ML で加速する分散型コンピューティングの第 5 エポックにおける成長
Google Cloud Japan Team
※この投稿は米国時間 2024 年 2 月 16 日に、Google Cloud blog に投稿されたものの抄訳です。
編集者注: 本日は、Google で ML、システム、クラウド AI 担当バイス プレジデント兼ゼネラル マネージャーを務める Google Fellow の Amin Vahdat に話を聞きます。Amin は、この内容を 2023 年にワシントン大学で Allen School の Distinguished Lecture シリーズの基調講演として初めて発表しました。本投稿は、分散型コンピューティングの歴史と現状、そして次世代のコンピューティング サービスへの期待について、Amin の考察をまとめたものです。
ここ 50 年間でコンピューティングと通信は容量、効率性、機能が継続的かつ飛躍的に向上し、社会に変革をもたらしてきました。その間に、CPU のトランジスタ数は 5,000 万倍になり、インターネットのノード数は 4 つから 53 億 9,000 万にまで増加しました。
このような進歩は目覚ましいものですが、それがもたらす人間の能力向上はそれ以上に魅力的であり、以前は SF でしか考えられなかった領域に近づきつつあります。現在では、進化し続ける人間の知識にほぼ瞬時にアクセスでき、限界があるのはそれを理解する人間の能力だけです。リアルタイムに言語を翻訳できるようになり、人間のコミュニケーションに対する根本的な障壁が打ち破られています。検知とネットワークの速度がともに向上したことでリアルタイムのホログラフィック投影が可能になり、離れた場所にいる相手とも有意義な対話が持てるように活用されることになるでしょう。また、このようなコンピューティング能力の爆発的な向上により、科学とエンジニアリングの分野における現代の困難な課題を解決する次世代の AI システムが実現しています。たとえば、タンパク質の 3D 構造予測はほぼ即時に、原子レベルでの精度で可能になっており、その他にもテキストからイメージへの高度な拡散技術により、ユーザー プロンプトに合致する高品質で極めてリアルな出力を得ることができます。
基礎となる技術を継続的に進歩させるのは、容易ではありませんでした。技術の根幹にかかわる問題が 10~15 年ごとに顕現し、そのたびに、インフラストラクチャの性能と規模の急速な拡大を維持するため、抜本的な発明とブレークスルーが必要になりました。結果的にまったく新しいカテゴリのサービスが生み出されてきました。それはまるで、克服しなければならない根本的な制限が次々と新たに突きつけられ、それらの制限がより厳しくなり続けることで、革新的な機会が生み出されているようでした。今、世界はこのような一世代に一度の難局に直面しています。これはチャンスでもあります。コンピューティングの根本的な需要が果てしなく増大し続ける中で、驚異的な速度で進歩し続け、さらに加速化できるかどうかがかかっています。
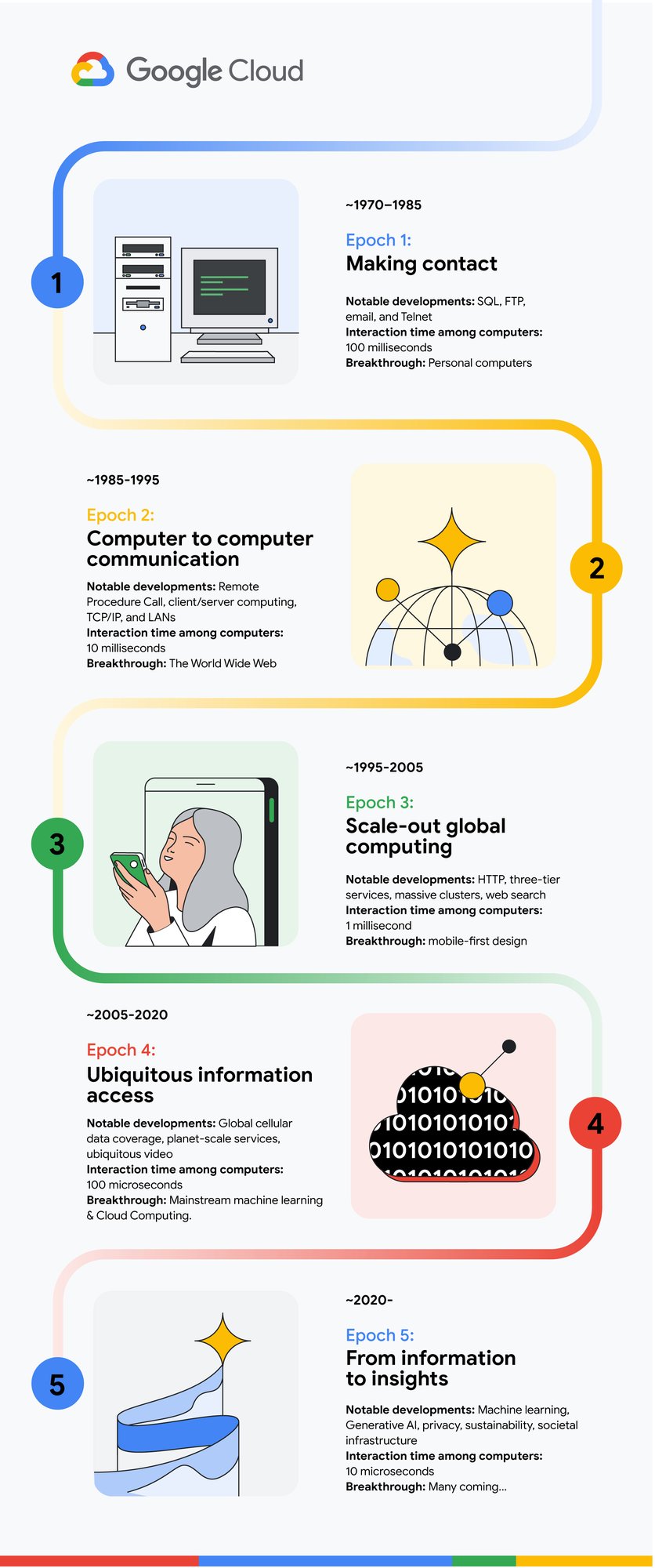
コンピューティングの歴史を簡単に振り返ると、コンピューティングの「エポック」をそれぞれ定義する 4 つの大きな移行期を経てきたことがわかります。このように歴史を分類すると、コンピューティングの第 5 エポックを定義し、推進していくべき明白な必要性が見えてきます。このエポックは、データ中心、宣言型、結果指向、ソフトウェア定義という特徴を持ち、分析情報をプロアクティブに提供することに重点を置いています。過去の各エポックでも、それまで想像もできなかったことが当たり前になりましたが、この第 5 エポックは過去最大の変革をもたらし、知識と機会がより広く行き届くことが期待されています。しかし同時に、このエポックでは、コンピューティングに関してこれまで積み上げられてきた本質的に最も困難な課題をいくつか克服する必要もあります。
まずはエポック 0 を振り返ってみましょう。厳密には数千年前にまで遡るべきだと主張する人もいるかもしれませんが、ここでは 1947 年から 1969 年までの間に起こったコンピュータ サイエンスの重要かつ基本的な発展から話を始めることにします。この時代には、現代のコンピューティングと通信の基礎が築かれました。
1947 年: バーディーン、ブラッテン、ショックレーが世界初のトランジスタを発明する。
1948 年: シャノンがあらゆるネットワーク通信の基礎となる情報理論を考案する。
1949 年: コンピュータの内蔵プログラムが実用化される。
1956 年: 高水準プログラミング言語が発明される。
1964 年: 複数のハードウェア世代で一般的に使用される命令セット アーキテクチャが登場する。
1965 年: 集積回路あたりのトランジスタ数が 18~24 か月ごとに 2 倍になるというムーアの法則が発表される。
1967 年: マルチユーザー オペレーティング システムにより、保護されたリソース共有が実現する。
1969 年: 現代のインターネットの基礎となる ARPANET が誕生する。
これらのブレークスルーにより、エポック 0 の終わりまでには現代のコンピューティングの基礎が形成されました。つまり、安定した命令セット アーキテクチャを実行する集積回路を基盤とする 4 台のコンピュータと、パケット交換方式のインターネットに接続されたマルチユーザー対応のタイム シェアリング オペレーティング システムです。一見地味に見えますが、これが後のエポックにおける急速な進化の基盤となりました。
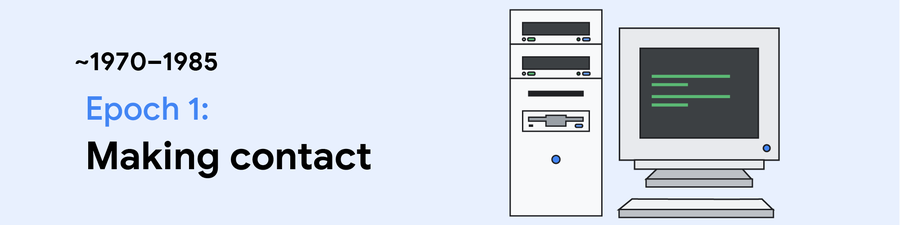
第 1 エポックでは、コンピュータ ネットワークは主に非同期方法で使用されていました。つまり、ネットワーク経由で(FTP などを介して)データを転送し、処理した後で、結果を送り返していました。
主な進歩: SQL、FTP、メール、telnet
コンピュータ間のインタラクション時間: 100 ミリ秒
特徴:
• 低帯域幅、高レイテンシのネットワーク
• 高価なコンピュータ間でまれに行われる相互インタラクション
• 人間との文字によるキーストローク インタラクション
• オープンソース ソフトウェアの登場
ブレークスルー: パソコン
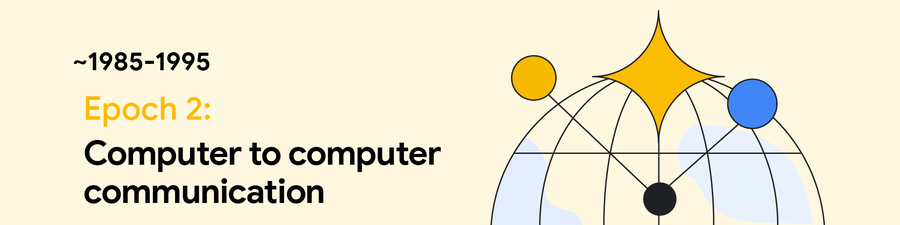
ネットワーク速度の向上、パソコンとワークステーションの普及、相互運用性のある幅広いプロトコル(IP、TCP、NFS、HTTP)により、第 2 エポックでは同期的で透過的なコンピューティングと通信が普及しました。
主な進歩: リモート プロシージャ コール、クライアント/サーバー コンピューティング、LAN、リーダー選出とコンセンサス
コンピュータ間のインタラクション時間: 10 ミリ秒
特徴:
• 10 Mbps ネットワーク
• TCP/IP によるインターネット アーキテクチャのグローバルなスケーリング
• チップに完全に収まる 32 ビット CPU
• 複数コンピュータ間でのリソース共有
ブレークスルー: ワールド ワイド ウェブ

第 3 エポックでは、HTTP とワールド ワイド ウェブの本格的なブレークスルーによってネットワーク コンピューティングが一般に普及し、パーソナル コンピューティングの限界が打ち破られました。急速な成長を続けるインターネットと、グローバルなユーザー層のニーズに適応するため、現代のコンピューティングの設計パターンはこの時代に数多く確立されました。
第 3 エポックの推進要因の一つとなったのが、シングル CPU コアの最大クロック周波数を本質的に制限していたデナード スケーリングの終了でした。この制限により、業界はマルチコア アーキテクチャを採用し、非同期、マルチスレッド、同時実行の開発環境への移行が必要になっていました。
主な進歩: HTTP、3 層サービス、巨大クラスタ、ウェブ検索
コンピュータ間のインタラクション時間: 1 ミリ秒
特徴:
• 100 Mbps~1 Gbps のネットワーク
• 自律システムと BGP • 単一サーバーでは複雑なアプリに対応できなくなり、複数サーバーにスケーリング
• ウェブ インデックス作成とウェブ検索、一般へのメールの浸透
ブレークスルー: クラスタベースのインターネット サービス、モバイルファースト デザイン、マルチスレッディング、命令レベルの並列性

第 4 エポックでは、広く普及したモバイル デバイスを介して数十億人が利用できる全世界規模のサービスが確立されました。同時に、ML の進化によってリアルタイムのコントロールと分析が推進されました。これらすべての基盤となったのが、高速ネットワークで相互接続され、連動して膨大なデータセットをリアルタイムで処理するウェアハウス規模のクラスタでした。
主な進歩: グローバルなモバイルデータ カバレッジ、世界規模のサービス、場所を問わずアクセスできる動画
コンピュータ間のインタラクション時間: 100 マイクロ秒
特徴:
• 10~100 Gbps のネットワーク、flash
• 各 CPU ソケットに複数のコア
• LAN を横断してスケールアウトするインフラストラクチャ(例: GFS、MapReduce、Hadoop)
• モバイルアプリ、グローバルなモバイルデータ カバレッジ
ブレークスルー: 主流となった ML、即時に利用可能な専門的コンピューティング ハードウェア、クラウド コンピューティング
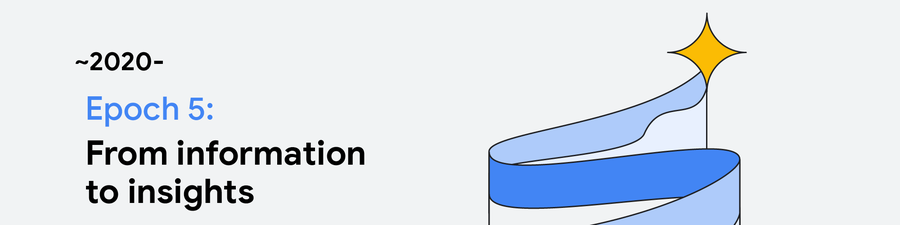
現在は第 5 エポックに移行しましたが、このエポックには 2 つの相反する傾向があります。まず、ASIC あたりのトランジスタ数は急速に増加し続けている一方で、クロックレートには変化がなく、各トランジスタのコストもほぼ横ばいとなっています。これらの改善を抑制している要因は、複雑化と、機能サイズの縮小に必要な投資の増大です。これは、コンピューティング、DRAM、ストレージ、ネットワーク インフラストラクチャのすべてで、コストに対するパフォーマンスの向上(パフォーマンス効率)が頭打ちになっていることを意味します。一方で、ユビキタスなネットワーク カバレッジ、幅広く設置されたセンサー、データを大量に消費する ML アプリケーションなどにより、物理的なコンピューティング インフラストラクチャの需要は爆発的に高まっています。
主な進歩: ML、生成 AI、プライバシー、サステナビリティ、社会的インフラストラクチャ
コンピュータ間のインタラクション時間: 10 マイクロ秒
特徴:
• 200 Gbps~1 Tbps 以上のネットワーク
• ユビキタスで電力効率の高い高速ワイヤレス ネットワーク カバレッジ
• 専門化が進むアクセラレータ: TPU、GPU、スマート NIC
• ソケットレベルのファブリック、光学、連携アーキテクチャ
• 接続されたスペース、自動車、家電、ウェアラブルなど
ブレークスルー: 今後に期待
コンピューティングの設計と組織における根本的なブレークスルーがなければ、コンピューティング インフラストラクチャに対する社会の需要に応える能力は全体的に弱まります。このような制限を克服する新たなアーキテクチャ(新しいハードウェアとソフトウェアのアーキテクチャ)を生み出すことで、コンピューティングの第 5 エポックが定義されます。
コンピューティングの第 5 エポックで実現するブレークスルーを予測することはできませんが、過去の各エポックでは規模、効率、コスト パフォーマンスが 100 倍向上し、同時にセキュリティと信頼性も改善されました。規模と能力に対する要求が高まり続ける中、ムーアの法則とデナード スケーリングによる追い風なしでこのような成果を達成することは困難でしょう。しかし、第 5 エポックには大まかに以下が関連することが考えられます。
-
宣言型プログラミング モデル: 専用プロセッサにおける順次コード実行のフォンノイマン モデルは、デベロッパーにとってここ数十年間非常に有用なモデルでした。しかし、分散型のマルチスレッド コンピューティングの台頭によって抽象化は崩壊し、現代の命令コードの多くでは非同期性、異種性、テール レイテンシ、オプティミスティック同時実行、障害を管理するために防御的で多くが非効率的な構成概念に焦点が当てられています。複雑さは今後数年は高まり続ける見込みで、インテント、ユーザー、ビジネス ロジックに焦点を当てた新しい宣言型プログラミング モデルの登場が不可欠です。また、実行フローの管理と、変化するデプロイ条件への対応には、今以上に高度なコンパイラと、ML を利用したランタイムを使用する必要があります。
-
ハードウェア セグメンテーション: これまでのエポックでは、CPU、メモリ、ストレージ、ネットワーキングのシステム バランスを備えた汎用サーバー アーキテクチャが、データセンター全体のワークロードのニーズを効率的に満たすことができていました。しかし、専門的なコンピューティングのニーズ、ML トレーニング、推論、動画処理に対応した設計では、ストレージ、メモリ容量、レイテンシ、帯域幅、通信の要件が相反するために、異種設計が急増しています。汎用コンピューティングのパフォーマンスが年に 1.5 倍のペースで向上していた時代には、複雑さを考えると、ワークロードの 10% に対して 5 倍の改善を目指すことでさえ意味がありませんでした。現在は、この程度の改善も無視できなくなっています。このギャップに対処するには、コンポーズ可能なハードウェア ASIC とメモリユニットを数年ではなく数か月で設計、検証、認定、デプロイするための新しいアプローチが必要になります。
-
ソフトウェア定義のインフラストラクチャ: 基盤となるインフラストラクチャの複雑化と分散化が進む中で、メモリから CPU までの複数の仮想化レイヤにより、個別のアプリケーションに対する単一サーバーの抽象化が維持されてきました。インフラストラクチャがスケールアウトし続け、異種混合化が進む中で、このトレンドは次のエポックでも継続する見込みです。ハードウェア セグメンテーション、宣言型プログラミング モデル、数千台のサーバーで構成される分散コンピューティング環境により、仮想化は個々のサーバーの範囲を超え、単一サーバー、複数サーバー、ストレージとメモリアレイ、クラスタでの分散コンピューティングが含まれるようになり、場合によってはキャンパス全体のリソースを統合して最終結果を効率的に提供できるようになります。
-
安全性が実証されたコンピューティング: 前のエポックでは、コンピューティング効率を維持するために、セキュリティと信頼性が意図せず犠牲となっていました。しかし、生活のオンライン化が進む中で、個人、企業、行政機関にとってプライバシーと機密性保持の必要性が急速に高まっています。データ主権や、派生データであってもその物理的な場所を制限する必要性は、行政機関の規定を遵守するためだけでなく、増加する ML 生成コンテンツのリネージを透明性を持って示すためにますます重要になります。ベースライン パフォーマンスを多少犠牲にしても、これらのニーズは最優先で満たす必要があります。
-
サステナビリティ: コンピューティングの第 3 エポックまでで、固定電源のパフォーマンスは飛躍的に向上しました。第 4 エポックにおけるデナード スケーリングの終了とともに、コンピューティングに関連する世界の電力消費量は急速に増加しましたが、その一部はクラウドホスト型のインフラストラクチャによって相殺されました。このインフラストラクチャでは、それまでのオンプレミス設計と比べ、電力効率が 2~3 倍向上するためです。また、クラウド プロバイダは、まずはカーボン ニュートラル、次にカーボンフリーの電源への移行に向けて幅広い取り組みを進めてきました。しかし、第 5 エポックではデータとコンピューティングに対する需要が増大し続け、さらに加速する可能性もあります。そのため、電力効率と二酸化炭素排出量は、システム評価の主要な指標になるでしょう。特に注目すべきは、インフラストラクチャの構築と提供のライフサイクル全体を通じたエンボディド カーボンの可視性向上と最適化が必要になることです。
-
アルゴリズムのイノベーション: パフォーマンスの急速な向上により、ソフトウェアの効率性改善は見過ごされがちになりました。しかし、基盤となるハードウェア コンポーネントの改善が鈍化する中で、ソフトウェアとアルゴリズムの改善に目が向けられることになるでしょう。調査によると、システムコードでソフトウェアを 2~10 倍最適化できる余地があります。ソフトウェアをこのように最適化できる余地を効率的に特定し、これらのメリットを本番環境システムで適切、確実、大規模に実現する手法を開発することは、重要な機会となります。コーディング LLM における最近のブレークスルーを活用し、この作業を一部自動化することで、第 5 エポックが大きく加速するはずです。
ここまでの内容をまとめると、第 5 エポックでは、MIPS あたりの費用、DRAM の GB あたりの費用、Gbps あたりの費用など、下位レベルのコンポーネント別指標ではなく、全体的なユーザー システム効率の指標(秒単位での有益な回答数)が重視されます。また、効率の単位は単純に単価あたりのパフォーマンスで測定されるものではなくなり、電力消費量と二酸化炭素排出量が明示的に考慮され、セキュリティとプライバシーが主要な指標として使用されます。またこれらすべてに対して、社会の依存度が高まっているインフラストラクチャの信頼性に関する要件も適用されます。まとめると、次世代のインフラストラクチャを提供するための新たな可能性は、以下のように数多く残されています。
-
ハードウェアとソフトウェアを含む分散インフラストラクチャのスケールアウト効率は、10 倍以上改善できる可能性があります。
-
ソフトウェア定義のインフラストラクチャにより、アプリケーション バランス ポイント(コンピューティング、アクセラレータ、メモリ、ストレージ、ネットワークなどの異なるシステム リソース間の比率)のマッチングでも、10 倍の改善を達成できる可能性があります。
-
従来の画一的な汎用コンピューティング アーキテクチャと比較して、次世代のアクセラレータとセグメント固有のハードウェア コンポーネントでは、10 倍以上の改善を達成できる可能性があります。
-
最後に、これは定量化するのが困難ですが、デベロッパーの生産性を改善すると同時に、信頼性とセキュリティを大幅に向上させるという非常に重要な機会もあります。
これらのトレンドを組み合わせると、次のエポックでは効率性をさらに 1,000 倍も劇的に向上させられる可能性があります。これが実現すれば、次世代のインフラストラクチャ サービスが定義され、おそらくマルチモーダル モデルと生成 AI のブレークスルーが中核となる次世代のコンピューティング サービスが可能になります。次世代のコンピューティングの意味を定義し、それを設計、デプロイする機会はめったに訪れません。この第 5 エポックにおける構造的転換には、おそらく過去最大の技術的変革と課題が伴い、コンピューティングの初期にはおそらく見られなかったレベルの責任、コラボレーション、ビジョンが求められます。
-ML、システム、クラウド AI 担当ゼネラル マネージャー兼バイス プレジデント Amin Vahdat
