Document AI introduces powerful new Custom Document Classifier to automate document processing
Derek Egan
Product Manager, Vertex AI
Businesses rely on an inflow of documents to drive processes and make decisions. As documents flow into a business, many are not classified by type, which makes it difficult for businesses to manage at scale.
At Google Cloud, we’re committed to solving these challenges with continued investment in our state-of-the-art machine learning product for document processing and insights: Document AI Workbench, which helps users quickly build models with world-class accuracy trained for their specific use cases. In February 2023, we launched the Custom Document Extractor (CDE) in GA to help users extract structured data from documents in production use cases. Today, we’re announcing the newest model type to help users automate document processing, Custom Document Classifier (CDC). With CDC, users can train highly accurate machine learning models to automatically classify document types.
CDC provides tangible business value to customers. For example, businesses can validate if users submit the right documents within an application, lowering review time and cost. In addition, accurate classification enables businesses to better automate downstream processes. This includes selecting the proper storage, analysis, or processing steps.
In this blog post, we’ll give an overview of the Custom Document Classifier and ways customers are already benefiting from it.
Benefits of classification models with Document AI Workbench
Our customers use Document AI Workbench to ultimately save time and money, building models with state of the art accuracy in a fraction of the time that traditional development methods require. Thus, CDC helps businesses achieve higher automation rates to scale processes while lowering costs.
Chris Jangareddy, managing director for Artificial Intelligence & Data at Deloitte Consulting LLP said, “Google Cloud Document AI is a leading document processing solution packed with rich features like multi-step classify and text extraction to automated sorting, classification, extraction, and quality assurance. By combining Document AI with Workbench, Google Cloud has created a forward-thinking and powerful AI platform for intelligent document processing that will allow for process transformation at an enterprise scale with predictable outcomes that can benefit businesses.”
Rajnish Palande, VP, Google Business Unit for BFSI, TCS said, “Document AI Workbench leverages artificial intelligence to manage and glean insights from unstructured data. Workbench brings together the power of classification, auto-annotation, page number identification, and multi-language support to help organizations rapidly deliver enhanced accuracy, improved operational efficiency, higher confidence in the information extract, and increased return on investment.”
Sean Earley, VP of Delivery Services of Zencore said, "Document AI Workbench allows us to develop highly accurate document parsing models in a matter of days. Our customers have automated tasks that formerly required significant human labor. For example, using Document AI Workbench, a team of two trained a model to split, classify, and extract data from 15 document types to automate Home Mortgage Disclosure Act reporting. The mean trained model accuracy was 94%, drastically reducing the operational cost of our customer’s compliance reporting procedures."
How to use Custom Document Classifier
Users can leverage a simple interface in the Google Cloud Console to prepare training data, create and evaluate models, and deploy a model into production, at which point it can be called to classify document types. You can follow the documentation for instructions on how to create, train, evaluate, deploy, and run predictions with models.
Import and prepare training data
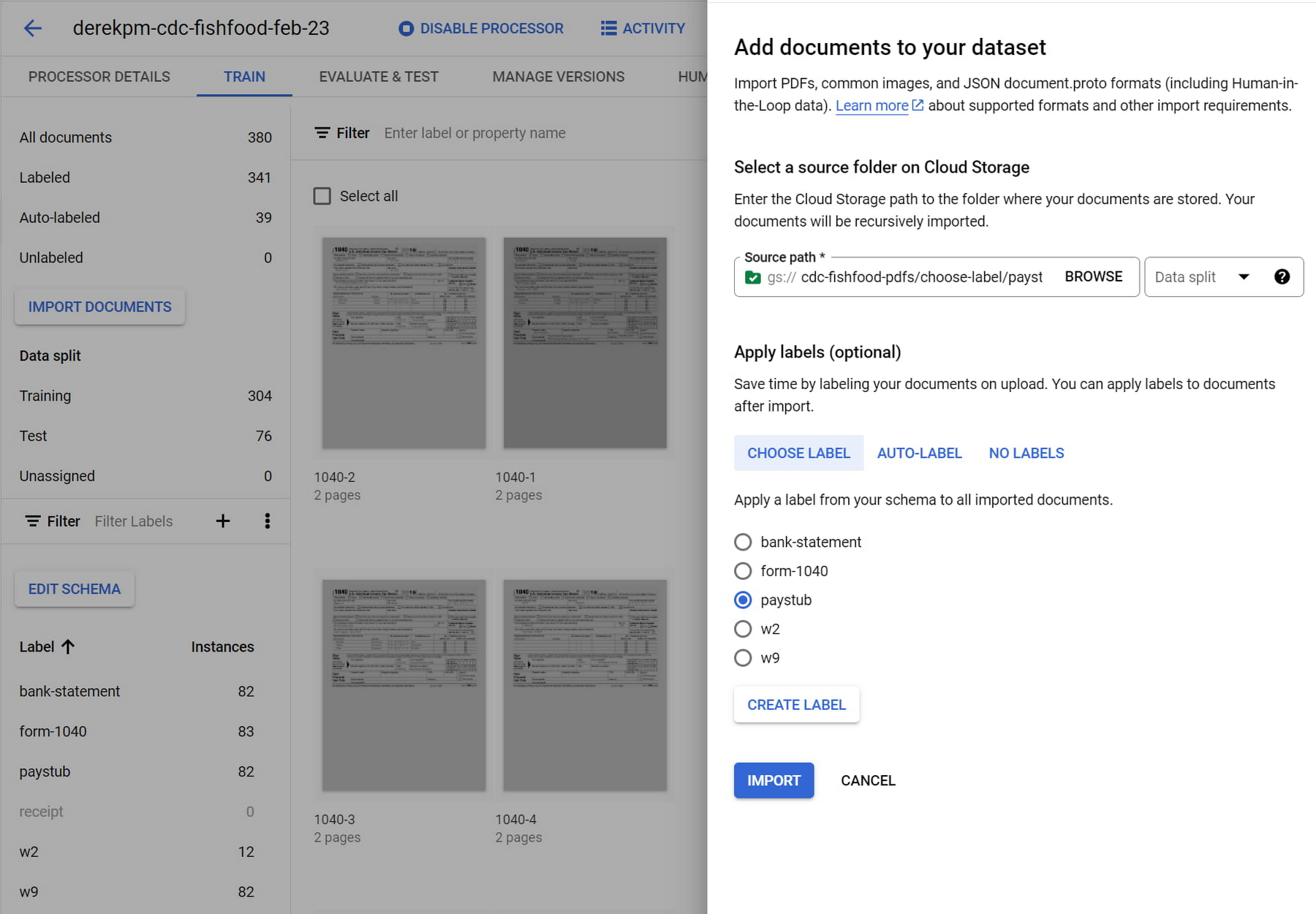
To get started, users import and label documents to train an ML model. Users can label documents in bulk at import to build the training and test datasets needed to build a model accurate enough for production workloads in hours. If documents are already labeled using other tools, users can simply import labels with JSON in the Document format. Users can initiate training with a click of a button. Once the user has trained a model, they can auto-label documents to build a more robust training dataset to improve model performance.
Evaluate a model and iterate
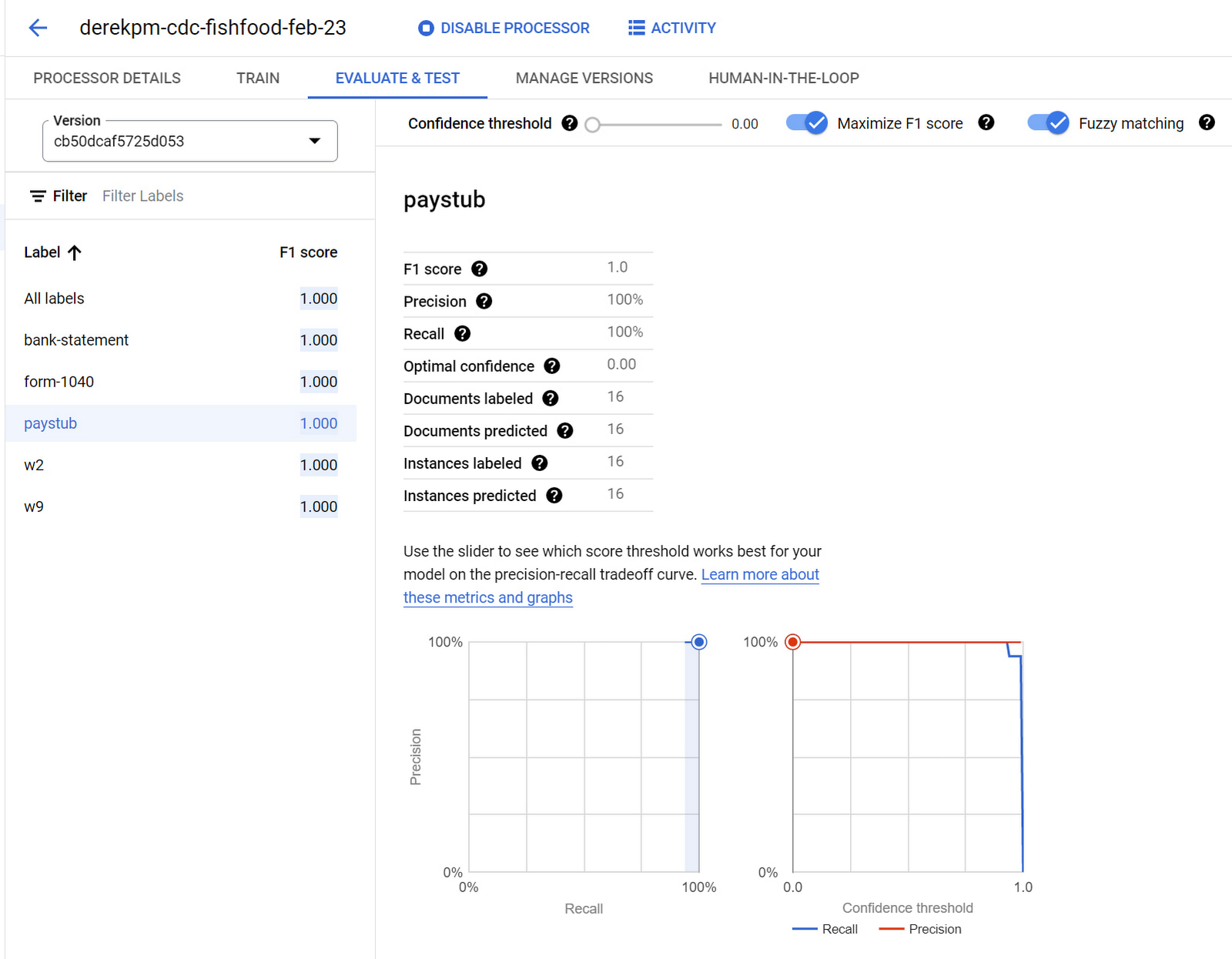
Once a model is trained, it’s time to evaluate it by looking at the performance metrics–F1 score, precision, recall, etc. Users can dive into specific instances where the model predicted an error, then provide additional training data to improve future performance.
Going into production
Once a model meets accuracy targets, it’s time to deploy into production, after which the model endpoint can be called to classify document types.
Getting started with Document AI Workbench
Custom Document Classifier is publicly available in GA and ready to help customers automate document classification. Learn more via our Document AI Workbench web page, Document AI Workbench documentation or try it out in the Google Cloud Console.
Acknowledgements: Lukas Rutishauser, Software Engineering Manager; Michael Kwong, Software Engineering Manager; Rajagopal Janani, Software Engineering Manager; Michael Lanning, UX Designer; Shagun Lal, Product Marketing Manager; Tomas Moreno, Outbound Product Manager; Holt Skinner, Developer Advocate.



