Google Cloud で実行されている DevOps 組織の有効性を評価する
Google Cloud Japan Team
※この投稿は米国時間 2020 年 10 月 3 日に、Google Cloud blog に投稿されたものの抄訳です。
編集者注: DevOps の有効性を評価する方法は多数あります。Google Cloud デベロッパー プログラム エンジニアである Dina Graves Portman が最近、Four Keys オープンソース プロジェクトを使用して DevOps の有効性を評価する方法に関する記事を投稿しました。ここでは、Google カスタマー エンジニアである Brian Kaufman が、完全に Google Cloud 上で実行されているアプリケーションでも同じように有効性を測定する方法について説明します。
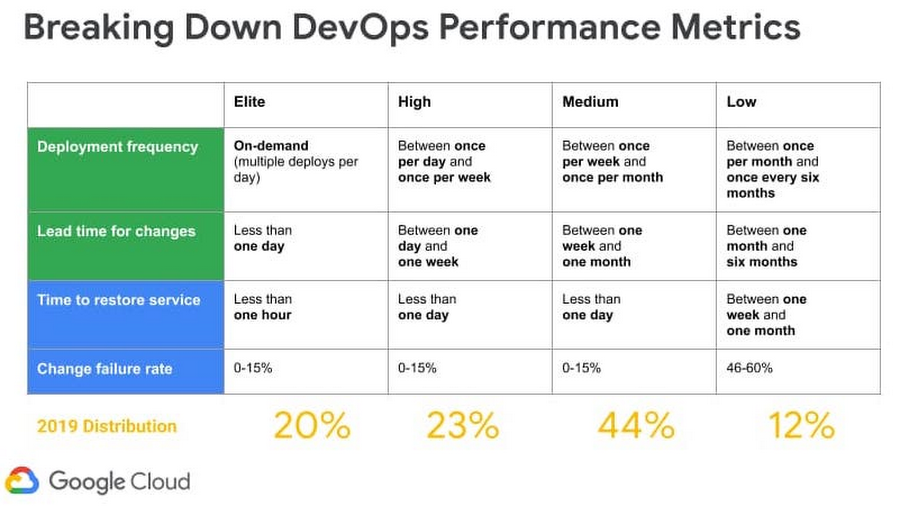
多くの組織が真に高度な DevOps ショップになることを目指していますが、自身の現在の立ち位置を把握するのは時として難しい場合があります。DevOps Research and Assessment(DORA)に従って、DevOps 組織の有効性を測定する 4 つの指標を優先的に使用するだけでこれが可能になります。この 4 つの指標とは、次に示す速度を測定する 2 つの指標と、安定性を測定する 2 つの指標です。
速度
1. 変更のリードタイム - コードの commit から本番稼働まで
2. デプロイの頻度 - コードを push する頻度
安定性
3. 変更障害率 - 本番環境での即時の対応を必要とするデプロイの失敗の割合(ロールバックまたは手動による変更)
4. サービス復元時間(MTTR) - 回復にかかる平均時間
この投稿では、Google Cloud にデプロイされたソフトウェア デリバリー パイプラインとアプリケーションから、4 つの指標を収集する手法をご紹介します。これらの指標を使用してプラクティス全体の有効性を評価し、組織のパフォーマンスを DORA の業界ベンチマークと照らし合わせれば、組織のパフォーマンスがエリート、高、中、低のいずれに属するかを判断できます。
Google Cloud で実行されているサンプル アーキテクチャを使用して、これを実際に行う方法を見てみましょう。
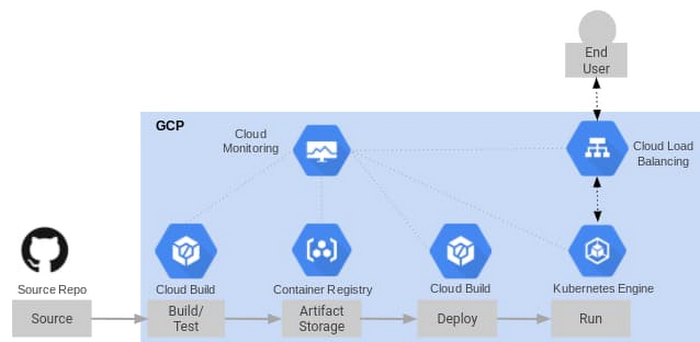
サービスとリファレンス アーキテクチャ
まず、次のクラウド サービスを使用して CI / CD パイプラインを作成します。
Cloud Build(コンテナベースの CI / CD ツール)
Cloud Load Balancing(GKE に対する Ingress コントローラとして使用)
Cloud の稼働時間チェック機能(統合アプリケーション モニタリング用)
Pub/Sub(アラートを Cloud Functions に接続するメッセージバスとして使用)
これらをまとめたものが以下のリファレンス アーキテクチャです。お気づきのように、これらの Google Cloud サービスはすべて、Cloud Monitoring と統合されています。そのため、サービスログを受信するための設定を行う必要はありません。これらのサービスの多くには組み込みの指標があり、この投稿ではそれを使用します。
速度の測定
2 つの速度指標、つまりデプロイの頻度と commit のリードタイムを測定するには、Cloud Build を使用します。これは継続的インテグレーションと継続的デリバリーのツールです。コンテナベースの CI / CD ツールである Cloud Build を使用して、Google で管理されるまたはコミュニティで管理される一連のクラウド ビルダーを読み込んで、ビルドやデプロイのプロセス中にコードの操作や内部および外部サービスとのやり取りを行うことができます。ビルドトリガーが起動されると、Cloud Build はソースコードの Git リポジトリにアクセスし、Container Registry に push するコンテナ イメージのアーティファクトを作成して、コンテナ イメージを GKE クラスタにデプロイします。
そのプロセスで独自のクラウド ビルダー コンテナをインポートして最終ビルドステップとして挿入し、commit からデプロイまでの時間を計算したり、これがロールバック デプロイであるかどうかを判断したりすることも可能です。今回の例では、最終ビルドステップとして使用する次のようなカスタム コンテナを作成しました。
1.commit タイムスタンプのペイロード バインディングを取得します。タイムスタンプに変数 $(push.repository.pushed_at) 経由でアクセスし、現在のタイムスタンプと比較することによってリードタイムを計算します。ペイロード バインディング変数はトリガーを作成するときに使用し、cloudbould.yaml のカスタム変数 $_MERGE_TIME によって参照されます。
2.ソース リポジトリにアクセスして、マスター ブランチの最新の commit の commit ID を取得します。これをビルドの現在の commit ID と比較して、それがロールバックか、一致しているかを判断します。
上記の各ビルドステップを示す参照用 Cloud Build 構成 YAML ファイルはこちらでご覧いただけます。構成ファイルで「$_MERGE_TIME」ペイロード バインディングのような非組み込み変数を使用している場合は、クラウド ビルドトリガーを $(push.repository.pushed_at) 値に設定するときに、変数マップを指定する必要があります。

使用されるカスタムのクラウド ビルダー コンテナはこちらでご覧いただけます。このコンテナのビルドステップが実行されると、以下が Cloud Build ログに出力され、このログがCloud Monitoring に自動的に送られます。commit ID、ロールバック値、LeadTime 値がカスタムのクラウド ビルダーからログに書き込まれることに注目してください。

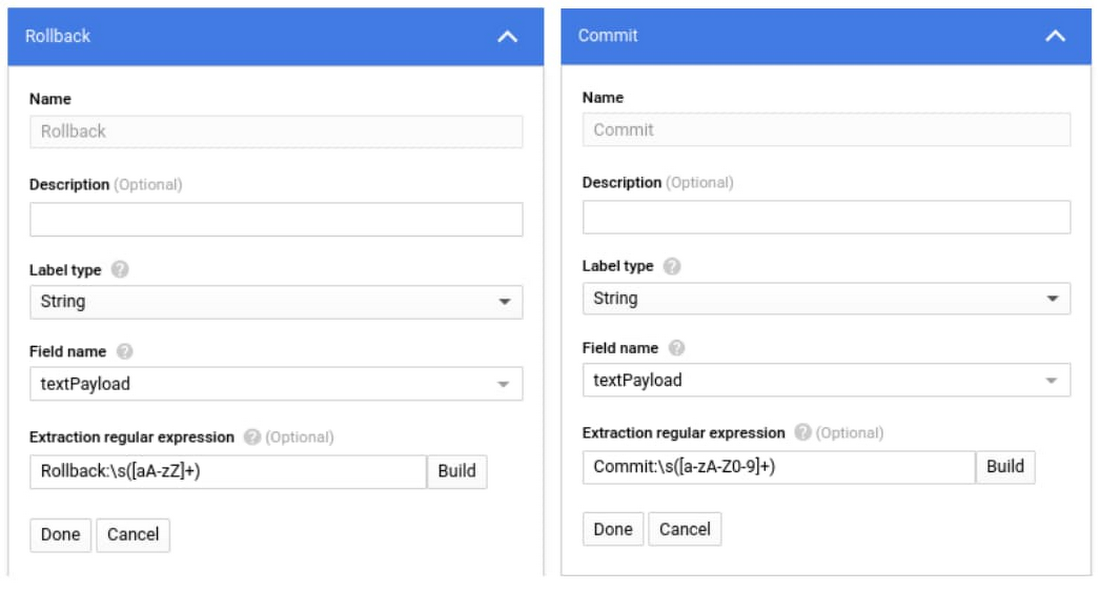
次に、Cloud Logging にログベースの指標を作成して、カスタム値を取り込みます。ログベースの指標は、特定のログエントリのフィルタに基づいて作成できます。

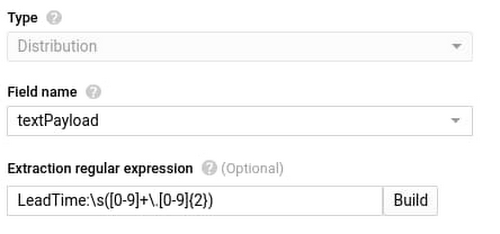
特定のログエントリのフィルタが設定できたら、出力ログの特定の部分に割り当てられた正規表現を使用して、ログエントリの特定のセクションを指標にキャプチャすることができます。以下のスクリーンショットでは、ログの「textPayload」フィールドに出力される LeadTime 値に関連付ける commit 名とロールバック値のラベルを作成しています。次の正規表現を使用しています。
指標値:
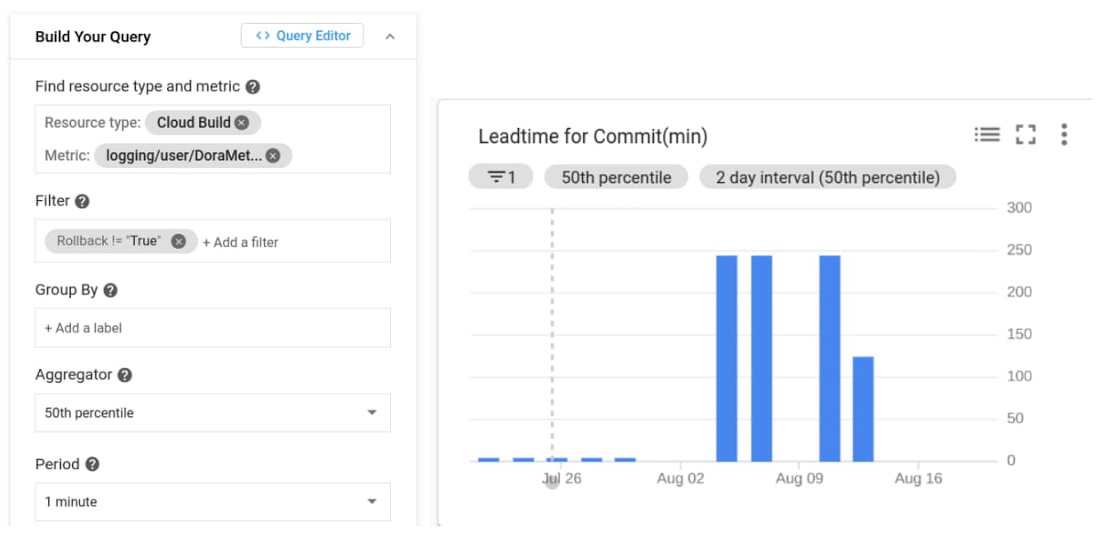
変更のリードタイム
Cloud Build ログから上記の指標とラベルを作成すると、Cloud Operations の Metrics Explorer で指標ラベル「logging/user/dorametrics」(「DoraMetrics」はログベースの指標に付けた名前)を介して指標にアクセスできるようになります。指標の値は、上記の正規表現から抽出されて、ロールバックが除外された LeadTime になります。中央値、つまり 50 パーセンタイルを使用します。
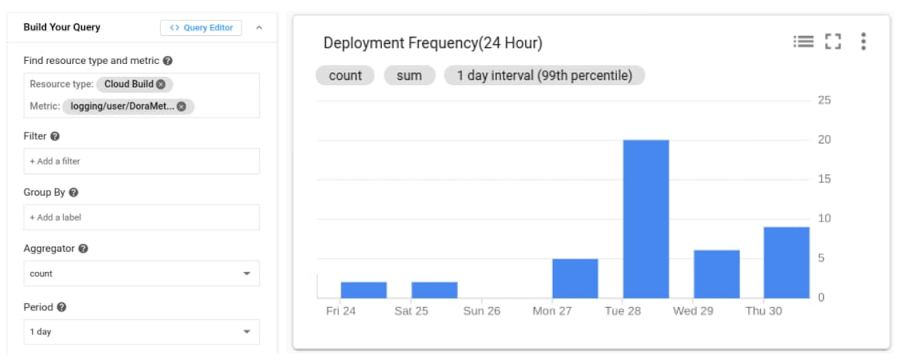
デプロイの頻度
これで各 commit のリードタイムが得られたので、時間枠内に記録されたリードタイムの数を数えるだけで、デプロイの頻度を特定できます。
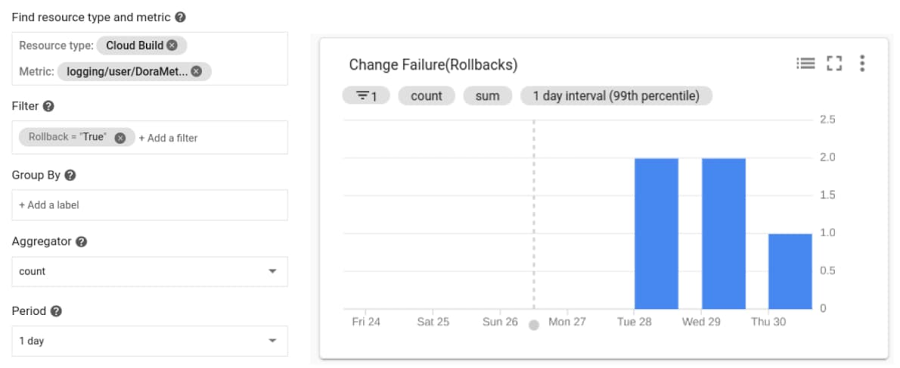
安定性の測定
変更障害率
実行されたソフトウェア ロールバックの数を特定するには、デプロイの頻度を調べて、フィルタで「Rollback=True」の指標を取得します。これにより、実行されたロールバックの総数がわかります。変更障害率を特定するには、このグラフで収集されたデータを、上記で収集した同じ時間枠内のデプロイ頻度の指標で除算します。
平均修復時間(MTTR)
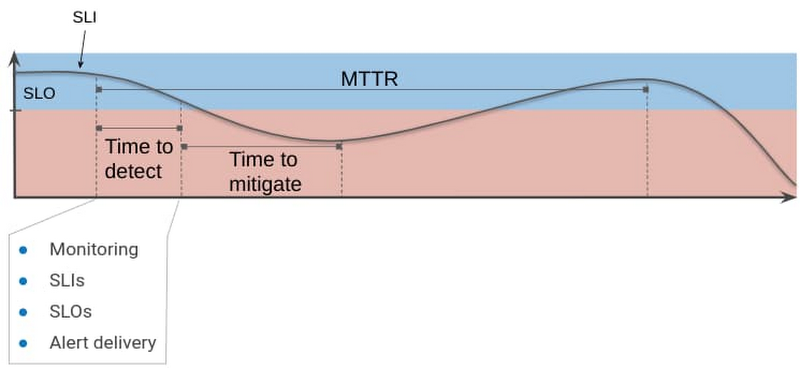
一般的なエンタープライズ環境にはインシデント対応システムがあり、これによって問題が報告された時間と最終的に解決された時間を特定できます。これらの時間をクエリできると仮定すると、問題が報告されたタイムスタンプと解決されたタイムスタンプの間の平均時間から MTTR を割り出すことができます。
このブログでは、自動化を使用して問題をアラートおよびグラフ化することで、より正確なサービス障害指標を収集できるようにします。サービスレベル目標(SLO)を活用することは、Google の戦略の一つです。この尺度となるのがサービスレベル指標(SLI)で、アプリケーションや目標に対するお客様の満足度を示すことが判明しています。SLO に違反した状況が発生した場合、サービスの平均修復時間は、問題を検出、軽減、解決し、再び SLO に合致する状態に達するまでにかかる合計時間と見なされます。
MTTR と顧客満足度
わかりやすくするために、顧客満足度を表すと思われる 1 つの指標、つまり Google のウェブサイトから返された、エラーを表す HTTP レスポンス コードの総数に着目しています。特定の時間枠内に送信されたレスポンス コードの総数に対するこの指標の比率をサービスレベル指標(SLI)とします。
エラー総数については、フロントエンド ロードバランサから返されるレスポンス コードをモニタリングします。フロントエンド ロードバランサは GKE クラスタに Ingress コントローラとして設定されています。
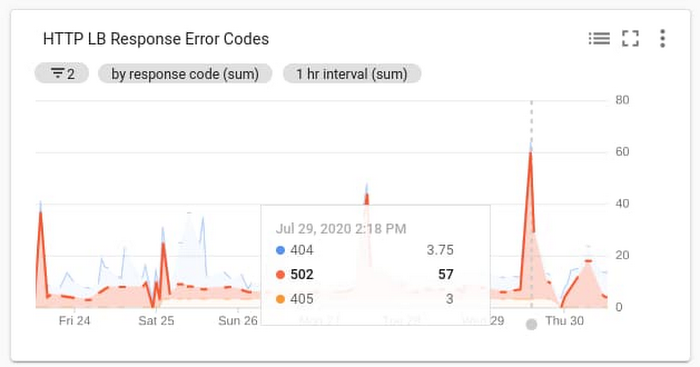
使用する指標: loadbalancing.googleapis.com/https/request_count を response_code でグループ化
上記の指標を使用して SLI を設定し、それから SLO を作成して、より長い時間枠における顧客満足度を表すことができます。SLO API を使用して、モニタリングする顧客満足度のレベルを表すカスタム SLO を作成します。この SLO に違反している場合、問題があることを示しています。カスタム SLO とサービスの作成方法に関する素晴らしいチュートリアルがこちらにありますのでご参照ください。
この例では、アプリケーションを表すカスタム サービスと、HTTP LB レスポンス コード(コード)の SLO を作成しました。これは、サービス品質レベルとして、特定の日にロードバランサからのレスポンスの 98% がエラーではないことを想定しています。これを行うと、24 時間で 2% のエラー バジェットが自動的に作成されます。ここで、MTTR のモニタリングについては、サービスレベル SLO に関連付けられた、特定の時間枠でのサービス品質を表す指標(SLI)があります。以下のスクリーンショットでは、SLO の失敗をシミュレートしています。
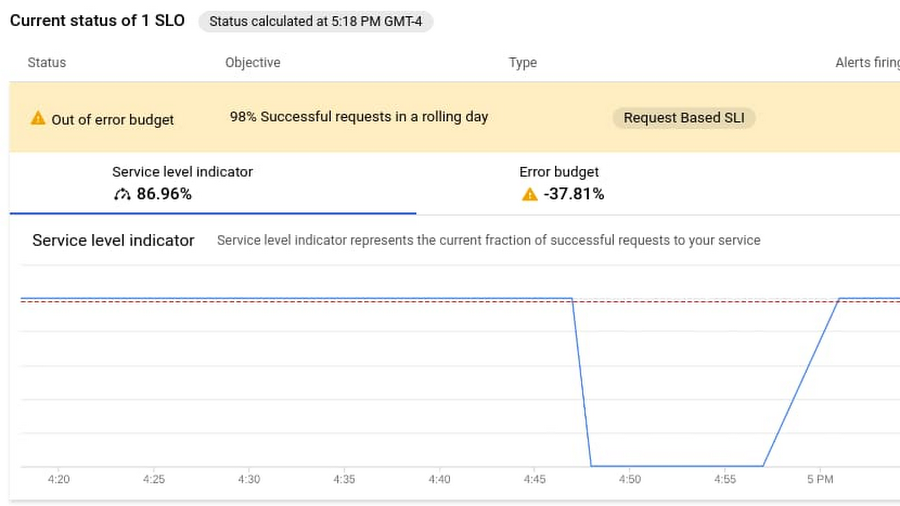
次に、この SLO に違反する危険性がある場合に発動するアラート ポリシーを設定します。この設定により、解決までにかかった時間を計算するタイマーも開始されます。ここで測定しているのは「バーンレート」と呼ばれるもので、現在の SLI 指標で消費しているエラー バジェット(24 時間で 2% のエラー)の量です。アラートを測定する時間枠は SLO 全体よりもはるかに小さいため、SLI がしきい値内に戻ると別のアラートが発動し、インシデントがクリアされたことが示されます。アラート ポリシーの設定の詳細については、こちらのページをご覧ください。
また、さまざまなチャネルを介してアラートを送信でき、既存のチケット発行システムやメッセージング システムに統合して、組織にとって適した方法で MTTR を記録できます。ここでは、Pub/Sub メッセージバス チャネルと統合し、必要なグラフ計算を行う Cloud Functions の関数にアラートを送信します。
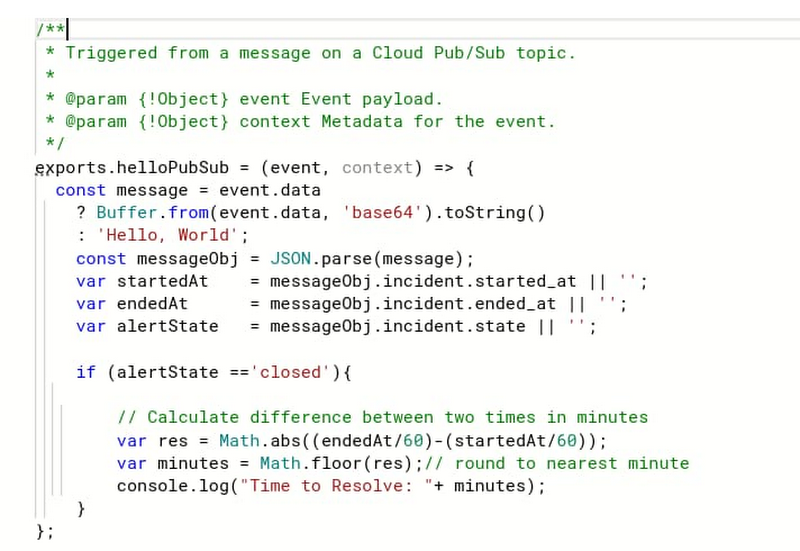
クリアされるアラートからのメッセージで、JSON ペイロードに started_at と ended_at タイムスタンプがあることがわかります。Cloud Functions の関数でこれらのタイムスタンプを使用して問題の解決にかかる時間を計算し、それをログに出力します。
Cloud Functions に送信される Pub/Sub メッセージの全体は次のとおりです。

アラートと同じ Pub/Sub トピックに接続されている Cloud Functions の関数は次のとおりです。
結果は、次のメッセージで Cloud Functions のログに送信されます。
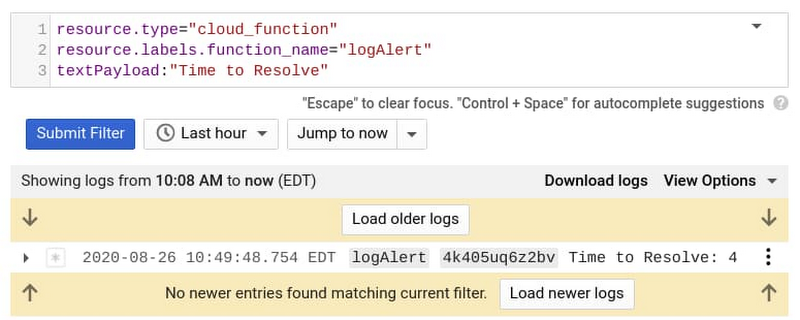
最後のステップとして、別のログベースの指標を作成して、Cloud Functions ログに出力する「解決までの時間」値を取得します。これには次の正規表現を使用します。
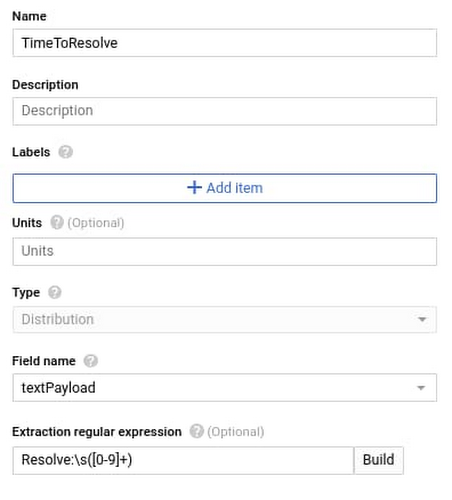
これで、Cloud Operations で指標を利用できるようになりました。
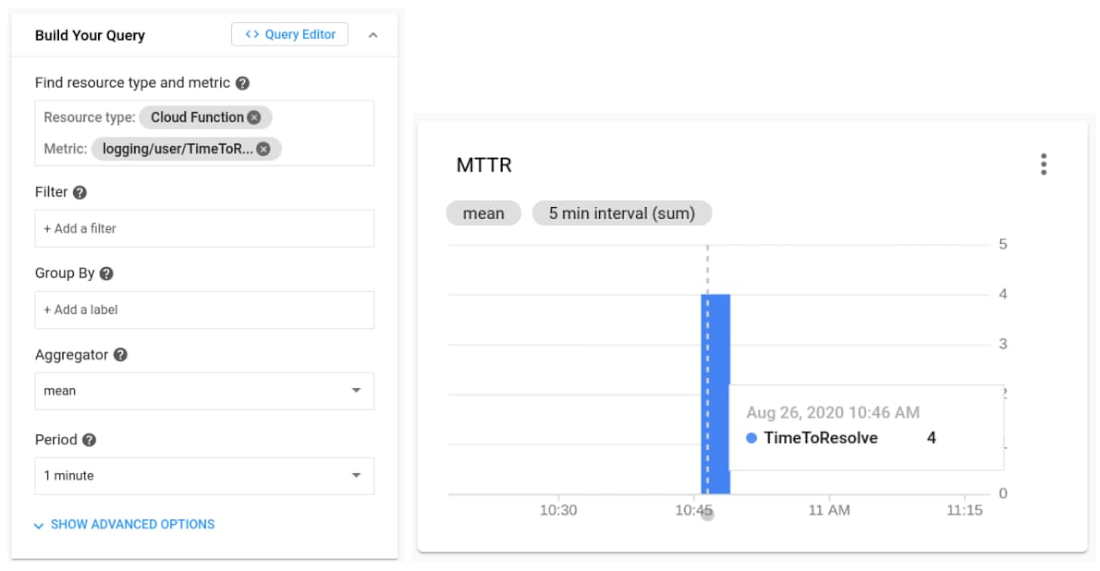
まとめ
この投稿では、Cloud Build でカスタム クラウド ビルダーを作成して、Cloud Operations のログに表示するデプロイの頻度、平均デプロイ時間、ロールバックに関連する指標を生成する方法について説明しました。また、SLO と SLI を使用してアラートを生成し、Cloud Functions ログに push する方法も示しました。ログベースの指標を使用して、ログから指標を引き出し、グラフ化しました。これらの指標は、組織のソフトウェア開発およびデリバリー パイプラインの有効性の経時的な評価や、より大きな DevOps コミュニティでのパフォーマンスの評価に使用できます。ご自身の組織でご活用ください。
以下に、お客様の DevOps 組織の有効性を測定するために役立つ参考資料をいくつかご紹介します。
SLO の設定: 手順ガイド(ブログ)
サービスのモニタリングにおけるコンセプト(ドキュメント)
SLO API の操作(ドキュメント)
-ハイブリッド スペシャリスト カスタマー エンジニア Brian Kaufman




{kind=link}