NTT ドコモ「AIタクシー」を支える TensorFlow と需要予測モデル
Google Cloud Japan Team
Google Cloud デベロッパーアドボケイト 佐藤一憲
Google Cloud マシンラーニング スペシャリスト 大薮勇輝
NTT ドコモ(以下、ドコモ)は今年 2 月、タクシー需要予測サービス 「AIタクシー」の運用を開始しました。このサービスでは携帯電話ネットワークから得られるリアルタイムの人口統計情報を利用し、TensorFlow で構築したディープラーニング モデルとの組み合わせにより、500 m 四方のエリアごとの 30 分後までの乗車数を 93〜95% の精度で予測します。
このサービスは現在、東京と名古屋で徐々にサービスを拡大し、2,500 台のタクシーに順次導入を進めています。その結果、1) 乗客の待ち時間の短縮、2) 急な需要変化へのすばやい対応、そして 3) ベテランドライバーと新人ドライバーの経験差の緩和が実現。タクシー事業者の売り上げの顕著な向上として、その効果がすでに現れています。


需要予測のメカニズム
AIタクシーでは、おもに以下のデータに基づいて需要予測を行っています。- ドコモの携帯電話ネットワークから得られる人口統計情報
- タクシーから集まる位置情報と乗車数
- 気象情報
ドコモでは、携帯電話ネットワークから得られる情報を元に、日本全国の人口統計を収集しています(携帯電話の利用者個人を特定できる情報は除かれます)。ドコモは、この正確な人口統計情報によって、精度の高いタクシー需要予測が実現したと説明しています。


これらの元データには前処理が施され、およそ 120 次元の入力ベクトルが生成されます。これを以下の 2 つの機械学習モデルの入力データとして利用します。
- ディープラーニング モデル
- 統計モデル(特定のエリア向け)
このサービスの研究段階で、大半のエリアについてディープラーニングモデルがよい精度を出せ、一方である特定のエリアでは統計モデル(多変量自己回帰)がより高精度を出せることがわかりました。この結果に基づき、この 2 つのモデルを組み合わせることで、すべてのエリアでもっともよい精度を得ています。
これらの機械学習モデルからは、500 m 四方の各エリアについて、今後 30 分間の予測乗車数が計算されます。東京のサービス対象地域はおよそ 3,000 のエリアに分割され、それぞれについて需要を表す数値が地図上に表示されます。
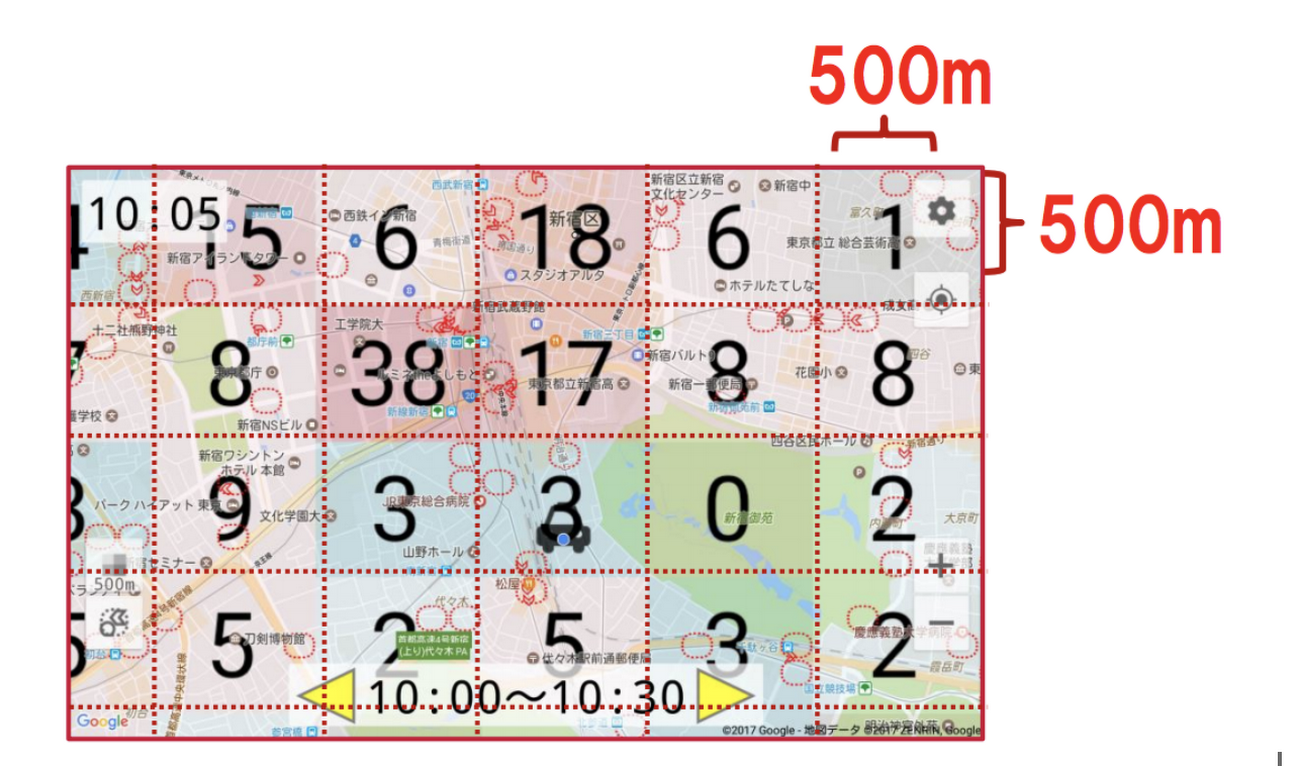

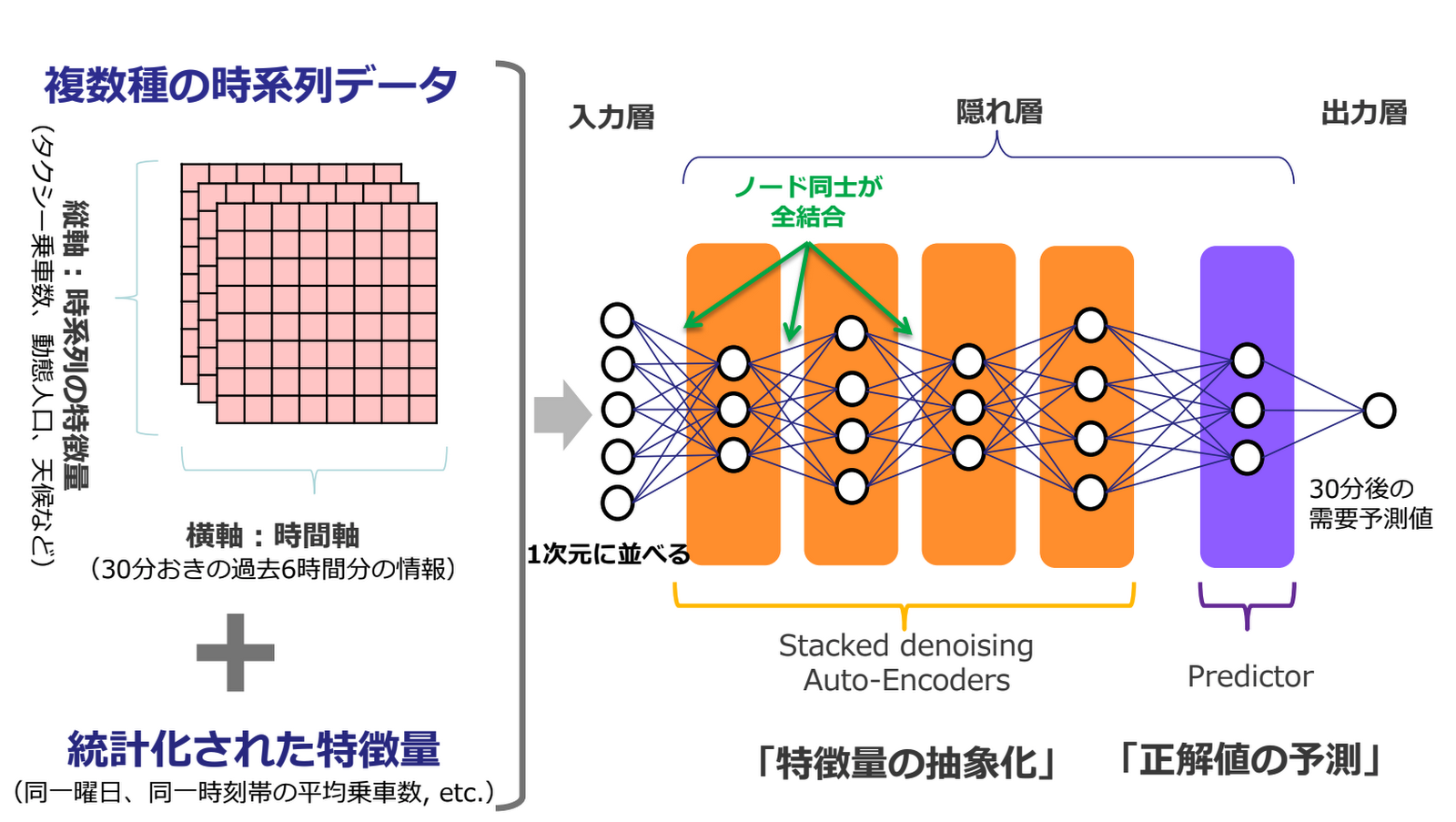
ディープラーニングによる時系列解析
このシステムが用いるディープラーニング モデルについてもう少し詳しく見てみましょう。およそ 120 次元の入力ベクトルには、人口統計、タクシー運行データ、および気象データなどの時系列データが含まれています。また、時間帯や曜日ごとの平均乗車数といった合成特徴量も、時系列データとして組み合わされています。こうした時系列データの解析には、RNN(recurrent neural network)や LSTM(long short-term memory)が広く利用されています。一方で本システムでは、さまざまな試行錯誤の結果、オートエンコーダー(stacked denoising auto-encoder)が選ばれました。
この選択についてドコモのデータサイエンティスト石黒慎氏は次のように説明します。「タクシーの需要予測では、入力ベクトルからいかにしてノイズを取り除くかが大きな課題でした。オートエンコーダーを試したところ、ノイズの中から重要なシグナルを効率的に拾い上げられることが分かりました」

AIタクシーを利用しているタクシー事業者からは、顕著な売り上げ向上の報告がすでに届いています。実際の利用者からの声について、ドコモの開発チームを率いる川崎仁嗣氏は次のように説明します。「多くの場合、タクシー運転手はいつも通り大通りを流していることが多いのですが、AIタクシーの導入により、イベントやその他の理由による急な需要変化にも対応できるようになりました。また、不慣れな場所で乗客を見つけるにも役立ちます。ベテランドライバーと新人ドライバーの差を減らす手段としても重宝いただいています」
Google Cloud で次のステップへ
また石黒氏は次のように説明します。「今回の開発でもうひとつの課題は、ハイパーパラメータチューニング(ディープラーニング モデルの設計最適化)でした。現状では、ランダムサーチによるハイパーパラメータチューニングを行っており、探索を 1,000 回実施し、最終解として得られた最も精度の高いモデルを選んでいます。オンプレミスでの計算機環境では 1 モデルあたりの学習に 20 分間を要することから、この作業に多大な時間や計算リソースを消費しています」そこでドコモでは、この課題の解決にむけて Google の機械学習プラットフォーム Cloud ML Engine の本格調査を開始しました。「Cloud ML Engine では、データサイエンティストやインフラエンジニアの手を煩わせずに、大規模な分散学習環境が簡単に使えます。また、ランダムサーチよりも効率的なハイパーパラメータチューニングを提供する HyperTune も備えており、ぜひ試してみたいです。これらの特徴を活かせば、サービスの開発、展開、そして運用までのプロセスで、データサイエンティストの開発生産性がぐんと高まるはずです」
東京を走るタクシーの効率的な配車を支える TensorFlow、そして近い将来には Cloud ML Engine ももう一つの強力な支えとなりそうです。
*この投稿は米国時間 4 月 25 日、Cloud Developer Advocate 佐藤一憲および ML Specialist 大藪勇輝 によって投稿されたもの(投稿はこちら)の抄訳です。



