Cloud Data Loss Prevention の自動化

Google Cloud Japan Team
※この投稿は米国時間 2021 年 10 月 19 日に、Google Cloud blog に投稿されたものの抄訳です。
データは最も価値のあるアセットの一つです。データを理解し、効果的に使用することで、ビジネスを強化できます。しかし、プライバシーやセキュリティ、コンプライアンス上のリスクの原因となることもあります。多くの Google Cloud のお客様にとって、Cloud Data Loss Prevention(DLP)のデータ検出機能、分類機能は、機密データがどこに存在するかを特定するのに役立っています。しかし、データの増加は手作業での検査能力を上回っています。また、データの無秩序な増加により、機密データが想定外の場所に出現するケースが増えています。データリスクを管理するためには、管理者の負担を増やすことなく、データの急速な増加に合わせて自動スケーリングできるソリューションが必要です。
そこで、Cloud DLP の自動化を実現しました。自動検出、自動検査、自動分類、自動データ プロファイリングが可能になります。現在、BigQuery のプレビュー版が提供されており、組織全体で Cloud DLP を有効にすることで、データリスクを可視化できます。テーブルや列ごとに豊富な分析情報を得ることで、結果に集中してデータリスクを管理できるため、最終的には安全にビジネスを加速できます。Automatic DLP は、Google Cloud の見えないセキュリティ ビジョンの一例であり、データを理解し保護する機能がプラットフォームに組み込まれています。
Automatic DLP のメリットは以下の通りです。
継続的なモニタリング: Cloud DLP は、組織内で新しいテーブルを作成すると、自動的にプロファイリングします。また、変更したテーブルを定期的に再プロファイリングします。
オーバーヘッドが少ない: 管理するジョブがありません。組織全体、またはフォルダやプロジェクトを選択して、Cloud Console で直接有効にできます。
データ所在地: Cloud DLP は、データを検査し、データが存在するのと同じ地理的リージョン(BigQuery で構成されている)にデータ プロファイルを生成します。
Google 主導: 業界をリードする Cloud DLPを利用して、テーブルや列を検査し、プロファイリングする方法を見つけ出します。お客様は成果に集中できます。
豊富な分析情報: テーブルと列のプロファイルにより、Cloud DLP の予測する infoType を含む、データのリスクと機密度についての詳細がわかります。
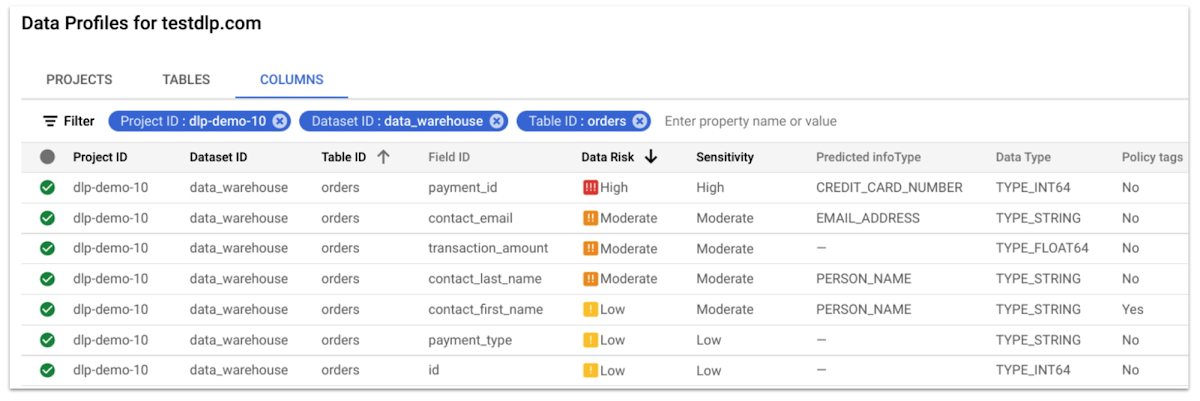
データ プロファイル
データ プロファイルとは、Cloud DLP がお客様のデータをスキャンして収集した一連の指標と分析情報です。これらの指標の中には、BigQuery テーブルで見つかった予測される infoType、「自由テキスト」スコア、一意性スコア、データリスク レベルが含まれます。これらの分析情報を使用し、データを保護、共有、使用する方法に関して情報に基づいた決定を行います。Cloud Console で直接結果を取得したり、プロファイルの詳細を BigQuery にエクスポートしてカスタム分析やレポートを作成したりできます。
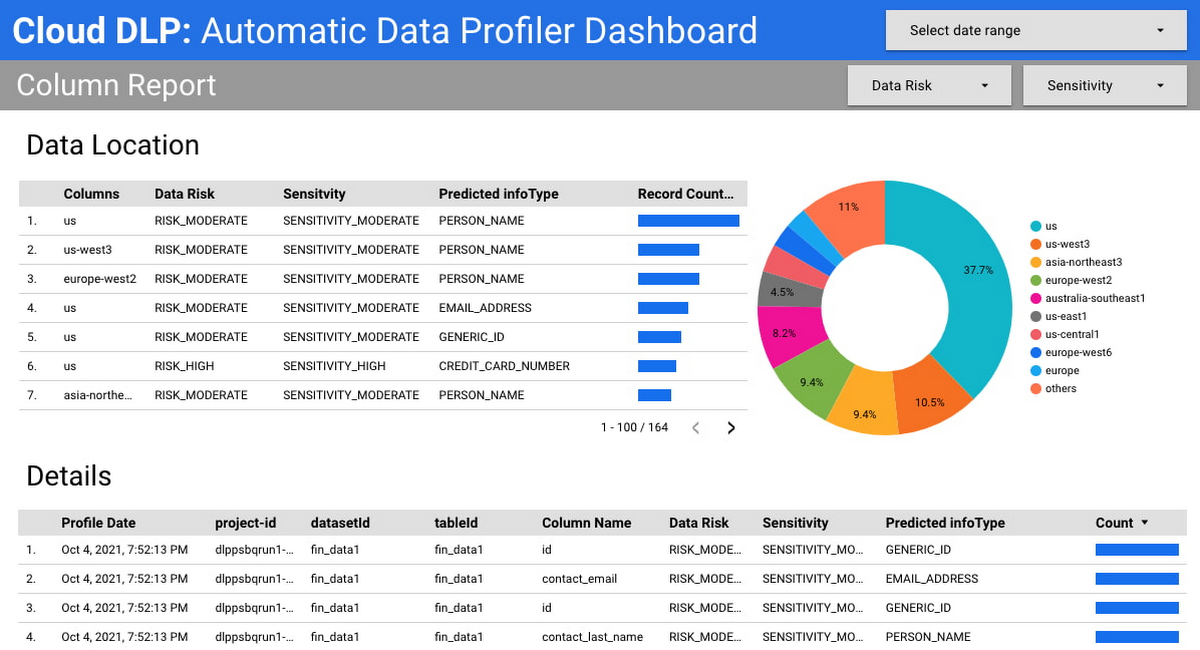
データリスクの管理
DLP プロファイルがデータリスクの理解と管理にどのように役立つか、いくつかのシナリオの例を紹介します。
シナリオ 1: クレジット カード番号と高い一意性スコアを持つテーブルが見つかった場合
たとえば、テーブルのある列に 1,000 万行あり、予測された infoType が「CREDIT_CARD_NUMBER」で、高い一意性スコアに分類されたとします。これは、このテーブルには 1,000 万件の一意のクレジット カード番号が含まれていることを示しています。一意性スコアが低いほど、テーブルの中で繰り返される数字の数が少ないことを示しています。
取るべき行動: このタイプのデータの保存や処理が許容される場合は、BigQuery ポリシータグを適用して、この列へのアクセスを特定の許可を得た人だけに制限することで、このデータのリスクを低減できます。また、この未加工情報を保存したくない場合は、Cloud DLP の匿名化メソッドや PCI トークン化のためのソリューションを使用してデータをトークン化することを検討します。
シナリオ 2: 複数の infoType と高い自由テキストスコアを持つテーブルが見つかった場合
たとえば、あるテーブルの列の予測される infoType は強くないものの、PHONE_NUMBER、US_SOCIAL_SECURITY_NUMBER、DATE_OF_BIRTH の兆候と高い「自由テキスト」スコアを持っているとします。これは、個人を特定できる情報(PII)が含まれている非構造化データの列がテーブルに存在する可能性を示しています。これはたとえば、「お客様は 1985 年 1 月 1 日生まれ」などの個人を特定できる情報(PII)を入力するメモ欄やコメント欄かもしれず、潜在的なリスクを示すものです。
取るべき行動: Cloud DLP の BigQuery 用オンデマンド検査を使用して、この列のディープ スキャンを実行し、特定の行やセルの個人を特定できる情報(PII)が存在する可能性のある箇所を把握することを検討します。または Cloud DLP のマスキング機能を使って、このテーブルを匿名化されたバージョンに置き換えることを検討します。
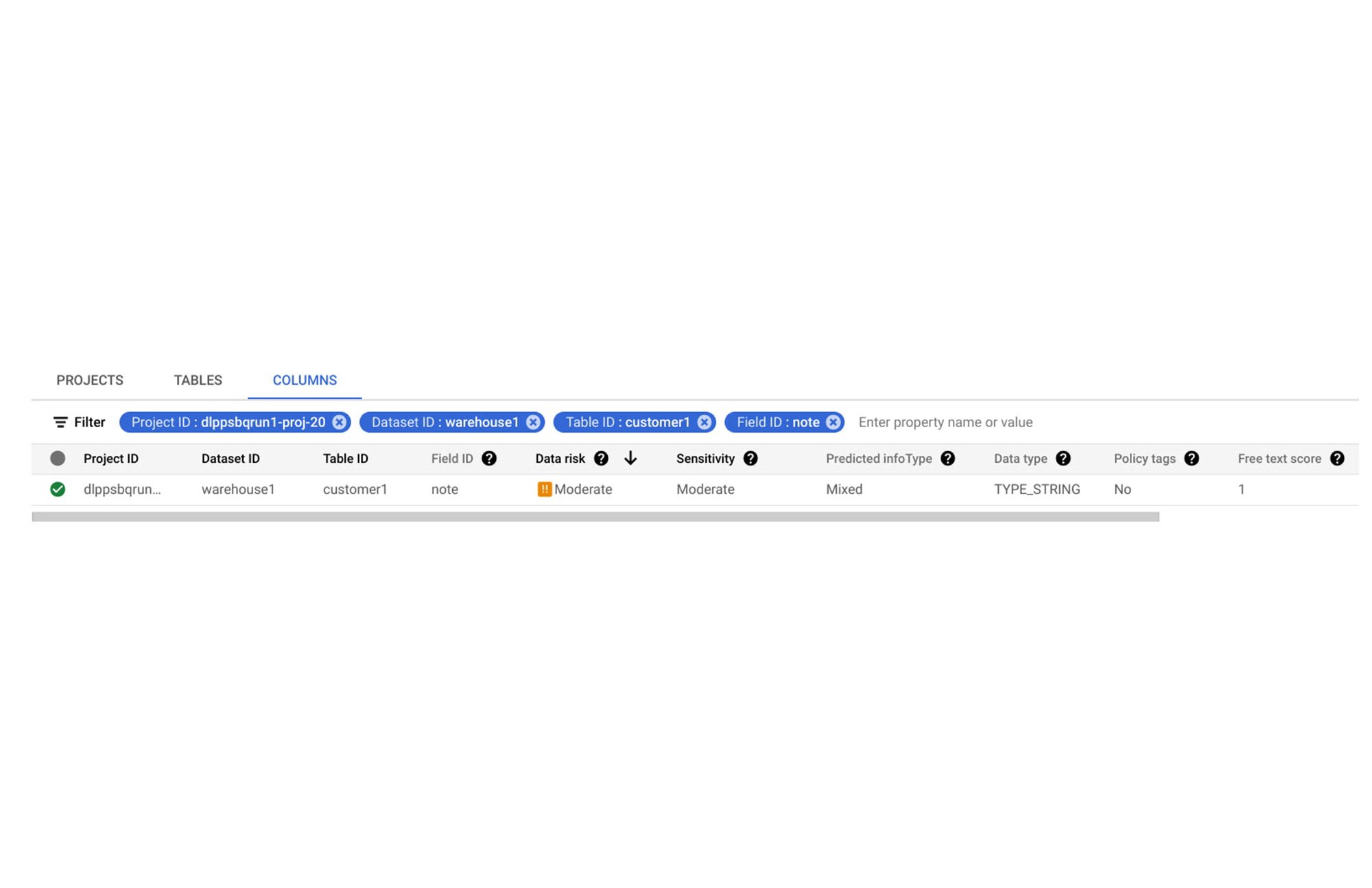
シナリオ 3: 機密データを含むテーブルが発見され、公開されていた場合
たとえば、あるテーブルにお客様の EMAIL_ADDRESS と PHONE_NUMBER が含まれており、それがマーケティング パートナーと共有されているとします。しかし、このテーブルは直接共有されるのではなく、公開されていました。そのため、機密情報が流出するリスクがかなり大きくなります。
取るべき行動: このテーブルへのアクセス許可を調整して、AllUsers や AllAuthenticatedUsers などの一般公開アクセス グループを削除します。代わりに、データへのアクセス権を持つべき特定のユーザーやグループを追加します。
Automatic DLP のスタートガイド
Automatic DLP Profiling は、現在 BigQuery のプレビュー版として提供されています。
はじめに、Cloud Console で Cloud DLP のページを開き、Google のドキュメントをご確認ください。
- Google Cloud プロダクト マネージャー Scott Ellis
- スタッフ ソフトウェア エンジニア Jordanna Chord


