Gen AI apps: Deploy LangChain on Cloud Run with LangServe

Wietse Venema
Developer Relations Engineer
Nuno Campos
Founding engineer, LangChain
Updated May 2024: In this new codelab, learn how build and deploy a LangChain RAG app with a vector database on Cloud Run
LangChain is a popular framework that makes it easy to build apps that use large language models (LLMs). LangChain recently introduced LangServe, a way to deploy any LangChain project as a REST API. LangServe supports deploying to both Cloud Run and Replit.
I asked Nuno Campos, one of the founding engineers at LangChain, why they chose Cloud Run. He said:
“We researched alternatives, and Cloud Run is the easiest and fastest way to get your app running in production."
In this blog, I’ll show you how to get started with LangServe and deploy a template to Cloud Run that calls the VertexAI PaLM 2 for chat model.
Generative AI apps explained
Generative AI chatbots such as Google Bard are powered by large language models (LLMs). Generally speaking, you prompt an LLM with some text and it’ll complete the prompt. While you can describe an LLM as an advanced auto-complete, that’s an oversimplified way of thinking about it. LLMs can write code, rephrase text, generate recommendations, and solve simple logic problems.
You can also send prompts to an LLM from your code, which can be very useful once you start integrating with your own private data and APIs. Some popular use cases include:
- Asking questions over your own data (including manuals, support cases, product data)
- Interacting with APIs using natural language, letting the LLM make API calls for you
- Summarizing documents
- Data labeling or text extraction
Building these integrations often involve building pipelines (typically referred to as chains), starting with a prompt, and bringing your own data into the prompt. That’s where LangChain comes in. Approaching 70k stars on GitHub, LangChain is by far the most popular framework for building LLM-powered apps.
Build chains with LangChain
LangChain provides all the abstractions you need to start building an LLM app, and it comes with many components out of the box, including LLMs, document loaders, text embedding models, vector stores, agents and tools. I’m glad to see many Google products that have an integration with LangChain. Some highlights include Vertex AI Vector Search (previously known as Matching Engine), and hundreds of open source LLM models through Vertex AI Model Garden.
Here’s how you can use LangChain to call the VertexAI PaLM 2 for chat model and ask it to tell jokes about Chuck Norris:
Serve chains as an API with LangServe
Once you have your prototype chain ready, you package it up and expose it as a REST API with LangServe in two steps:
- Scaffold a LangServe app using the
langchainCLI - Add your chain with the
add_routescall
LangServe also comes with a playground endpoint that lets you try and debug your chain. If you’re interested in learning more, you should definitely read the launch blog of LangServe.
LangChain templates
I always like it when a project comes with well-designed recipes that show how to put everything together to build something real, and LangChain has many of them. Here’s a long list of LangChain templates, including the Chuck Norris example I’ve just shown you.
Demo time
Let’s start with the Google Cloud part. I’m assuming you already have a Google Cloud project with an active billing account. Find the project ID of that project, and set it as the default:
You should also enable the Vertex AI API for the project:
To call the Vertex AI PaLM API from localhost, configure application default credentials:
Getting started with LangChain
First, install the LangChain CLI:
Now, scaffold a LangServe REST API and add the Chuck Norris template using the following command:
This command creates a directory my-demo, and the --package flag installs the Chuck Norris template.
Find app/server.py and link in Chuck Norris using this snippet (find the comments in the file that say where):
To start the API on your localhost, change into the my-demo directory and start the app:
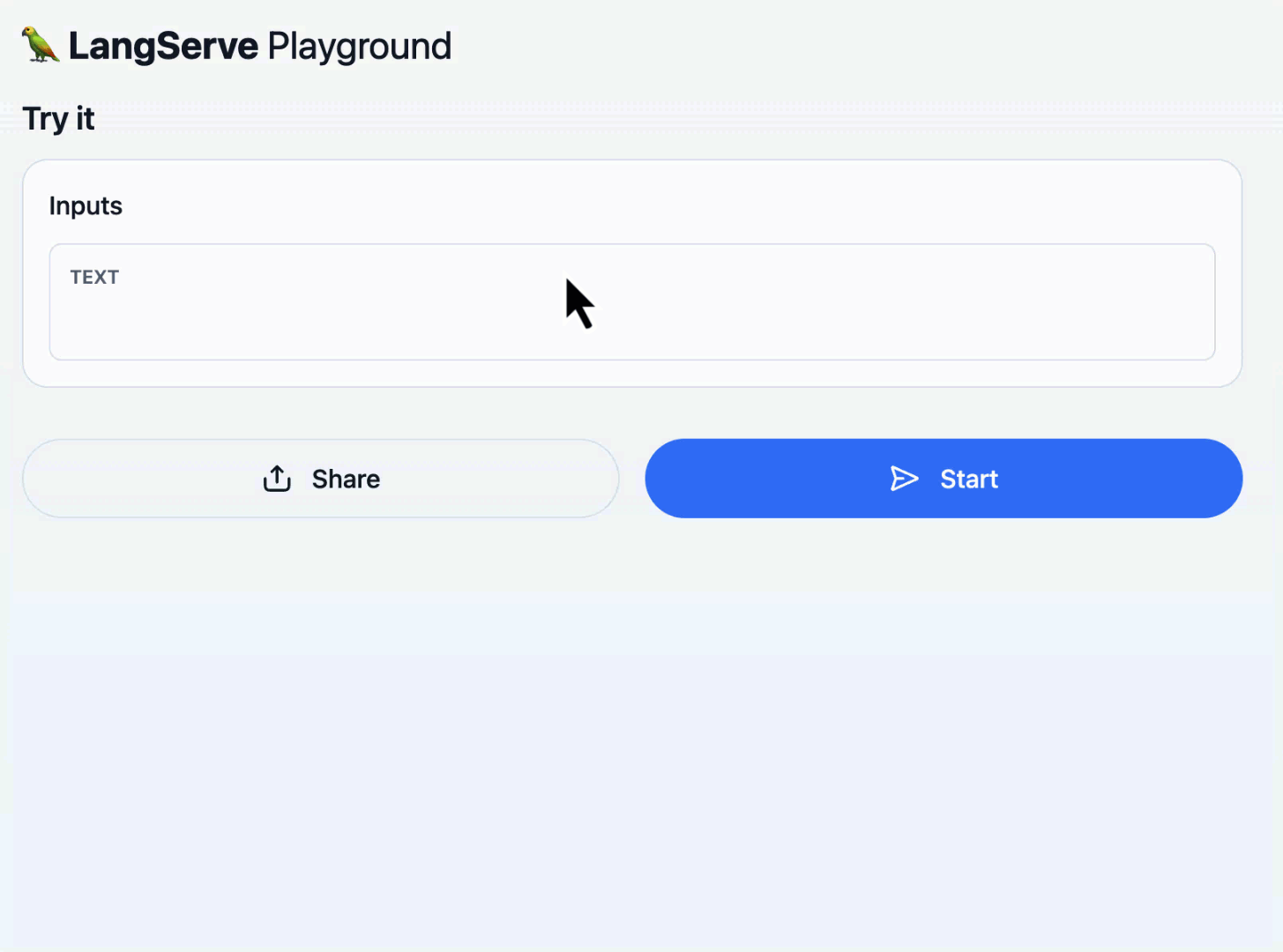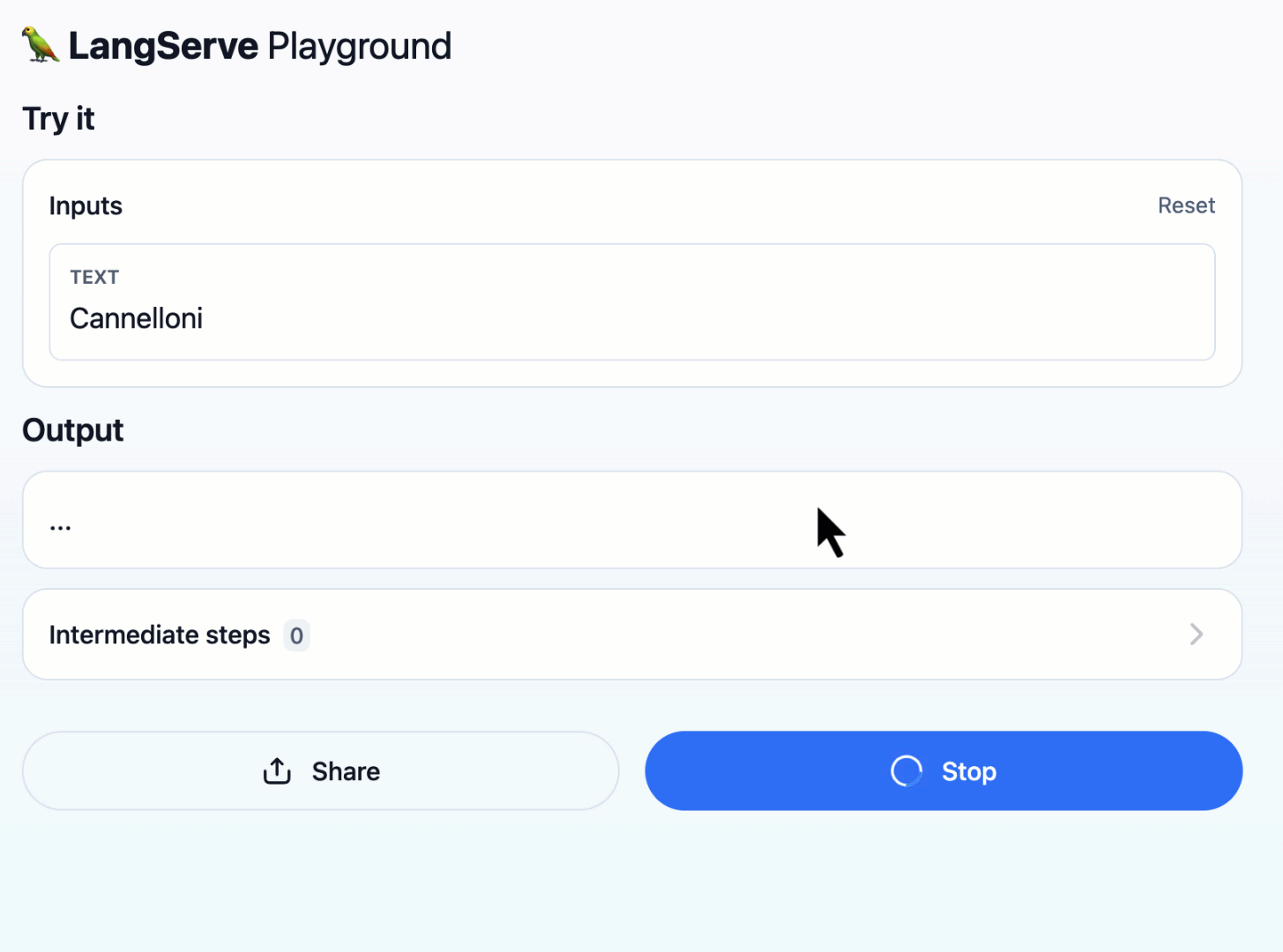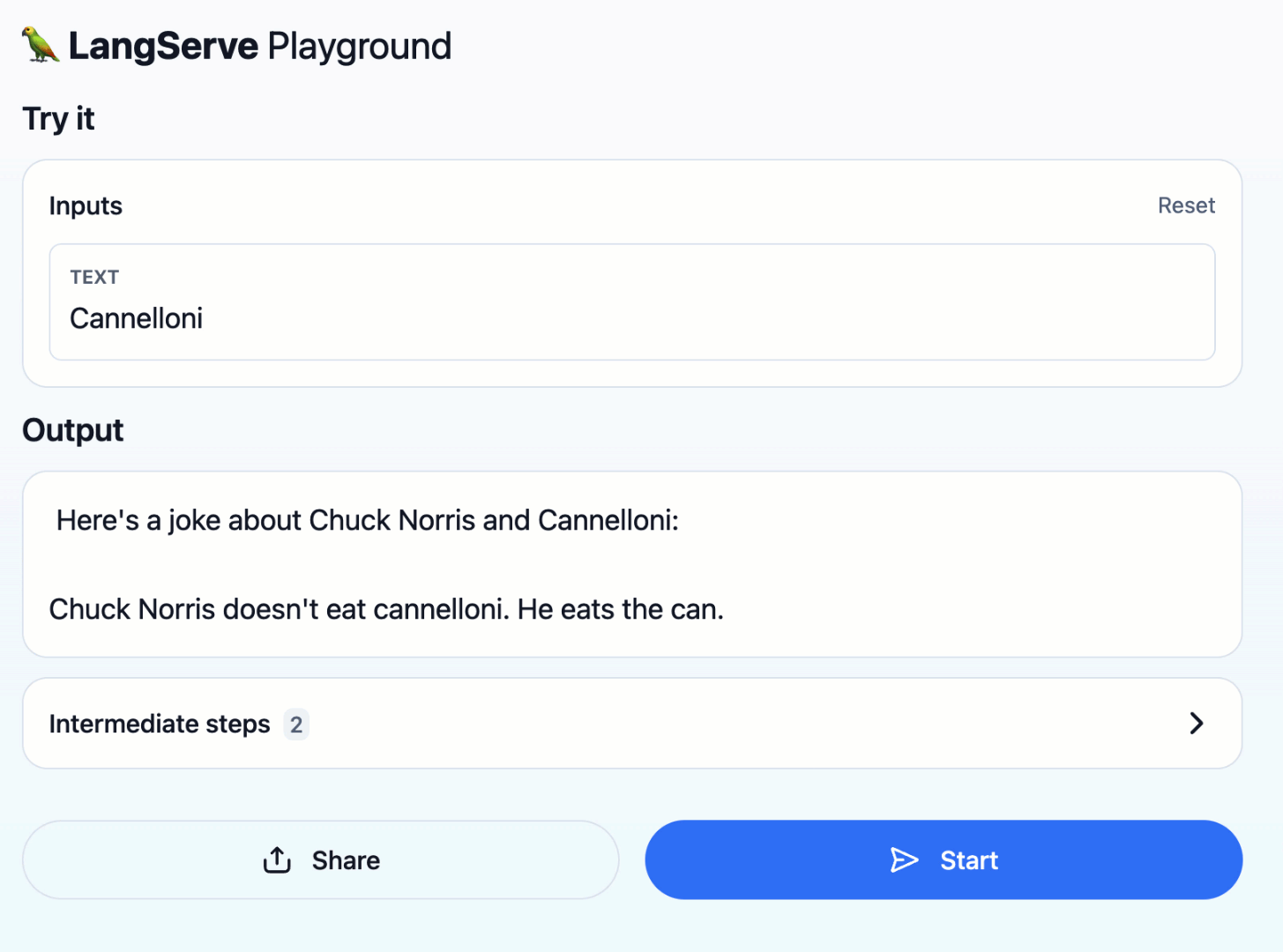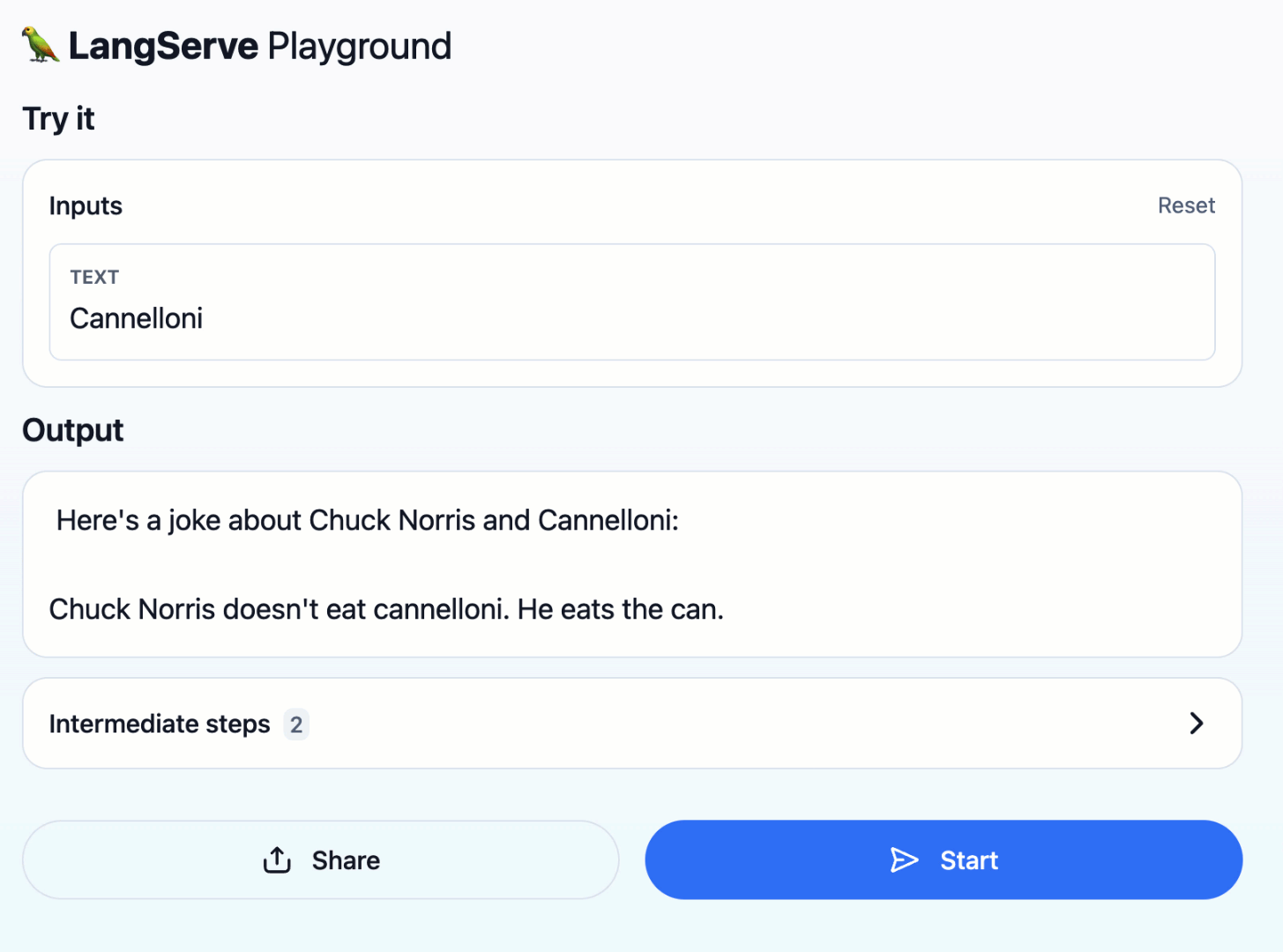
This should bring up a webserver on http://localhost:8080. If you go to http://localhost:8080/vertexai-chuck-norris/playground, you can generate more silly jokes about Chuck Norris.
Deploy to Cloud Run
It’s time to go from localhost to production now. Run this to deploy the API and create a Cloud Run service.
This command will ask you to confirm a few settings, and you might need to enable a few APIs. It’ll also ask you to allow unauthenticated invocations. You want that if you want to access your app through a browser and share the link with your friends.
Cloud Run creates an HTTPS endpoint for you, and automatically scales the number of container instances to handle all incoming requests.
From prototype to a real-world application
Before wrapping up this article, I want to add a word of caution. Deploying your prototype chain is only the first step in getting your GenAI app ready for real-world usage in a responsible way. It’s recommended to apply safety filters to both input and output, and perform adversarial testing. Refer to the safety guidance to learn more. Additionally, you should also consider the legal implications of using GenAI models and content. For a range of Google Cloud services, Google Cloud assumes responsibility for potential legal risks of using our generative AI.
LangChain and Vertex AI extensions
This blog shows you how to deploy your LangChains as a REST API with LangServe. If you’re already familiar with using Vertex AI, you might also be interested in signing up for the private preview of Vertex AI Extensions that provides another way of integrating your LangChain chains.
Next steps
- Read more about Cloud Run (or just try it out in the web console!)
- Explore LangChain and LangServe



