Google Cloud
機械学習用チップの性能評価 : TPU の研究論文を公開
2017年4月14日
Google Cloud Japan Team
私たち Google は 15 年前から、プロセッサに負担をかける機械学習を自社製品で使用してきました。機械学習を多用するあまり、まったく新しいカスタム機械学習アクセラレータ、Tensor Processing Unit(TPU)の設計にまで踏み込みました。
では、TPU は実際、どれくらい高速なのでしょうか。
私たちは先ごろ、米国カリフォルニア州シリコンバレーのコンピュータ歴史博物館で開催された NAE(National Academy of Engineering)の会合で TPU に関する講演を行うとともに、2015 年以来 Google のデータセンターで機械学習アプリケーションを実行しているこれらのカスタム チップの新たな情報に関する研究論文を公開しました。
この第 1 世代の TPU は推論フェーズを対象としています(モデルの訓練フェーズではなく、あらかじめ訓練されているモデルを使うもので、特性が少し異なります)。得られた結果の一部を紹介しましょう。
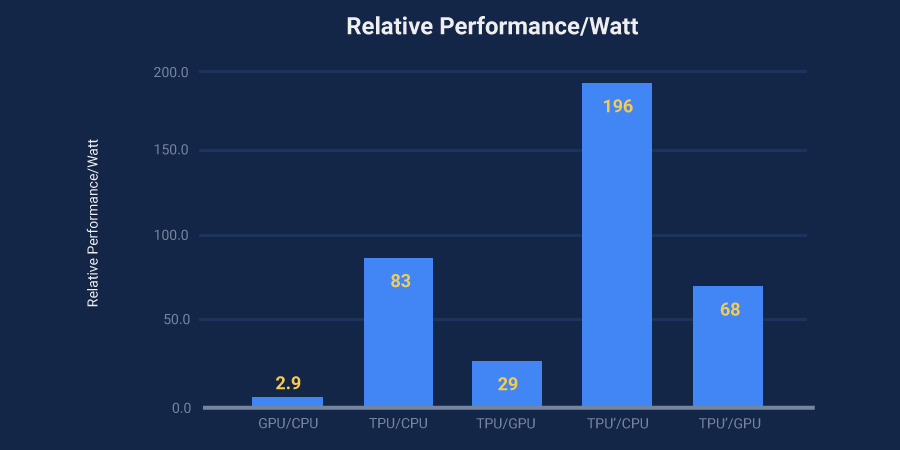
- ニューラル ネットワークの推論を使っている本番 AI ワークロードでは、TPU は現在の GPU や CPU よりも 15 倍から 30 倍高速です。
- TPU のエネルギー効率は従来のチップよりもはるかに高く、TOPS / ワット(エネルギー消費 1 ワットあたりのテラオペレーション、すなわち 1 兆オペレーションまたは 10 の 12 乗オペレーションの計測値)は 30 倍から 80 倍の改善を示しています。
- これらのアプリケーションを支えるニューラル ネットワークのコード量は驚くほど少なく、100 行から 1,500 行に過ぎません。このコードは、Google が開発した人気の高いオープンソースの機械学習フレームワークである TensorFlow をベースとしています。
- この論文は 70 人以上の著者によって執筆されています。実際、このようなシステムのハードウェアとソフトウェアの設計、検証、実装、デプロイを行うにはビレッジが 1 つ必要でした。
TPU が本当に必要になったのは、製品群全体のさまざまな個所で計算コストの高いディープ ラーニング モデルを使い始めた 6 年前からです。
これらのモデルを使ったときの計算コストの高さは、私たちが心配になるほどのものでした。人々が毎日ちょうど 3 分ずつ Google 音声検索を使用し、音声認識のために私たちが使っていた処理ユニットでディープ ニューラル ネットを実行したとすると、Google データセンターの数を倍にしなければならなかったほどです。
TPU のおかげで需要予測などは非常に高速になり、ほんの一瞬で応答を返すサービスを実現できるようになりました。
TPU はあらゆる検索クエリを背後で支えています。Google Image Search、Google Photos、Google Cloud Vision API などを支える正確な視覚モデルも TPU に支えられています。昨年リリースされた Google Translate の画期的な品質向上を支えているのも TPU です。また、Google DeepMind の AlphaGo が Lee Sedol 氏に勝ち、囲碁の世界チャンピオンを初めて破ったときも、TPU が重要な役割を果たしました。
私たちは、最良のインフラストラクチャを構築し、それによる利益をすべての人々と共有することに全力で取り組んでいます。数週間、数か月後に、新たなアップデートを発表するのを今から楽しみにしています。
これらのモデルを使ったときの計算コストの高さは、私たちが心配になるほどのものでした。人々が毎日ちょうど 3 分ずつ Google 音声検索を使用し、音声認識のために私たちが使っていた処理ユニットでディープ ニューラル ネットを実行したとすると、Google データセンターの数を倍にしなければならなかったほどです。
TPU のおかげで需要予測などは非常に高速になり、ほんの一瞬で応答を返すサービスを実現できるようになりました。
TPU はあらゆる検索クエリを背後で支えています。Google Image Search、Google Photos、Google Cloud Vision API などを支える正確な視覚モデルも TPU に支えられています。昨年リリースされた Google Translate の画期的な品質向上を支えているのも TPU です。また、Google DeepMind の AlphaGo が Lee Sedol 氏に勝ち、囲碁の世界チャンピオンを初めて破ったときも、TPU が重要な役割を果たしました。
私たちは、最良のインフラストラクチャを構築し、それによる利益をすべての人々と共有することに全力で取り組んでいます。数週間、数か月後に、新たなアップデートを発表するのを今から楽しみにしています。
* この投稿は米国時間 4 月 5 日、Google の Distinguished Hardware Engineer である Norm Jouppi によって投稿されたもの(投稿はこちら)の抄訳です。
- By Norm Jouppi, Distinguished Hardware Engineer, Google



