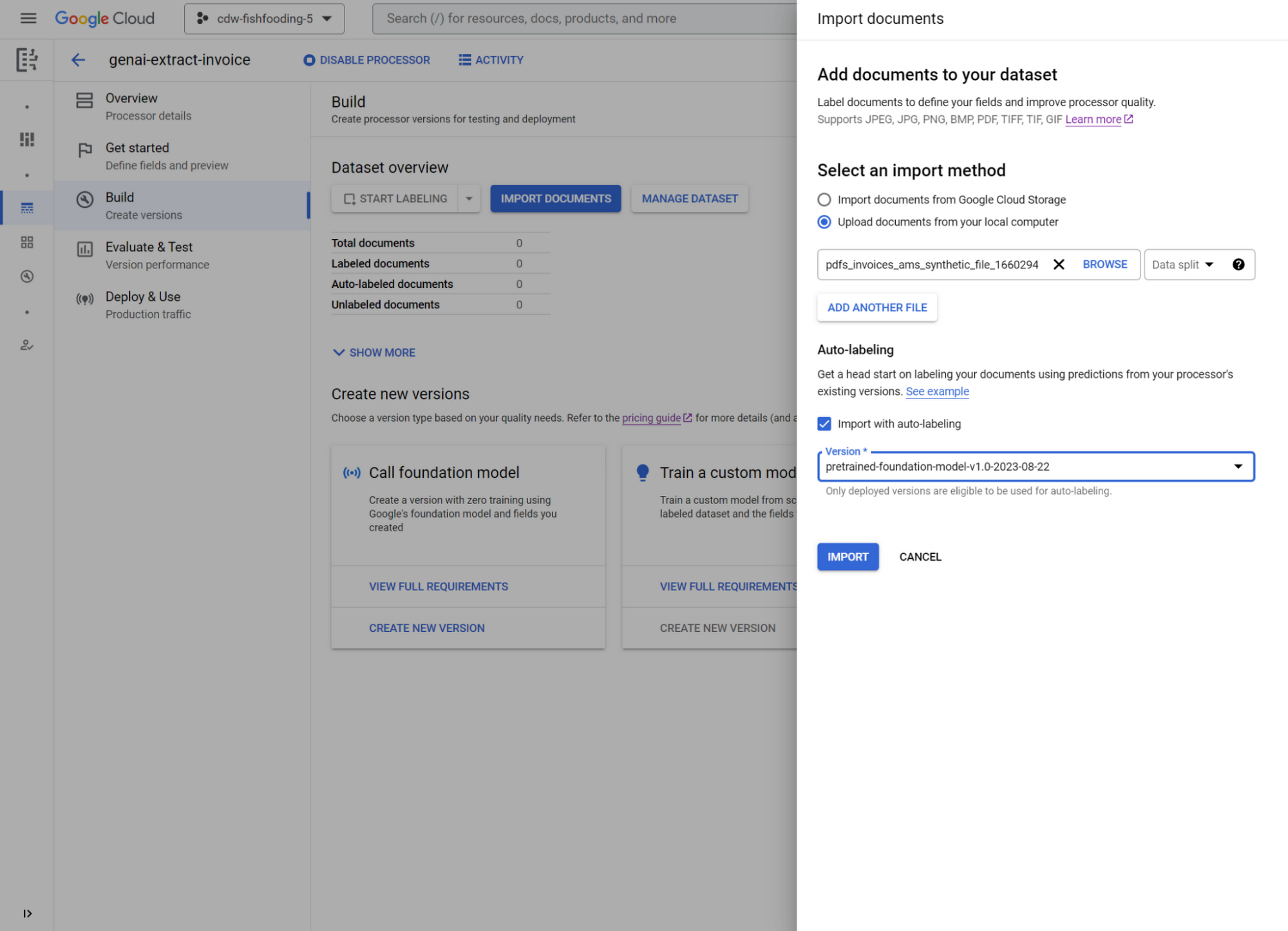
Finally, evaluate models side by side and deploy the best performing version in production–simply call the endpoint with documents to get structured data. To learn more, check out the demo video, release notes, user guide, labeling best practices, and training use cases.
The Summarizer
The Summarizer is now available, in public preview, and can be used out of the box with no training required and provide summaries for documents up to 250 pages long. You don’t need to worry about document chunks or model context windows.You can customize summaries based on your preferences for length and format.
To get started, go to Document AI Workbench and create a Summarizer. You can immediately call this endpoint with any document and get summaries in return. Or you can customize summaries by uploading a sample document and previewing summaries with different format configurations for length (brief, moderate, comprehensive) and format (paragraph, bullet points).
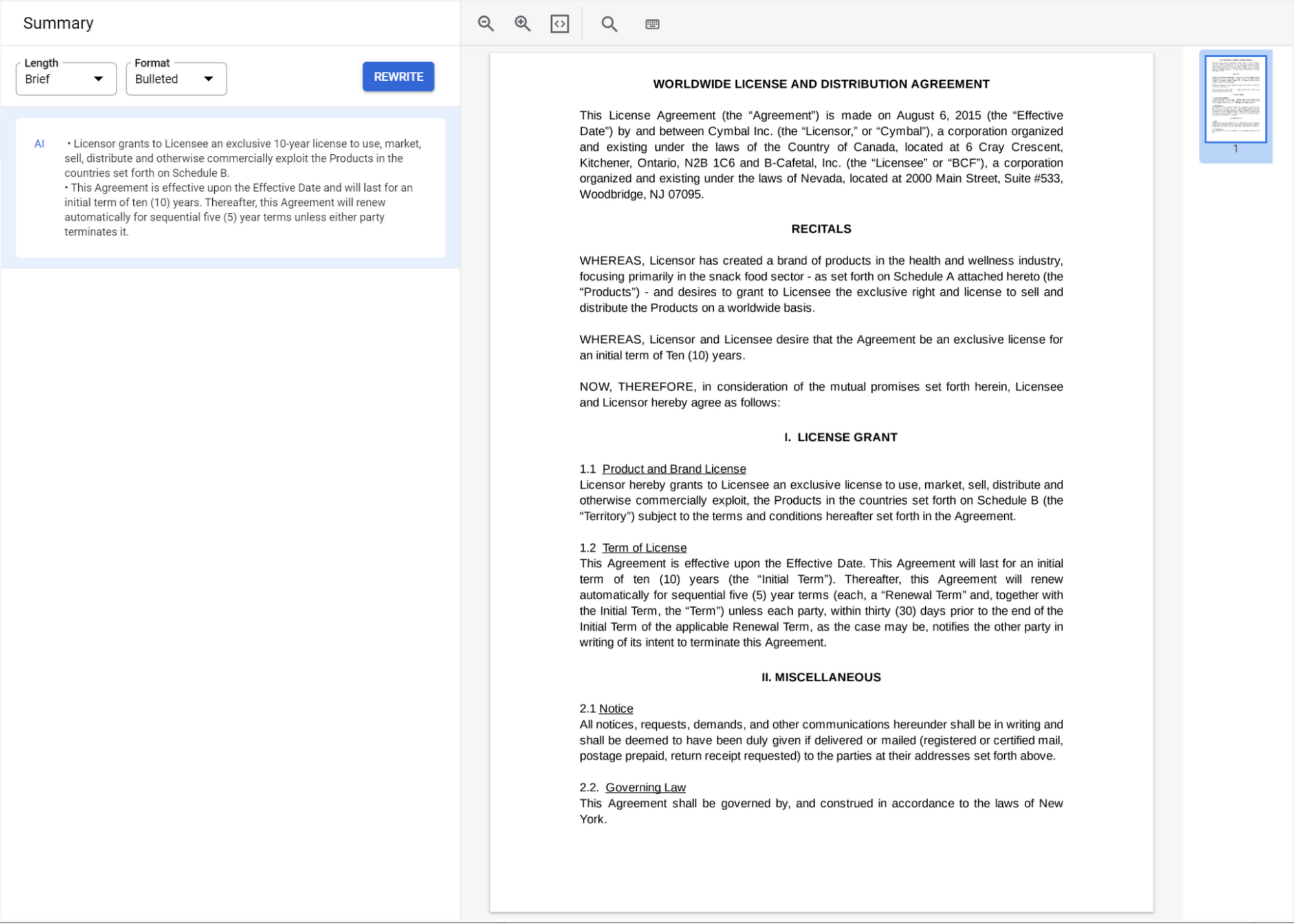
Once you’re satisfied with the selected settings, create a version which will provide summaries based on your preferences. You can also dictate length and format settings when calling the API per document.
Finally, you can view all available versions and call your preferred endpoint to get document summaries. To learn more, check out the demo video release notes, and the user guide.
What customers are saying
As mentioned previously, both the Customer Extractor and Summarizer are in public preview and you can go to Document AI Workbench within the Google Cloud Console to try them out now. Some customers with early access have the following thoughts:

“Deutsche Bank (DB) divisions are digitizing high volume documents and extracting data using the Document AI Workbench Custom Extractor for simple, scalable use cases such as KYC and payment forms. Automating the content review process leads to reduced operational risk, increased capacity and a better customer experience. With the introduction of generative AI to Workbench, we hope to automate more complex documents with reduced time to train a model and explore new use cases for faster intelligence such as Q&A and summarization.” — Inwha Huh, MD – Corporate and Investment Bank Transformation, Deutsche Bank AG

“BBVA is committed to providing our customers with the best possible experience, and that includes using AI to automate our business processes. By using generative AI now available in Document AI Workbench, we will extract data in complex, highly dense and non structured documents and prevent errors and potential fraud. This will allow us to provide our customers with a faster, more accurate, and more secure service.” — Antonio Valle, Global Head of Intelligent Process Automation, BBVA

“Customers rely on Automation Anywhere for end-to-end automation and document processing capabilities. Through our partnership with Google Cloud’s Document AI Workbench, our joint customers can now use the power of generative AI to extract and summarize data from more document types. Not only that, they can get started faster than ever with these technologies to automate enterprise processes and drive business growth using the power of generative AI and intelligent automation.” — Peter White, Senior Vice President, Emerging Products, Automation Anywhere

"GenAI elevates our capabilities in our information management and content services platform, Iron Mountain InSight® by enabling content summarization and advantages for Intelligent Document Processing including improving the quality and accuracy of extraction from unstructured documents with limited or no training data, ultimately, accelerating time to value for our Customers and elevating the employee experience" — Helene Fox, Head of Alliances & Global Director, Iron Mountain

“Document AI powers Orby’s ‘observe, learn and automate’ AI automation platform. Now, with generative AI extraction in Workbench, we will customize results so our customers achieve higher accuracy while supporting longer documents–all without having to worry about document chunks, context windows, or converting docs to text. This will offer faster time to value for our customers who have experienced up to 70% cost savings for contract processing with OrbyAI powered by Document AI.” — Bella Liu, CEO of Orby AI

“We offer Contextual Language Models (CLMs) so enterprises can build customizable, trustworthy, and privacy aware AI systems that rely on their knowledge bases and data sources. We've turned to Document AI and its new generative AI capabilities to extract rich and complex data that other extraction solutions often fail to capture. We are excited to use custom extractors with GenAI to further improve accuracy with few-shot predictions and fine-tuning. With Document AI, our CLMs can rely on more accurate, robust, and scalable data extraction from documents.” — Aditya Bindal, Vice President of Product, Contextual AI.
Improving Workbench
Finally, we continue to invest in Document AI Workbench and have recently launched:
- Automatic diversity sampling to improve the efficacy of training and evaluation datasets.
- Template based training for high accuracy extraction for fixed layout documents.
- We’ve launched dataset management APIs to enable end to end API use to create, train, manage, and call document processing models.
Go to Document AI Workbench within the Google Cloud Console to try these out today.


