Introducing Prediction Private Endpoints for fast and secure serving on Vertex AI
Nikita Namjoshi
Developer Advocate
One of the biggest challenges when serving machine learning models is delivering predictions in near real-time. Whether you’re a retailer generating recommendations for users shopping on your site, or a food service company estimating delivery time, being able to serve results with low latency is crucial. That’s why we’re excited to announce Private Endpoints on Vertex AI, a new feature in Vertex Predictions. Through VPC Peering, you can set up a private connection to talk to your endpoint without your data ever traversing the public internet, resulting in increased security and lower latency for online predictions.
Configuring VPC Network Peering
Before you make use of a Private Endpoint, you’ll first need to create connections between your VPC (Virtual Private Cloud) network and Vertex AI. A VPC network is a global resource that consists of regional virtual subnetworks, known as subnets, in data centers, all connected by a global network. You can think of a VPC network the same way you'd think of a physical network, except that it’s virtualized within GCP. If you’re new to cloud networking and would like to learn more, check out this introductory video on VPCs.
With VPC Network Peering, you can connect internal IP addresses across two VPC networks, regardless of whether they belong to the same project or the same organization. As a result, all traffic stays within Google’s network.
Deploying Models with Vertex Predictions
Vertex Predictions is a serverless way to serve machine learning models. You can host your model in the cloud and make predictions through a REST API. If your use case requires online predictions, you’ll need to deploy your model to an endpoint. Deploying a model to an endpoint associates physical resources with the model so it can serve predictions with low latency.
When deploying a model to an endpoint, you can specify details such as the machine type, and parameters for autoscaling. Additionally, you now have the option to create a Private Endpoint. Because your data never traverses the public internet, Private Endpoints offer security benefits in addition to reducing the time your system takes to serve the prediction when it receives the request. The overhead introduced by Private Endpoints is minimal, achieving performance nearly identical to DIY serving on GKE or GCE. There is also no payload size limit for models deployed on the private endpoint.
Creating a Private Endpoint on Vertex AI is simple.
In the Models section of the Cloud console, select the model resource you want to deploy.
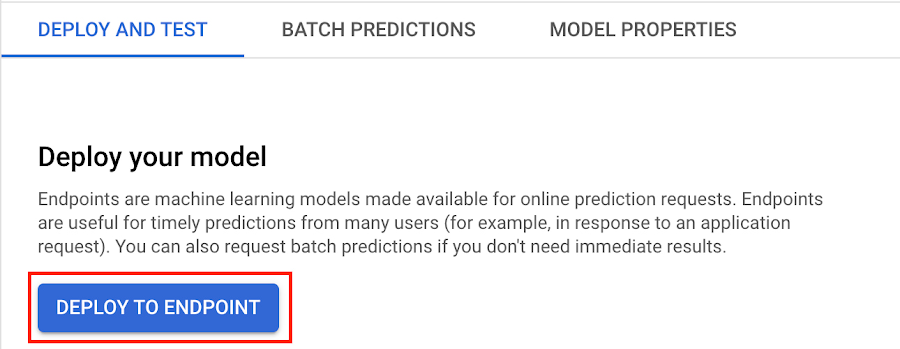
Next, select DEPLOY TO ENDPOINT
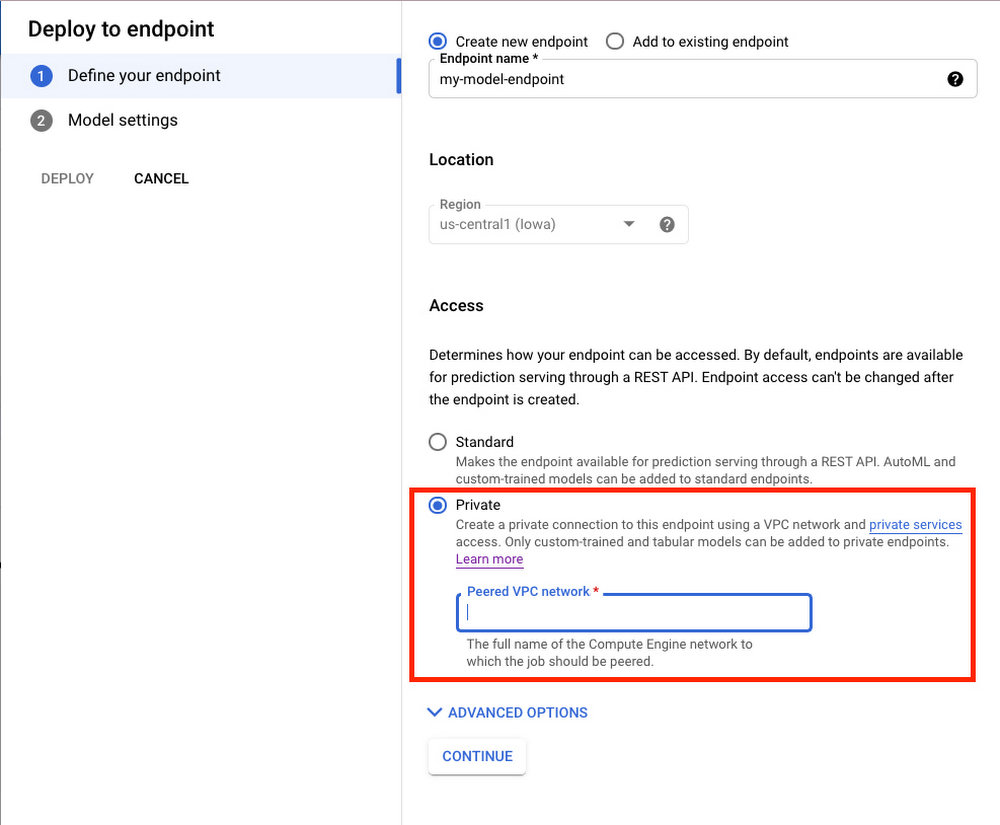
In the window on the right hand side of the console, navigate to the Access section and select Private. You’ll need to add the full name of the VPC network for which your deployment should be peered.
Note that many other managed services on GCP support VPC peering, such as Vertex Training, Cloud SQL, and Firestore. Endpoints is the latest to join that list.
What’s Next?
Now you know the basics of VPC Peering and how to use Private Endpoints on Vertex AI. If you want to learn more about configuring VPCs, check out this overview guide. And if you’re interested to learn more about how to use Vertex AI to support your ML workflow, check out this introductory video. Now it’s time for you to deploy your own ML model to a Private Endpoint for super speedy predictions!




