Cloud TPUs in Kubernetes Engine powering Minigo are now available in beta

Yoshi Tamura
Product Manager, Google Kubernetes Engine and gVisor
Andrew Jackson
Software Engineer, Minigo
Google Kubernetes Engine (GKE) is a great place to run your containerized enterprise machine learning (ML) workloads. We recently announced the general availability of NVIDIA Tesla V100 GPUs with NVLink on GKE, which like the K80, P100 and P4 GPUs, let you speed up many CUDA-powered compute and HPC workloads, without having to manage hardware or even VMs. Today, we’re going one step further: Google-designed Cloud TPUs are publicly available in beta on GKE. GKE also supports Preemptible Cloud TPUs that are priced 70% lower than the standard price of Cloud TPUs.
Cloud TPUs were designed from the ground up to train and run cutting-edge ML models. Each Cloud TPU v2 (now generally available) delivers up to 180 teraflops of compute power and includes 64 GB of high-bandwidth memory, and each Cloud TPU v3 (now in Alpha) provides up to 420 teraflops as well as double the memory (128 GB) to accommodate even larger and more complex ML models. To get started quickly with Cloud TPUs, you can use Google-provided open-source reference models that have been optimized for performance, accuracy, and quality.
You can use Cloud TPUs to build solutions for many real-world problems, including image recognition, object detection, image segmentation, speech recognition, machine translation, question-answering, and much more. All you need is to bring your data, choose a reference model, and follow one of our Cloud TPU tutorials to train the reference model with your data. You can also build your own models from scratch using high-level TensorFlow APIs, including Keras.
GKE has a number of unique features to make it even easier for you to use Cloud TPUs for your containerized ML workloads:
Easy setup and management: GKE sets up and manages the Cloud TPUs and a corresponding block of network addresses for you.
Optimized cost: GKE scales the cluster and the number of Cloud TPUs automatically based on your workloads and traffic. You only pay for the cluster and the Cloud TPUs used for your workloads.
Scalability: GKE provides APIs (Job and Deployment) that can easily scale to hundreds of Kubernetes Pods and Cloud TPUs.
Fault tolerance: GKE's Job API, along with the TensorFlow checkpoint mechanism, provide the run-to-completion semantic. Your training jobs will automatically rerun with the latest state read from the previous checkpoint if failures or interruptions occur on the cluster or Cloud TPUs.
Now, if you’ve already containerized your ML workflows, or are just getting started, taking advantage of ML-optimized Cloud TPUs with GKE is a trivial matter.
Getting started with Cloud TPUs in GKE
When we say that creating a cluster with Cloud TPUs in GKE is easy, we really mean it. The following command creates a cluster with Cloud TPUs that automatically set up and manage the Cloud TPUs for you. You can also create a cluster with Cloud TPUs in GKE by following the documentation.To request and access Cloud TPUs in GKE, specify the number of Cloud TPU cores to request in your Kubernetes Pod spec. The following example requests a single v2-8 Preemptible Cloud TPU device. A single v2-8 Preemptible Cloud TPU device consists of four chips, each of which has two cores, for eight cores in total.
For a more detailed explanation of Cloud TPUs in GKE, for example how to train the TensorFlow ResNet-50 model using Cloud TPU and GKE, check out the documentation.
640 Cloud TPUs in GKE powering Minigo
Internally, we use Cloud TPUs to run one of the most iconic Google machine learning workloads: Go. Specifically, we run Minigo, an open-source and independent implementation of Google DeepMind’s AlphaGo Zero algorithm, which was the first computer program to defeat a professional human Go player and world champion. Minigo was started by Googlers as a 20% project, written only from existing published papers after DeepMind retired AlphaGo.
Go is a strategy board game that was invented in China more than 2,500 years ago and that has fascinated humans ever since—and in recent years challenged computers. Players alternate placing stones on a grid of lines in an attempt to surround the most territory. The large number of choices available for each move and the very long horizon of their effects combine to make Go very difficult to analyze. Unlike chess or shogi, which have clear rules that determine when a game is finished (e.g., checkmate), a Go game is only over when both players agree. That’s a difficult problem for computers. It’s also very hard, even for skilled human players, to determine which player is winning or losing at a given point in the game.
Minigo plays a game of Go using a neural network, or a model, that answers two questions: “Which move is most likely to be played next?” called the policy, and “Which player is likely to win?” called the value. It uses the policy and value to search through the possible future states of the game and determine the best move to be played.
The neural network provides these answers using reinforcement learning which iteratively improves the model in a two-step process. First, the best network plays games against itself, recording the results of its search at each move. Second, the network is updated to better predict the results in step one. Then the updated model plays more games against itself, and the cycle repeats, with the self-play process producing new data for the training process to build better models, and so on ad infinitum.
Each move in a game performs thousands of inferences, and each game has hundreds of moves. Thus, the amount of compute required to create the data by self-play dwarfs the amount of compute needed to train the model. Luckily, these self-play games are completely independent from each other, which makes them an ideal candidate for massive parallelization by running inside containers on GKE.
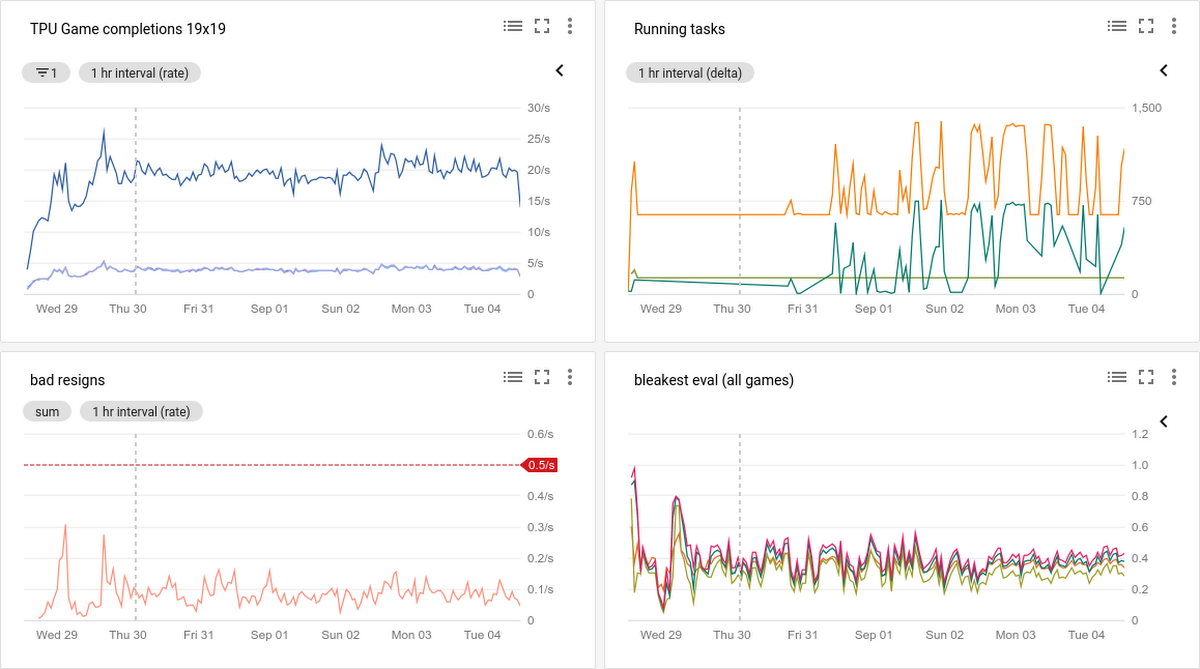
We initially ported Minigo to run on GPUs as a Kubernetes Batch Job. Later, we ported it to run on Cloud TPUs as a Kubernetes Deployment, where today it plays millions of games, with a cluster of 640 Cloud TPUs on GKE completing about 20-30 games per second. With GKE and Cloud TPUs, it was trivial to dedicate 115 petaflops of compute to a single problem!
Try Cloud TPUs in GKE today
To get started using Cloud TPUs in GKE, sign up for a free trial of GCP that includes $300 Google Cloud credits and follow the Cloud TPU quickstart. Then be sure to check out our tutorials, open source reference models, and performance guide to maximize the performance of your Cloud TPUs. We also recommend watching our Cloud-TPU-related sessions from Google Cloud Next’18:
Thanks for your feedback on how to shape our roadmap to better serve your needs. Let’s keep the conversation going by connecting on the GKE Slack channel.



