Ironwood TPU 및 AI 하이퍼컴퓨터의 새로운 혁신 기술 소개

Mark Lohmeyer
VP & GM, AI & Computing Infrastructure
George Elissaios
VP, Product Management, Compute Engine & AI Infrastructure
* 본 아티클의 원문은 2025년 4월 10일 Google Cloud 블로그(영문)에 게재되었습니다.
오늘날의 혁신은 실험실이나 설계도에서 탄생하는 것이 아니라 AI 인프라를 기반으로 이루어집니다. AI 워크로드에는 새롭고 고유한 요구사항이 있습니다. 이러한 요구사항을 충족하려면 성능과 효율성을 대규모로 달성할 수 있도록 하드웨어와 소프트웨어를 정교하게 조합해야 하며, 필요에 따라 이러한 인프라에 액세스할 수 있는 사용 편의성과 유연성을 확보해야 합니다. Google Cloud는 이를 위해 AI 하이퍼컴퓨터를 활용합니다.
AI 하이퍼컴퓨터는 Google이 10년 이상 쌓아온 AI 전문성을 바탕으로 개발한 통합형 슈퍼컴퓨팅 시스템으로 Google Cloud에서 실행되는 거의 모든 AI 워크로드를 뒷받침합니다. Vertex AI를 사용할 때 내부에서 실행되며, AI 하이퍼컴퓨터의 성능 최적화 하드웨어, 개방형 소프트웨어, 유연한 소비 모델에 직접 액세스해 인프라를 세밀하게 제어할 수 있습니다. 이러한 모든 기능은 AI 워크로드의 학습 및 서빙을 위한 더 많은 인텔리전스를 일관되게 저렴한 가격으로 제공하도록 설계되었습니다. 이러한 통합 시스템 접근 방식은 시장에서 차별화되는 요소이며, Gemini Flash 2.0이 GPT-4o에 비해 달러당 24배, DeepSeek-R1에 비해 5배 높은 인텔리전스를 달성할 수 있는 이유 중 하나입니다1.
오늘 Google Cloud는 AI 워크로드에 대해 비용 대비 최고의 인텔리전스를 제공하도록 종합적으로 설계된 AI 하이퍼컴퓨터 스택 전반의 새로운 혁신을 소개합니다.
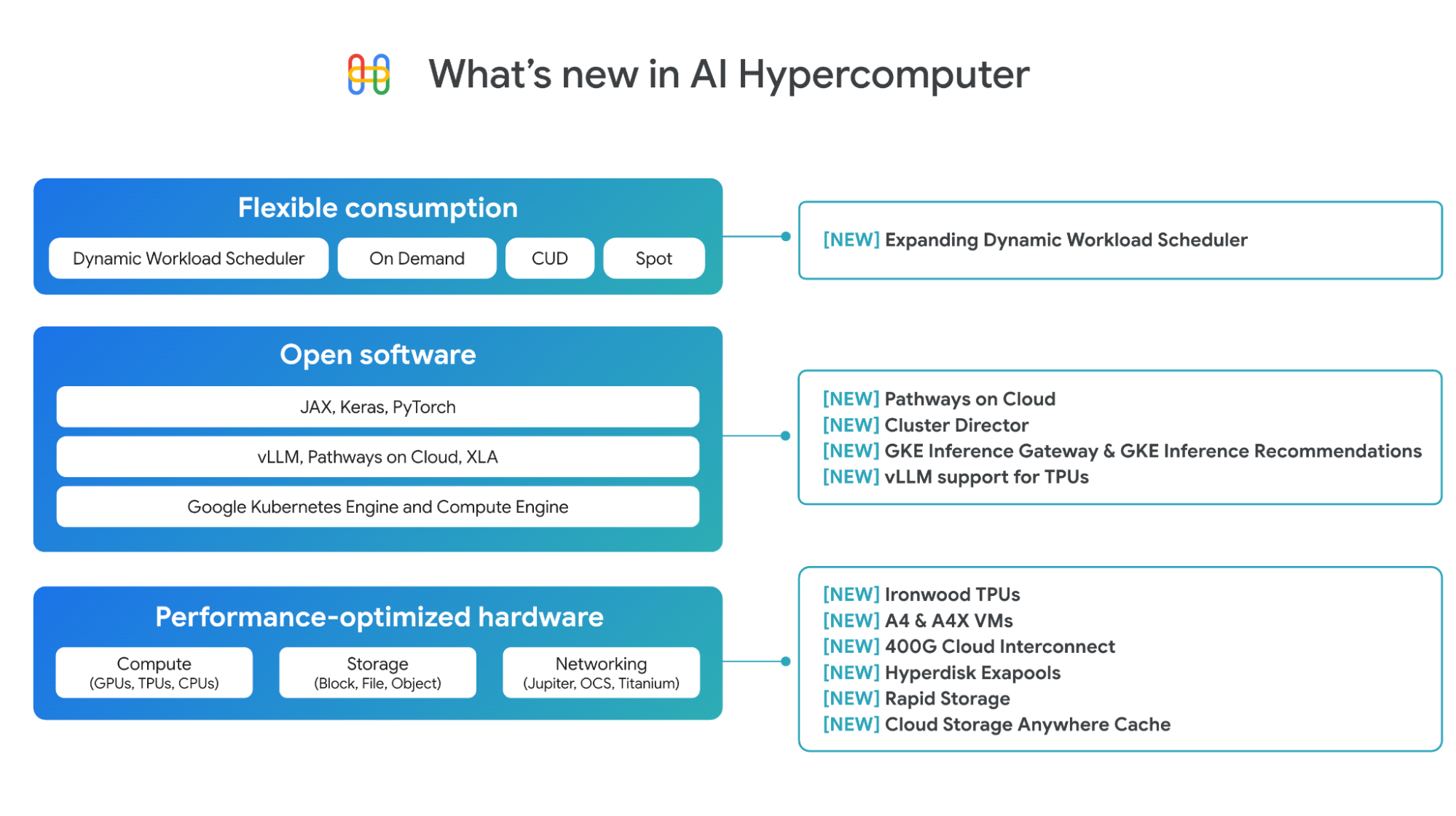
성능 최적화 하드웨어의 발전
Google Cloud는 다양한 컴퓨팅, 네트워킹, 스토리지 옵션을 제공하기 위해 성능 최적화 하드웨어 포트폴리오를 지속적으로 확장하고 있습니다.
7세대 TPU인 Ironwood: 추론을 위해 설계된 Ironwood는 이전 세대인 Trillium에 비해 5배 더 큰 최대 컴퓨팅 용량과 6배 더 큰 고대역폭 메모리(HBM) 용량을 제공합니다. Ironwood는 256개 칩 또는 9,216개 칩의 두 가지 구성으로 제공되며, 각각 단일 수직 확장 포드로 사용할 수 있습니다. 더 큰 포드는 42.5엑사플롭의 놀라운 컴퓨팅 성능을 제공합니다. Ironwood는 Trillium에 비해 전력 효율이 2배 더 높아 와트당 가치가 훨씬 더 높습니다. 개발자는 PyTorch와 JAX 전반에 걸쳐 최적화된 스택을 통해 Ironwood에 액세스할 수 있습니다. 이 획기적인 TPU에 대한 자세한 내용은 여기에서 확인하세요.

A4 및 A4X VM: Google Cloud는 A4 및 A4X VM과 함께 NVIDIA B200 및 GB200 NVL72 GPU를 모두 제공하는 최초의 하이퍼스케일러입니다. 지난달 Google Cloud는 NVIDIA GTC에서 A4 VM(NVIDIA B200)의 정식 버전을 발표했으며, A4X VM(NVIDIA GB200)은 현재 프리뷰 버전으로 제공되고 있습니다. A4 및 A4X에 대한 자세한 내용은 여기에서 확인하세요.
네트워킹 강화: AI 워크로드에 필요한 지연 시간이 매우 짧은 환경을 지원하기 위해 Google Cloud의 새로운 400G Cloud Interconnect 및 Cross-Cloud Interconnect는 기존 100G Cloud Interconnect 및 Cross-Cloud Interconnect보다 최대 4배 더 많은 대역폭을 제공해 온프레미스 또는 기타 클라우드 환경에서 Google Cloud에 대한 연결을 제공합니다. 자세한 내용은 여기를 클릭해 오늘 게시된 네트워킹 블로그 내용을 확인하세요.
Hyperdisk Exapools: 하이퍼스케일러 가운데 AI 클러스터당 가장 높은 성능과 용량을 갖춘 블록 스토리지로, 얇게 프로비저닝된 단일 풀에서 최대 엑사바이트 수준의 블록 스토리지 용량과 초당 수 테라바이트의 처리량을 프로비저닝할 수 있습니다.
Rapid Storage: 최적의 활용을 위해 기본 스토리지를 TPU 또는 GPU와 함께 코로케이션할 수 있는 새로운 Cloud Storage 영역 버킷입니다. Cloud Storage 리전별 버킷보다 최대 20배 빠른 임의 읽기 데이터 로드를 제공합니다.
Cloud Storage Anywhere Cache: 기존 리전별 버킷과 함께 작동해 선택한 영역 내에서 데이터를 캐싱하는 강력한 일관성을 갖춘 새로운 읽기 캐시입니다. Anywhere Cache는 데이터를 가속기에 가깝게 유지해 지연 시간을 70% 단축함으로써 실시간 반응형 추론 상호작용을 지원합니다. 자세한 내용은 여기를 클릭해 스토리지 혁신 블로그를 참고하세요.
학습 및 추론을 위한 개방형 소프트웨어 기능
하드웨어의 진정한 가치는 공동 설계된 소프트웨어를 통해 실현됩니다. AI 하이퍼컴퓨터의 소프트웨어 레이어는 AI 실무자와 엔지니어가 PyTorch, JAX, vLLM, Keras와 같은 개방형의 인기 ML 프레임워크와 라이브러리를 통해 더 빠르게 작업할 수 있도록 지원합니다. 인프라팀은 배포 시간을 단축하고 비용 효율적으로 리소스를 활용할 수 있게 됩니다. Google Cloud는 AI 학습과 추론을 위한 소프트웨어에서 상당한 진전을 이루었습니다.
Pathways on Cloud: Google DeepMind에서 개발한 Pathways는 Google의 내부 대규모 학습 및 추론 인프라를 지원하는 분산 런타임으로, 이제 Google Cloud에서 처음으로 제공됩니다. 추론을 지원하기 위해 분할 서빙과 같은 기능이 포함됩니다. 분할 서빙은 별도의 컴퓨팅 단위에서 추론 워크로드의 사전 입력 및 디코딩 단계를 동적으로 확장할 수 있도록 하며, 각 단계가 독립적으로 확장되어 지연 시간이 매우 짧고 처리량이 높습니다. 이 기능은 처리량이 높고 지연 시간이 짧은 추론 라이브러리인 JetStream을 통해 고객에게 제공됩니다. 또한 Pathways는 탄력적 학습을 지원해 학습 워크로드가 장애 발생 시 자동으로 축소되고 복구 시 수직 확장되며, 동시에 연속성을 유지합니다. Pathways 아키텍처의 추가 사용 사례를 비롯해 Pathways on Cloud에 대해 자세히 알아보려면 이 문서를 확인하세요.
높은 성능과 안정성으로 모델 학습
학습 워크로드는 수천 개의 노드에서 실행되는 고도로 동기화된 작업입니다. 단일 노드의 성능 저하만으로도 전체 작업이 중단될 수 있으며, 이는 출시 지연과 비용 증가로 이어질 수 있습니다. 클러스터를 빠르게 프로비저닝하려면 근접한 특정 모델 아키텍처에 맞게 조정된 VM이 필요합니다. 또한 노드 장애를 예측하고 신속하게 문제를 해결하며, 장애 발생 시 워크로드 연속성을 보장할 수 있는 기능도 필요합니다.
GKE용 Cluster Director 및 Slurm용 Cluster Director. Cluster Director(기존 Hypercompute Cluster)를 사용하면 물리적으로 함께 배치된 VM, 타겟팅된 워크로드 배치, 고급 클러스터 유지보수 제어, 토폴로지 인식 예약을 통해 가속기 그룹을 단일 단위로 배포하고 관리할 수 있습니다. 오늘 Google Cloud는 올해 말에 출시될 Cluster Director의 새로운 업데이트를 발표합니다.
-
Slurm용 Cluster Director는 Slurm 클러스터를 프로비저닝하고 운영하기 위한 간소화된 UI와 API를 갖춘 완전 관리형 Slurm 제품입니다. 여기에는 안정적이고 반복 가능한 배포를 위해 사전 구성된 소프트웨어를 사용한 일반적인 워크로드의 청사진이 포함됩니다.
-
360° 관측 가능성 기능에는 클러스터 사용률, 상태, 성능을 모니터링하는 대시보드와 AI 상태 예측, 낙오 항목 감지와 같은 고급 기능이 포함되며, 개별 노드 수준에서 장애를 선제적으로 감지하고 해결합니다.
-
자동화된 전체 상태 점검 등 작업 연속성 기능을 통해 Fleet를 지속적으로 모니터링하고 비정상 노드를 선제적으로 교체합니다. 결과적으로 다단계 체크포인팅을 통해 더 빠른 저장 및 검색이 가능해져 성능이 저하된 클러스터에서도 중단 없는 학습이 가능합니다.
GKE용 Cluster Director가 출시되면 새로운 Cluster Director 기능이 기본적으로 지원됩니다. Slurm용 Cluster Director는 GPU와 TPU를 모두 지원하며 몇 달 내로 출시될 예정입니다. 등록하여 사전 체험판을 이용하세요.
규모와 상관없이 효율적으로 추론 워크로드 실행
지난해 AI 추론은 급격히 발전했습니다. 더 길고 가변성이 높은 컨텍스트 윈도우로 인해 상호작용이 더욱 정교해지고 있으며, 추론 및 다단계 추론으로 인해 컴퓨팅 수요가 점차 학습에서 추론 시간으로(테스트 시간 확장) 이동하고 그에 따라 비용도 증가하고 있습니다. 최종 사용자를 위한 유용한 AI 애플리케이션을 지원하려면 현재와 미래의 상호작용을 효율적으로 지원할 수 있는 소프트웨어가 필요합니다.
GKE의 AI 추론 기능 발표: Inference Gateway 및 Inference Quickstart
-
GKE Inference Gateway는 지능형 확장 및 부하 분산 기능을 제공하여 생성형 AI 모델 인식 확장 및 부하 분산 기법으로 요청 예약 및 라우팅을 처리할 수 있도록 지원합니다.
-
GKE Inference Quickstart를 사용하면 AI 모델과 원하는 성능을 선택할 수 있으며 GKE가 이에 맞게 적절한 인프라, 가속기, Kubernetes 리소스를 구성해 줍니다.
두 기능 모두 현재 프리뷰 버전으로 제공되며, 두 기능을 함께 사용하면 다른 관리형 및 오픈소스 Kubernetes 제품에 비해 서빙 비용을 30% 이상 줄이고 지연 시간을 60% 줄이며 처리량을 최대 40%까지 높일 수 있습니다.
TPU용 vLLM 지원: vLLM은 빠르고 효율적인 추론 라이브러리로 잘 알려져 있습니다. 이제 vLLM을 사용해 TPU에서 손쉽게 추론을 실행하고, 소프트웨어 스택을 변경하지 않고도 몇 가지 구성만 변경하여 TPU의 가격 대비 성능 이점을 누릴 수 있습니다. vLLM은 Compute Engine, GKE, Vertex AI, Dataflow에서 지원됩니다. 또한 GKE 커스텀 컴퓨팅 클래스를 사용하면 동일한 vLLM 배포 내에서 TPU와 GPU를 함께 사용할 수 있습니다.
더욱 유연한 소비
동적 워크로드 스케줄러(DWS)는 가속기에 저렴한 비용으로 쉽게 액세스할 수 있도록 지원하는 리소스 관리 및 작업 예약 플랫폼입니다. 오늘 Google Cloud는 DWS 가속기 지원 확대를 발표합니다. TPU v5e, Trillium, A3 Ultra(NVIDIA H200), A4(NVIDIA B200) VM을 flex-start 모드를 통해 프리뷰 버전으로 지원하며, 이달 말에는 TPU에 대한 캘린더 모드 지원이 제공될 예정입니다. 또한 flex-start 모드에서는 리소스를 즉시 프로비저닝하고 동적으로 확장할 수 있는 새로운 프로비저닝 방법을 지원하므로 장기 실행 추론 워크로드와 더 다양한 범위의 학습 워크로드에 적합합니다. 이는 모든 노드를 동시에 프로비저닝해야 하는 flex-start 모드의 큐 프로비저닝 방법과는 별도로 제공됩니다.
Next '25에서 AI 하이퍼컴퓨터에 대해 알아보기
최신 소식을 놓치지 마세요. 이벤트 웹사이트에서 모든 발표와 심층 분석을 만나보세요. 컴퓨팅 및 AI 인프라의 다음 단계를 시작으로 다음 세션을 확인해 보세요.
1. arXiv (LMArena), Chatbot Arena: An Open Platform for Evaluating LLMs by Human Preference, Wei-Lin Chiang, Lianmin Zheng, Ying Sheng, Anastasios 1 Nikolas Angelopoulos, Tianle Li, Dacheng Li, Hao Zhang, Banghua Zhu, Michael Jordan, Joseph E. Gonzalez, Ion Stoica, 2024. 2025년 3월 19일 기준 정보입니다. 이 벤치마크는 모델 출력 품질(인간 검토자가 판단)을 출력 생성에 필요한 가격/100만 토큰과 비교하여 효율성을 비교합니다. 여기서 '인텔리전스'란 모델 출력 품질에 대한 인간의 인식을 의미합니다.


