Node.js アプリの作成および Cloud Functions でのデプロイのヒント
Google Cloud Japan Team
※この投稿は米国時間 2020 年 12 月 24 日に、Google Cloud blog に投稿されたものの抄訳です。
Google の DPE Client Library チームは、Google Cloud クライアント ライブラリのリリース メンテナンスとサポートを担当しています。基本的には、GitHub 上の 350 を超える Google のリポジトリのオープンソース管理者として活動しています。これは大仕事です。
この業務を広範囲でこなすには、ライセンスの検証、リリースの管理、テスト合格後の pull リクエスト(PR)の統合といった各種の共通タスクの自動化が不可欠です。こうした自動化を構築するために、Node.js ベースのフレームワーク Probot を採用することにしました。これにより、GitHub API からの Webhook をリッスンするウェブ アプリケーションを作成するプロセスを簡略化できます。[編集者注: このチームは Node.js に関する造詣が深く、共同執筆者の Benjamin Coe はかつて npm, Inc の第 3 エンジニアを務め、現在は Node.js の中心的なコラボレーターとして活動しています。]
また Probot フレームワークに加え、運用上のオーバーヘッドを削減することを目的として Cloud Functions でこれらの自動化をデプロイすることにしました。Cloud Functions は、Node.js アプリケーションを迅速かつ容易にホスト型サービスに変換する場合に最適な選択肢です。
Cloud Functions はユーザーベースの拡大に応じて自動的にスケールします。追加のハードウェアをプロビジョニングして管理する必要もありません。
npm モジュールの作成に慣れている場合は、いくつかの手順を追加するだけで、このモジュールを Cloud Functions の関数としてデプロイできます。その場合、gcloud CLI を使用するか、Google Cloud Console から処理します(「初めての関数: Node.js」を参照してください)。
Cloud Functions は、Cloud Logging や Cloud Monitoring などの Google Cloud サービスと自動的に連携します。
Cloud Functions は、Firestore、Pub/Sub、Cloud Storage、Cloud Tasks などのサービスからイベントによってトリガーできます。
そして 2 年後の現在、GitHub からのリクエストを毎日 200 万件以上処理する 16 の自動化を管理しています。Cloud Functions を使用した自動化のデプロイも継続しています。コントリビューターは自動化の作成に集中でき、それらの自動化は本番環境に関数として簡単にデプロイできます。
サーバーレスを考慮した設計には、アプリケーションの構成、デプロイ、デバッグの方法に関して独自の課題がありますが、それを差し引いてもメリットがあると考えています。以降では、この直接的な体験に基づき、Node.js アプリケーションを Cloud Functions でデプロイするためのベスト プラクティスをご紹介します。ここで重視している目標は以下のとおりです。
パフォーマンス - リクエストを迅速に処理し、コールド スタート時間を最小限に抑える関数を作成する。
オブザーバビリティ - 例外が発生したときにデバッグしやすい関数を作成する。
プラットフォームの活用 - アプリケーション開発における Cloud Functions と Google Cloud の制約を理解する(リージョンとゾーンの理解など)。
これらの概念を完全に理解すれば、皆様もサーバーレス環境で Node.js ベースのアプリケーションを実行することから得られる運用上のメリットを手にすると同時に、潜在的な落とし穴を回避できるようになります。
アプリケーションの構成のベスト プラクティス
このセクションでは、Node.js ランタイムの属性についてご説明します。これらは、Cloud Functions のデプロイを目的としたコードの作成時に念頭に置く必要があります。特に以下の点に注意を払ってください。
npm の平均的なパッケージには 86 の一時的な依存関係から構成されるツリーがあります(参照: How much do we really know about how packages behave on the npm registry?)。アプリケーションの依存ツリーの合計サイズを考慮することが重要です。
Node.js API は一般にデフォルトで非ブロッキングであり、これらの非同期オペレーションが関数のリクエストのライフサイクルに関与することがあります。アプリケーションのバックグラウンドで意図せず非同期処理を作成しないようにしてください。
これをベースに、Cloud Functions で実行される Node.js コードの作成に最適なアドバイスをご紹介します。
1. 依存関係を適切に選ぶ
内部で Cloud Functions が実行される gVisor サンドボックスのディスク オペレーションには、ノートパソコンの一般的なオペレーティング システムよりも時間がかかるでしょう(gVisor ではオペレーティング システムの上に追加のセキュリティ レイヤがあり、その代償としてある程度のレイテンシが発生するため)。そのため、npm 依存関係ツリーを最小化すると、アプリケーションのブートストラップに必要な読み取りを削減でき、コールド スタートのパフォーマンスが改善します。
コマンド npm ls --production を実行すると、アプリケーションが持つ依存関係の概数を把握できます。その後、オンライン ツールの bundlephobia.com を使用して個々の依存関係を分析(合計バイトサイズなど)できます。使用していない依存関係はアプリケーションから削除する必要があります。また、小さい方の依存関係を優先してください。
同様に重要な点が、依存関係からインポートするファイルを慎重に選択することです。たとえば、npm の googleapis というライブラリがあります。require('googleapis') を実行すると、Google API のインデックス全体が取得され、数百ものディスク読み取りオペレーションが発生します。代わりに、以下のように処理対象の Google API のみを取得できます。
通常、ライブラリでは、使用するメソッドを選択して取得できます。インデックス全体を取得する前に、依存関係が類似した機能を備えているかどうかを必ず確認してください。
2. 「require-so-slow」を使用して require 時のパフォーマンスを分析する
アプリケーションの require 時のパフォーマンスを分析できる優れたツールが require-so-slow です。このツールによりアプリケーションの require ステートメントのタイムラインを出力し、DevTools Timeline Viewer に読み込むことができます。たとえば、googleapis のカタログ全体を読み込む場合と、必要な API のみ(ここでは SQL API)を読み込む場合を比べてみましょう。
require('googleapis') のタイムライン:
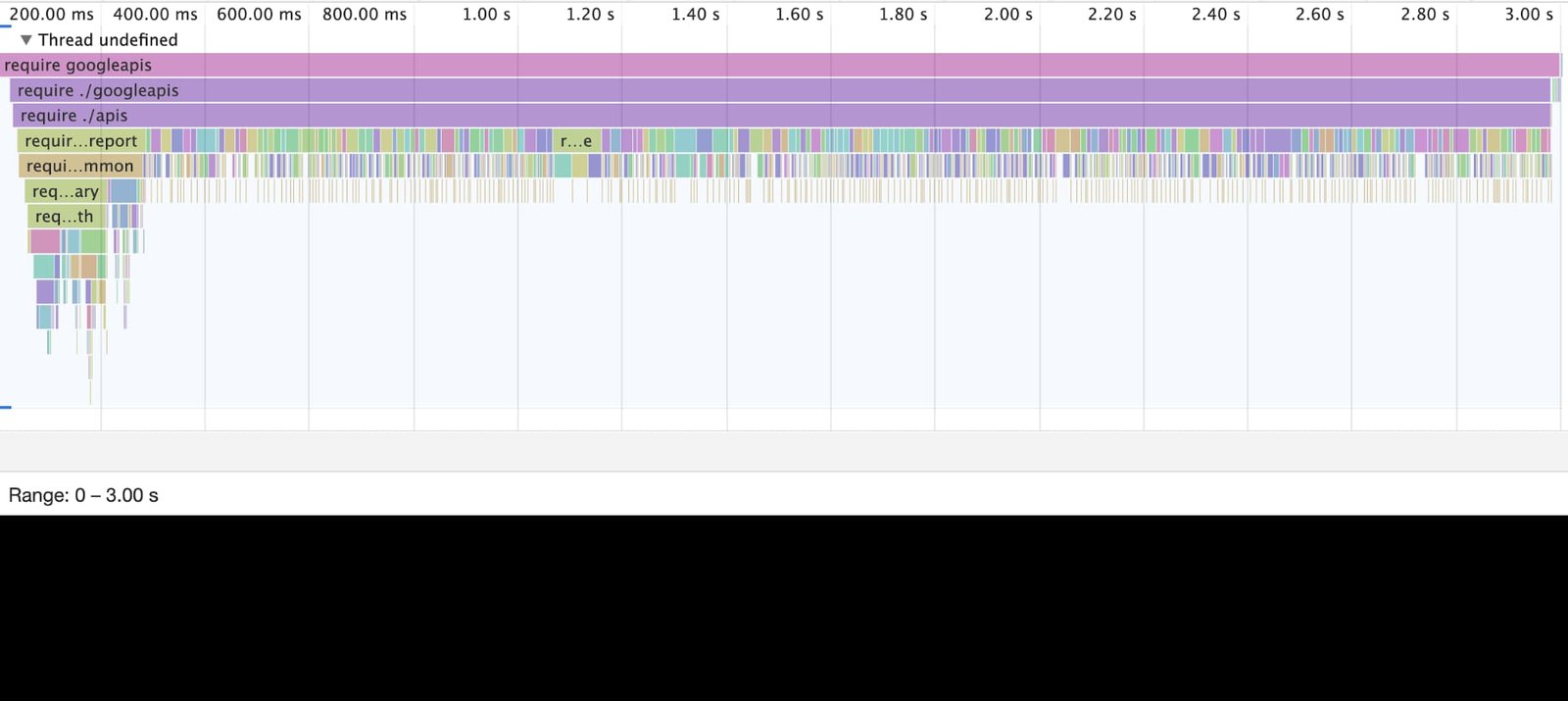
上の図は、googleapis の依存関係を読み込むための合計時間を示しています。コールド スタートに、図の全体に及ぶ 3 秒がかかっています。
require('googleapis/build/src/apis/sql') のタイムライン:
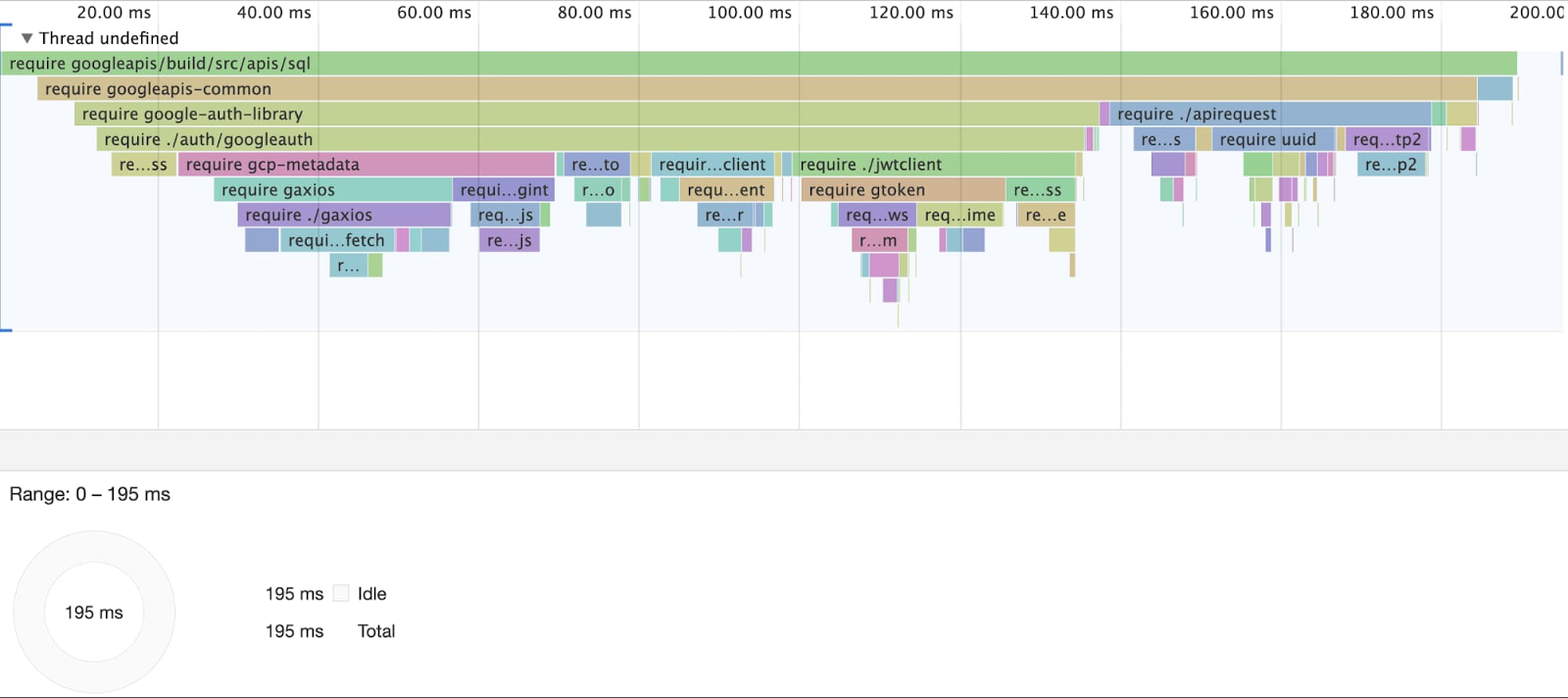
上の図は、sql サブモジュールのみを読み込むための合計時間を示しています。コールド スタートの時間は実に 195 ミリ秒です。
つまり、直接 SQL API を要求すれば、googleapis インデックス全体を読み込む場合よりも 10 倍も速くなるのです。
3. リクエストのライフサイクルを理解し、落とし穴を回避する
Cloud Functions のドキュメントには、実行のタイムラインに関して次のような警告が記載されています。関数は、その実行期間にのみ、要求したリソース(CPU とメモリ)にアクセスできます。実行期間外に実行されるコードは必ず実行されるとは限りません。これらのコードはいつでも停止できます。
Node.js では API の多くがデフォルトで非同期であるため、この問題がよく発生します。アプリケーションを構成するときは、すべての非同期処理が完了した後にのみ res.send() が呼び出されるようにすることが重要です。
以下は、リソースが予期せず無効になる関数の例です。
上の例では、set() によって作成された Promise が、res.send() の呼び出し時も引き続き実行されています。これは、以下のように記述し直す必要があります。
このコードはもう実行期間外で実行されることはなくなります。なぜなら、set() を待機してから res.send() を呼び出すためです。
こうした種類のバグをデバッグする際は、ロギングを適切な場所に配置するとよいでしょう。つまり、アプリケーションの重要な非同期ステップの後にデバッグラインを追加します。このログには、関数がリクエストを開始するタイミングに関する情報を含めます。その後、ログ エクスプローラを使用して単一のリクエストをチェックし、出力が予想と一致していることを確認します。ログエントリが欠けていたりエントリがかなり遅れている(後続のリクエストにリークしている)場合は、Promise が未処理であることを意味します。
コールド スタート中は、グローバル スコープのコード(ソースファイルの最上部、ハンドラ関数の外にあるもの)は通常の関数実行のコンテキスト外で実行されます。グローバル スコープでは、常に実行期間外で実行される fs.read() のような非同期処理は一切行わないでください。
4. グローバル スコープを理解し、効果的に利用する
グローバル スコープでは、require ステートメントのような「負荷の高い」同期オペレーションを実行できます。コールド スタート時間のベンチマーク時に、require ステートメントを(関数内で遅延読み込みするのではなく)グローバル スコープに移動することで、コールド スタート時間を 500 ミリ秒~1 秒改善できることがわかりました。これは、ブートストラップ中に Cloud Functions にコンピューティング リソースが割り振られるという事実によります。
また、fs.readFileSync のような他の負荷の高い 1 回限りの同期オペレーションをグローバル スコープに移動することも検討してください。実行期間外で実行されるため、非同期オペレーションを回避するための重要なポイントです。
Cloud Functions は実行環境をリサイクルします。つまり、グローバル スコープを使用すると、関数の呼び出し中も変化のない、負荷の高い 1 回限りのオペレーションをキャッシュできます。
非同期オペレーションを待機してからレスポンスを送信することが重要ですが、グローバル スコープにはレスポンスをキャッシュできます。
5. 負荷の高いバックグラウンド オペレーションを Cloud Tasks に移動する
Cloud Functions の関数のスループットを改善する(つまり、コールド スタート中の全体的なレイテンシを削減し、トラフィックの急増時に必要になるインスタンスを最小限に抑える)には、リクエスト ハンドラの外に処理を移動するとよいでしょう。たとえば、負荷の高いデータベース オペレーションを複数実行する以下のようなアプリケーションがあるとします。
ユーザーに送信されるレスポンスには、データベース更新によって返される情報は一切必要ありません。これらのオペレーションが完了するのを待つのではなく、Cloud Tasks を使用して、このオペレーションを別の Cloud Functions の関数でスケジュールし、ユーザーに即座に対応することができます。これには、Cloud Tasks キューが再試行をサポートするため、アプリケーションでの断続的なエラー(1 回限りのデータベース書き込みエラーなど)の発生を回避できるという利点もあります。
以下は、前述の例をユーザー向け関数とバックグラウンド関数に分割したものです。
ユーザー向け関数:
バックグラウンド関数:
アプリケーションのデプロイ
この記事の次のセクションでは、アプリケーションのデプロイ時に考慮すべきメモリやロケーションなどの設定について取り上げます。
1. メモリとパフォーマンスの関係を考慮する
関数に割り振るメモリを増やすと、割り振る CPU も増えます(参照:「コンピューティング時間)。起動時に大量の依存関係を必要とするアプリケーションやコンピューティング コストの高いオペレーションを実行するアプリケーションなど、CPU バウンドのアプリケーションの場合(参照:「ImageMagick のチュートリアル」)、リクエストとコールド スタートのパフォーマンスを改善するための最初のステップとしてさまざまなインスタンスのサイズを試す必要があります。
また、実行時の関数に妥当な量のメモリが割り当てられているかどうかについても注意する必要があります。メモリ制限にあまりにも近づいた状態で実行されるアプリケーションはメモリ不足エラーでクラッシュすることがあり、一般にパフォーマンスが予測不能になります。
Cloud Monitoring Metrics Explorer を使用すると、Cloud Functions の関数のメモリ使用状況を確認できます。実際にチームで確認したところ、Google の Node.js アプリケーションについては 128 MB のメモリでは不十分で、平均して 136 MB が必要でした。このため、256 MB の設定に変更したところ、メモリに関する問題は発生しなくなりました。
2. ロケーションの重要性
光速を考慮すると、最善の状況で TCP/IP トラフィックのレイテンシは 100 マイルあたり 2 ミリ秒以内ということになります1。これは、ニューヨーク市とロンドンの間でのリクエストで少なくとも 50 ミリ秒のレイテンシが発生することを意味します。アプリケーションを設計する際は、こうした制約を考慮する必要があります。
Cloud Functions の関数が他の Google Cloud サービスとやり取りする場合は、そのサービスと同じリージョンに関数をデプロイします。これによって、Cloud Functions の関数とこのサービスの間で、帯域幅が広くレイテンシが低いネットワーク接続を確保できます(参照:「リージョンとゾーン」)。
Cloud Functions の関数は必ずユーザーの近くにデプロイしてください。アプリケーションのユーザーがカリフォルニアにいる場合は、us-east ではなく us-west にデプロイします。これだけでもレイテンシを 70 ミリ秒削減できます。
アプリケーションのデバッグと分析
この記事の次のセクションでは、デプロイしたアプリケーションを効果的にデバッグするための推奨事項をお伝えします。
1. アプリケーションにデバッグ ロギングを追加する:
Cloud Functions 環境では、テレメトリー用の @google-cloud/logging や @google-cloud/monitoring などのクライアント ライブラリを使用しないでください。これらのライブラリは書き込みをバックエンド API にバッファするため、アプリケーションの実行期間外に res.send() を呼び出した後、処理がバックグラウンドに残るおそれがあります。
Cloud Functions にはデフォルトでモニタリングとロギングの機能が備わっています。これらを利用するには、Metrics Explorer とログ エクスプローラを使用します。
構造化ロギングの場合は、JSON.stringify() を使用すれば、Cloud Logging が構造化ログとして解釈します。
entry のペイロードはこちらに記載されている構造に従っています。timingDelta に注目してください。「リクエストのライフサイクルを理解し、落とし穴を回避する」の説明のとおりになっています。この説明は、res.send() の後に未処理の Promise が残っているかどうかをデバッグする際の参考になります。
ロギングに関連して CPU およびネットワークのコストが発生するため、ロギング対象のエントリのサイズに注意してください。たとえば、いくつかの有効なフィールドのロギングで済む場合に大きな JSON ペイロードをロギングすることは避けます。ロギングのレベルを変更する場合は環境変数を使用することを検討してください。比較的簡潔なアクショナル ログがデフォルトとなっており、アプリケーションの一部で util.debuglog を使用して詳細ログを有効にできる変数を使用します。
Cloud Functions の使用に関する重要ポイント
Cloud Functions はさまざまな種類のアプリケーションに適しています。
Cloud Scheduler のタスク: エラー状態になっているリリースがないか、30 分ごとにチェックする Cloud Functions の関数があります。
Pub/Sub のユーザー: キューからの XML 単体テストの結果を解析し、不安定なテストについては GitHub でイシューをオープンする Cloud Functions の関数があります。
HTTP API: Google は Cloud Functions を使用して GitHub API からの Webhook を受け入れています。コールド スタートが原因でリクエストに数秒間余計な時間がかかることがあっても、Google では問題ありません。
現状では、Cloud Functions でコールド スタートを完全に排除することは不可能です。インスタンスが再起動することもありますし、大量のトラフィックによって新しいインスタンスが起動することもあります。このため、Cloud Functions は現時点で、コールド スタートによって追加されることがある数秒が負担となるアプリケーションには適していません。たとえば、Cloud Functions の関数からのレスポンスでユーザー向けの UI の更新をブロックすることはおすすめできません。
Cloud Functions がこうした時間的制約のあるアプリケーションにも対応できるよう、Google は以下のような機能を準備しているところです。
インスタンスの最小数を指定できるようにします。これによって、一般的なトラフィック パターンではコールド スタートを回避できるようになります(最小数のインスタンスのしきい値を上回るリクエストがあった場合のみ新しいインスタンスが割り振られます)。
内部で Cloud Functions が実行されるサンドボックス、gVisor のディスク オペレーションのパフォーマンスを向上させます。コールド スタートの一定の時間はディスクからメモリへのリソースの読み込みに費やされるため、この変更によってスピードが向上します。
npm の googleapis から個々の API をパブリッシュします。これにより、人気の高い Google API とやり取りする Cloud Functions の関数を作成できるようになります。googleapis の依存関係全体を取得する必要はありません。
今回は Cloud Functions での自動化フレームワークの開発についてご説明しましたが、お楽しみいただけたでしょうか。いくつかの制約を受け入れ、この記事でご紹介した手法に従えば、小さな Node.js アプリケーションをデプロイする際の優れた選択肢となるでしょう。
この記事に関するフィードバックやユースケースに応じた Cloud Functions の改善点に関するご意見がある場合は、ぜひ公開バグトラッカーからお知らせください。
1. High Performance Browser Networking
-デベロッパー プログラム エンジニア Benjamin Coe
-テクニカル ソリューション エンジニア Martin Skoviera


