대규모 AI 추론을 가속화하는 Cloud TPU v5e

Alex Spiridonov
Group Product Manager, AI Infrastructure
Gang Ji
Senior Software Engineering Manager
*본 아티클의 원문은 2023년 9월 1일 Google Cloud 블로그(영문)에 게재되었습니다.
AI에 최적화된 Google Cloud의 인프라는 비즈니스가 최첨단 AI 모델의 추론을 학습시키고, 미세 조정하고, 실행하는 작업을 더욱 빠르게, 보다 대규모로, 더 낮은 비용으로 실현할 수 있게 해 주었습니다. Cloud TPU의 추론을 프리뷰 버전으로 발표하게 되어 기쁩니다. 새로운 Cloud TPU v5e는 최첨단의 최신 대규모 언어 모델(LLM) 및 생성형 AI 모델 등 다양한 AI 워크로드에 비용 효율적인 고성능 추론을 지원합니다.
새로운 모델이 공개되고 AI가 보다 정교해짐에 따라 비즈니스에는 더욱 강력하고 비용 효율적인 컴퓨팅 옵션이 필요합니다. AI 우선 기업인 Google은 수십억의 사용자와 Google의 클라우드 고객이 이용하고 있는 YouTube, Gmail, Google 지도, Google Play, Android 등의 Google 제품이 요구하는 글로벌 규모와 성능에 맞추기 위해 AI에 최적화된 인프라를 구축했습니다.
LLM과 생성형 AI의 혁신에는 AI 모델을 학습시키고 제공하는 데 막대한 양의 연산이 필요합니다. Google은 이와 같이 증가하는 연산 수요를 효율적인 비용으로 충족할 수 있도록 Cloud TPU v5e를 맞춤 설계하여 빌드하고 배포했습니다.
AI 추론 워크로드 가속화를 고려한다면 Cloud TPU v5e는 훌륭한 선택지입니다.
- 비용 효율성: TPU v4에 비해 추론에서 달러당 최대 2.5배 뛰어난 성능과 최대 1.7배 짧은 지연 시간을 보여줍니다.
- 확장성: 8개 TPU 형태가 다양한 규모의 LLM 및 생성형 AI 모델에서 최대 2조 개 매개변수를 지원합니다.
- 다목적성: 강력한 AI 프레임워크 및 조정 지원을 제공합니다.
이 블로그에서는 TPU v5e를 AI 추론에 효과적으로 활용할 수 있는 방법을 자세히 알아보겠습니다.
추론에서 달러당 최대 2.5배 뛰어난 성능과 최대 1.7배 짧은 지연 시간
각 TPU v5e 칩은 int8 작업을 초당 최대 393조 개까지(TOPS) 제공하므로 복잡한 모델에서도 빠른 예측이 가능합니다. 하나의 TPU v5e 포드는 초고속 링크를 통해 네트워크로 연결된 256개의 칩으로 구성됩니다. 각 TPU v5e 포드는 초당 최대 100,000조 int8 작업 또는 100페타옵스의 컴퓨팅 성능을 제공합니다.
Google은 Cloud TPU 추론 소프트웨어 스택을 최적화하여 이와 같은 강력한 하드웨어를 최대한 활용할 수 있도록 했습니다. 추론 스택은 TPU를 위한 고효율 코드를 생성하는 Google의 AI 컴파일러인 XLA를 활용하여 성능과 효율성을 극대화합니다.
int8 양자화를 비롯한 하드웨어와 소프트웨어 최적화의 결합 덕분에 Cloud TPU v5e는 Llama 2, GPT-3, Stable Diffusion 2.1과 같은 최첨단 LLM 및 생성형 AI 모델에서 Cloud TPU v4에 비해 달러당 최대 2.5배 뛰어난 추론 성능을 달성할 수 있게 되었습니다.
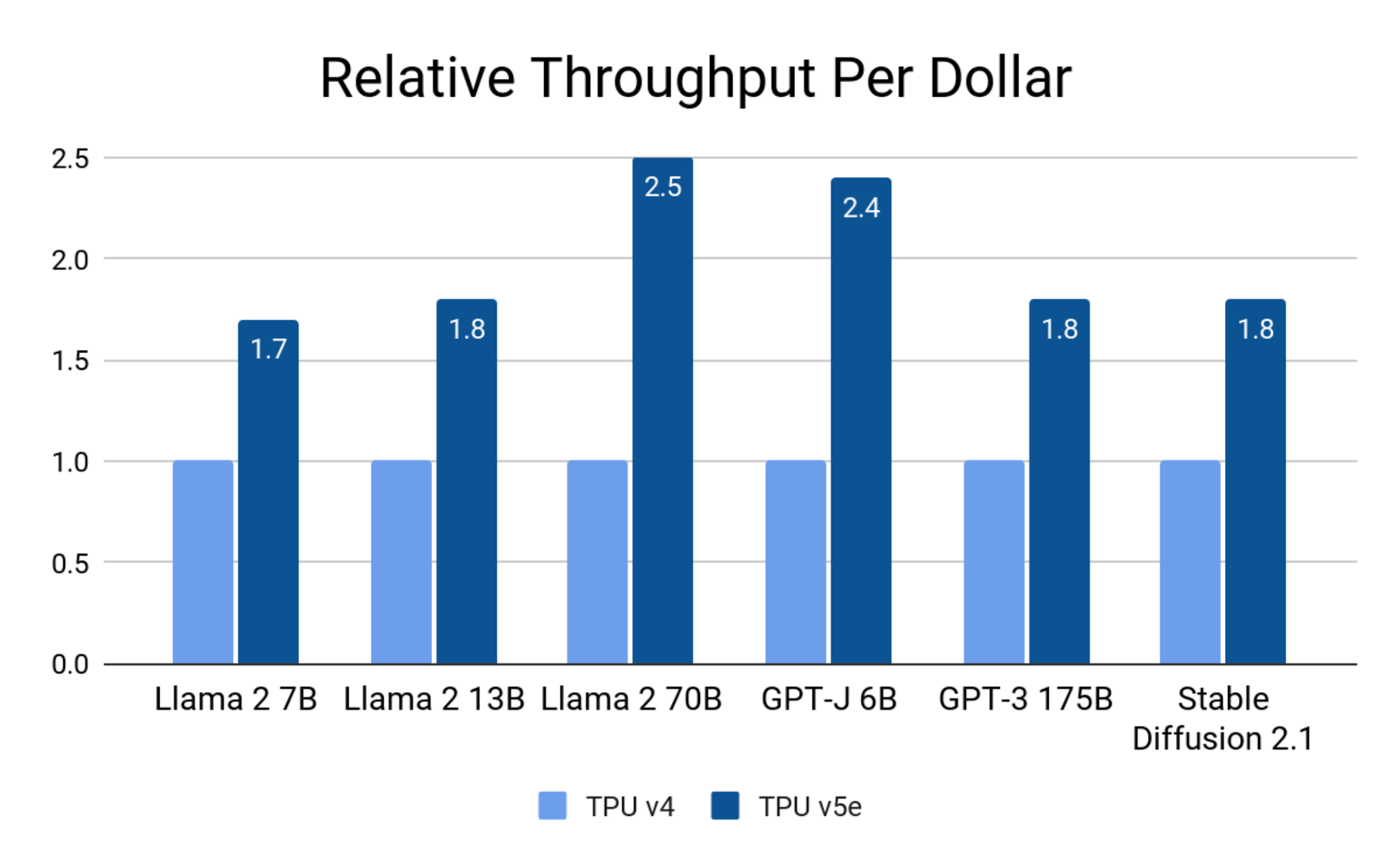
Google 내부 데이터. 2023년 8월. 단일 칩 처리량으로 정규화. 정밀도: Llama 2 7B, 13B, 70B, GPT-J 6B: int8; GPT-J 175B, Stable Diffusion 2.1: bf16.
Cloud TPU v5e가 TPU v4에 비해 최대 1.7배 지연 시간 단축:
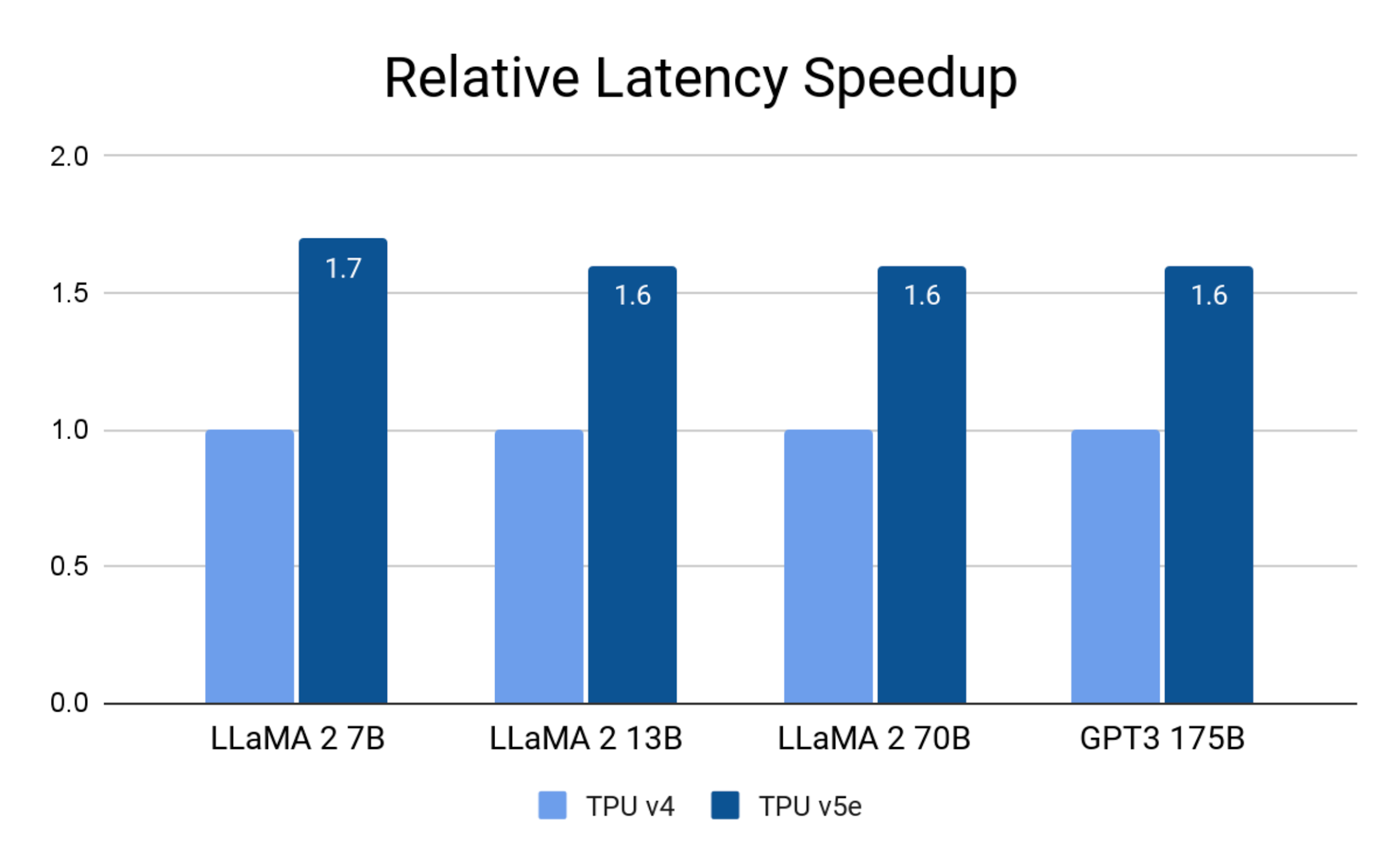
Google 내부 데이터. 2023년 8월. 정밀도: Llama 2 7B, 13B 및 70B: int8; GPT-3 175B: bf16.
Google Cloud 고객은 Cloud TPU v5e에서 추론을 실행해 왔으며, 일부 고객은 특정 워크로드에서 더 빠른 속도를 경험하기도 했습니다.
AssemblyAI는 고객이 음성 인식 및 이해에 사용할 수 있는 수십 개의 AI 모델과 매일 2,500만 회 이상의 추론 호출을 제공합니다.
“Cloud TPU v5e는 자사의 프로덕션 모델에서 추론을 실행하는 데 시장의 경쟁 솔루션보다 달러당 최대 4배 뛰어난 성능을 일관되게 제공해 주었습니다. Google Cloud 소프트웨어 스택은 최고 수준의 성능과 효율성을 달성하는 데 최적화되어 있으며, 가장 진화한 형태의 AI 및 ML 모델을 가속화하려는 목적으로 빌드된 TPU v5e 하드웨어를 최대한 활용합니다. 강력한 성능과 다목적성을 겸비한 이 하드웨어와 소프트웨어의 조합은 솔루션 구현 시간을 대폭 단축해 주었습니다. 커스텀 커널을 직접 조정하는 데 몇 주를 소요하는 대신 몇 시간 안에 모델이 우리의 추론 성능 목표를 초과 달성하도록 최적화할 수 있었습니다.” – 도미닉 도나토, AssemblyAI 기술 부문 부사장
다양한 규모의 LLM 및 생성형 모델로 확장 가능
LLM 및 생성형 AI 모델은 그 규모와 연산 비용이 계속해서 증가하고 있습니다. 규모가 가장 큰 모델이라면 수백 개의 하드웨어 가속기를 통한 컴퓨팅과 메모리가 필요합니다. Cloud TPU v5e는 다양한 규모의 모델을 위한 추론을 지원합니다. 하나의 v5e 칩은 최대 130억 개 매개변수를 가진 모델을 실행할 수 있습니다. 이를 시작으로 최대 수백 개의 칩으로 확장이 가능하며, 최대 2조 개의 매개변수를 가진 모델까지 실행할 수 있습니다.
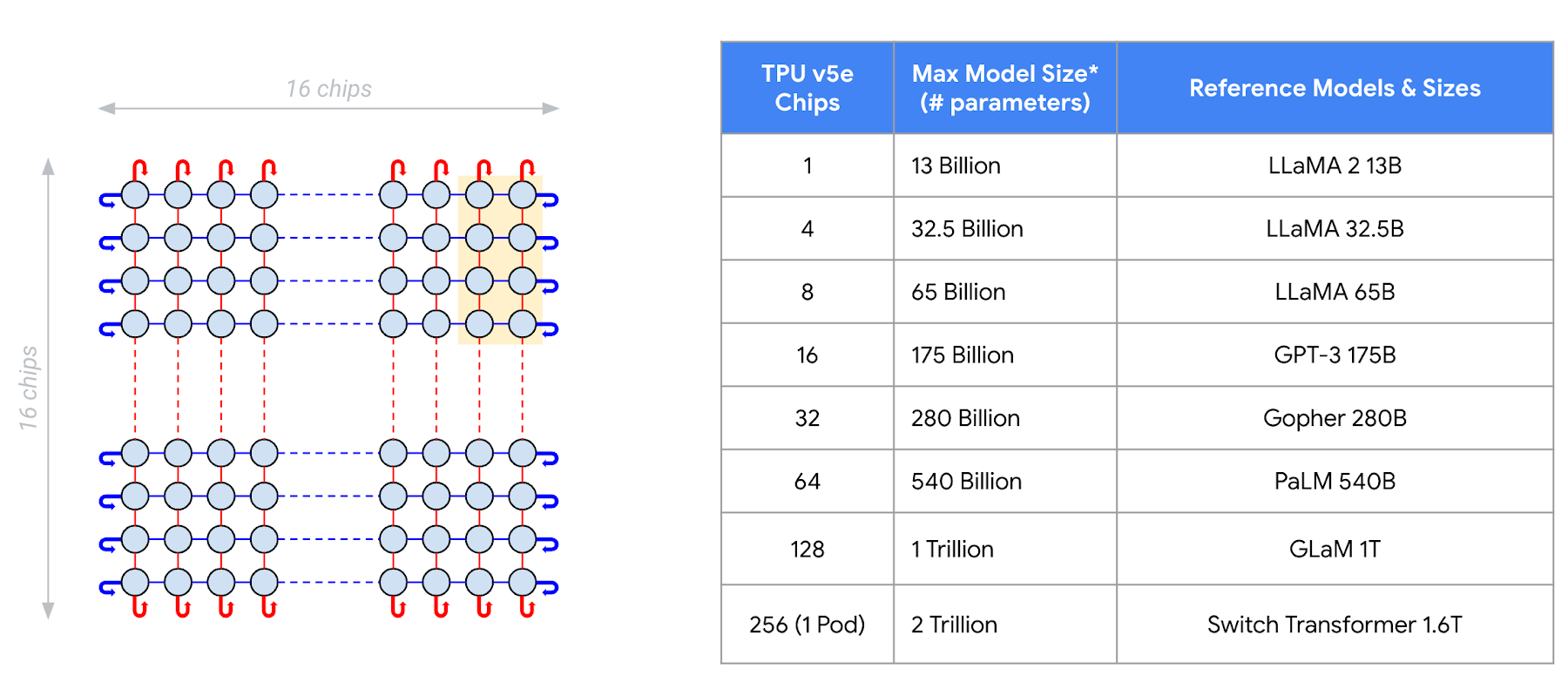
Google 내부 데이터. 2023년 8월. 배치 크기 = 1. 디코더 전용 언어 모델을 기반으로 하는 멀티 헤드 어텐션: 프리픽스 길이 = 2048, 디코딩 단계 = 256, 빔 크기 = 32(샘플용)
Gridspace는 Google Cloud TPU 인프라를 활용해 풀 스택 대화형 AI 플랫폼을 구동하며 실시간 대화형 ASR, LLM, 시맨틱 검색, 신경망 텍스트 음성 변환을 빌드하고 통합합니다.
“우리는 Google Cloud TPU를 정말 좋아합니다. 당사 벤치마크에서는 Google Cloud TPU v5e에서 학습 및 실행 시 AI 모델의 속도가 5배 증가한 것으로 나타났습니다. 또한 추론 측정항목 규모도 6배 향상되었습니다. 당사는 Google Cloud의 AI 인프라를 활용해 금융 서비스, 자본 시장, 의료 분야에 걸쳐 AI 모델을 1년에 수십억 개 대화로 확장했습니다. 당사의 Grace 봇은 Cloud TPU를 사용해 학습된 모델로 구동되며 GKE에서 대규모로 제공될 뿐 아니라 PCI, HITRUST, SOC 2 규정 준수를 지원합니다.” – 이원겸, Gridspace 머신러닝 부문 책임자
강력한 AI 프레임워크 및 조정 지원
PyTorch, JAX, TensorFlow를 비롯한 선도적인 AI 프레임워크는 Cloud TPU v5e에서의 추론을 위한 강력한 지원을 제공합니다. 이제 모델을 Clouod TPU에서 엔드 투 엔드로 학습시키고 제공할 수 있습니다. 다시 말해, 모델을 제공할 목적에 맞게 학습시킬 수 있습니다.
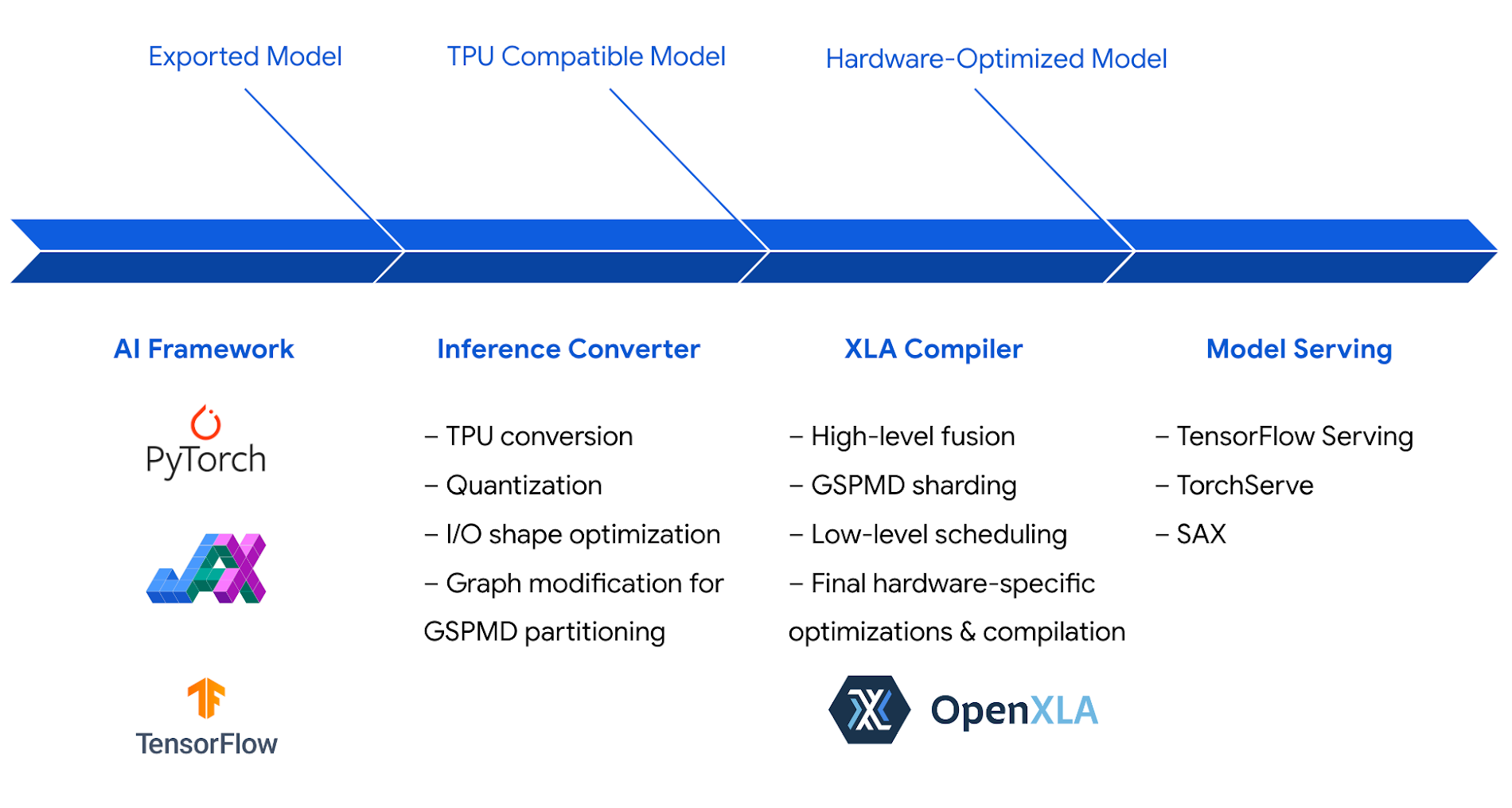
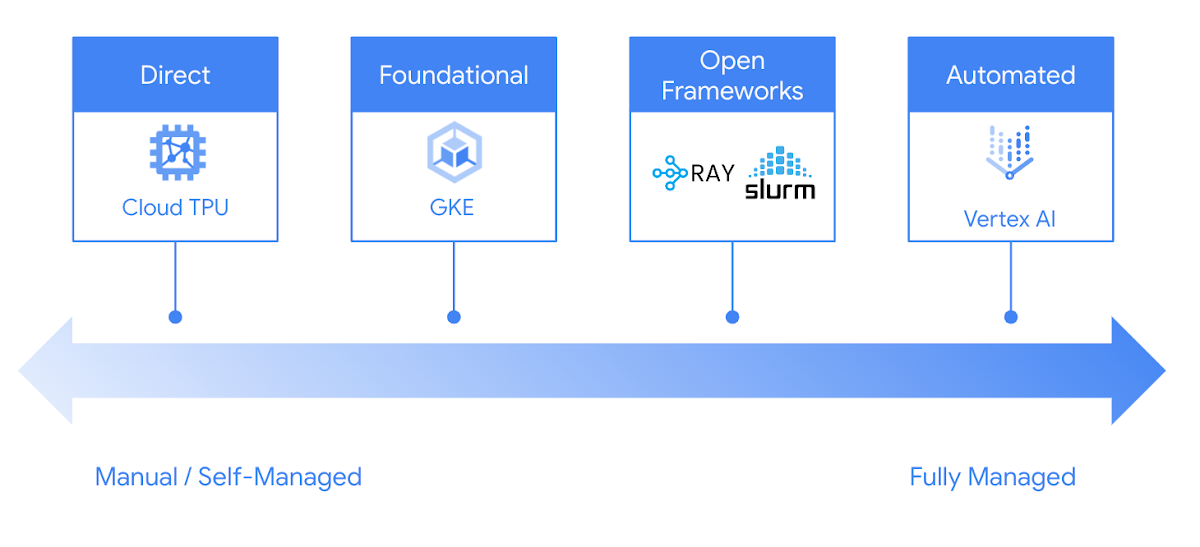
Google Cloud는 Cloud TPU에서 추론을 안정적이고 손쉽게 실행할 수 있는 많은 선택지를 제공합니다. GKE와 Vertex AI부터 Ray와 Slurm 같은 널리 사용되는 오픈소스 프레임워크까지, 개발 과정에 맞게 선호하는 방식으로 Google Cloud TPU를 활용할 수 있습니다.
지금 바로 추론에 Cloud TPU v5e를 사용해 보세요
Cloud TPU v5e는 LLM과 생성형 AI 모델을 위한 비용 효율적이고 확장 가능하며 안정적인 고성능 추론 플랫폼을 제공합니다. 여러 선도적인 AI 회사에서는 AI 모델을 대규모로 제공하는 데 Cloud TPU v5e를 활용하고 있습니다.

Cloud TPU에서 추론을 시작하려면 Google Cloud 계정 관리자 또는 Google Cloud 영업팀에 문의하세요.



