Spanner Graph アルゴリズムの発表: 接続されたデータに Google グレードのインテリジェンスを提供
Bei Li
Sr. Staff Software Engineer, Google Cloud
Vahab Mirrokni
VP, Google Fellow, Graph Mining, Google Research
※この投稿は米国時間 2026 年 6 月 3 日に、Google Cloud blog に投稿されたものの抄訳です。
Google Cloud Next では、Spanner Graph によるグラフ アルゴリズムのプレビュー版を発表しました。Google Research の最先端のグラフ マイニング機能をデータベースにネイティブに組み込めるようになり、グラフ インテリジェンス機能を活用することで、グラフデータから、より迅速で低コストかつ大規模に、貴重な分析情報を導き出すことができます。
不正行為の検出、ソーシャル ネットワーク分析、エンティティ解決、医療研究などのユースケースにおいて、データの複雑な関係を明らかにするために、多くの企業がグラフ技術を活用するようになっています。ノード中心性やコミュニティ検出などのグラフ アルゴリズムは、こうした構造を分析するために使用される計算手法であり、エンティティ間の接続のパターンや強度を定量化することで機能します。しかし、これまで、グラフ アルゴリズムを大規模に実行することは、困難かつリソースを大量に消費するものであり、多くの場合、専用の分析ソリューションに複雑な ETL パイプラインが必要になったり、グラフ データベースのトランザクション パフォーマンスが低下したりするリスクがありました。
Spanner Graph アルゴリズムは、オペレーショナル データベースのパフォーマンスを損なうことなく、要求の厳しいエンタープライズ ワークロードに対応できるように設計されています。このアーキテクチャには、以下のような明確な利点があります。
-
GQL との緊密な統合: ISO Graph Query Language(GQL)を使用してアルゴリズムを直接呼び出し、データ全体で構造分析を実行します。Spanner Graph は、アルゴリズムと標準クエリを順次組み合わせることで、外部エンジンへの複雑なデータ移動を最小限に抑え、アーキテクチャを簡素化し、分析情報取得までの時間を短縮します。
-
トランザクションにほとんど影響を及ぼさずに TCO を削減: アルゴリズムの実行は専用のコンピューティング リソースで行われるため、本番環境のライブ トラフィックに影響を与えることはありません。Spanner はリソースを自動的にプロビジョニングし、Data Boost を介してデータを安全にルーティングするため、カスタム ETL パイプラインを作成する必要はありません。料金は使用した分に対してのみ発生するため、従来のソリューションに見られる運用上のオーバーヘッドや高額なライセンス費用を回避できます。
-
数十億エッジに及ぶグラフのグローバルな分析情報を数分で取得: スケールとスピードを重視して構築されたエンジンにより、数十億エッジに及ぶグラフに対して数分でアルゴリズムを実行できます。ランダムアクセスに最適化された高密度形式でトポロジをエンコードすることで、大規模なデータセットに対する高性能な構造分析を実現します。
Google Research は、これまでに、グラフ マイニング ツール(マルチコア クラスタリングなど)に基づく研究論文をいくつか発表しており、ワークショップの開催や、オープンソース プロジェクトのリリースなども行っていますが、こうした機能を Google Cloud のお客様に広く提供するのは今回が初めてです。以下に、グラフ アルゴリズムの仕組みと、Spanner Graph での使用方法について詳しく見ていきましょう。
アルゴリズム: 接続されたデータからより深い分析情報を取得
Spanner Graph を初めてリリースしたときの私たちの目標は、Google のスケーラビリティに優れた分散データベースである Spanner 内で、ネイティブなグラフ データベース エクスペリエンスを通じてグラフデータ管理を再構築することでした。Spanner Graph はリレーショナル モデルとグラフモデルを統合し、ISO GQL を使用して接続されたデータをクエリできるようにするとともに、Spanner の既存の表形式、検索、ベクトル機能と相互運用できるようにします。これにより、複雑なデータ パイプラインの作成、データの複製といった作業や、セキュリティやガバナンスのリスクの増大を伴うことなく、インテリジェントなアプリケーションを構築できます。
この基盤の上に構築された Spanner Graph アルゴリズムは、接続されたデータからさらに深い分析情報を抽出するのに役立ちます。グラフ アルゴリズムは、データ内の関係やつながりを分析し、従来の分析手法では見逃されがちな隠れたパターンや分析情報を明らかにします。今回のリリースにより、接続性を分析することが可能になり、詐欺組織の検出、エンティティ解決のためのクラスタリング、複雑なネットワークにおける障害点の特定、接続されたユーザーの好みに基づく商品の推奨などを実施できるようになります。
Google ではグラフを幅広く使用しています。実際、Google 検索を支える基盤技術である PageRank など、多くの人気アルゴリズムが Google で開発されています。Spanner Graph のネイティブ アルゴリズム サポートは、Google の最先端のグラフ インテリジェンス機能の一部を Google Cloud のお客様に直接提供するものであり、これにより、データ内の隠れた構造を簡単に発見できる必須グラフ アルゴリズムのセットを利用できるようになります。
-
中心性: 中間中心性、近接中心性、PageRank を使用して、ネットワーク内で最も影響力のある中心的なノードを特定します。
-
コミュニティ検出: ラベル伝播、相関クラスタリング、モジュール性クラスタリング、弱連結成分、クリーク集約を活用し、接続性の高いエンティティを自動的にグループ化して、隠れたセグメントを明らかにします。
-
類似性と経路探索: セット間の最短経路を使用して最適なルートを見つけたり、ジャカード、コサイン、共通近傍、全近傍を使用してノードの類似性を測定したりできます。
デベロッパー エクスペリエンスの統合
グラフ全体やサブグラフ、選択したノードとエッジのセットに対して、GQL を使用してグラフ アルゴリズムを直接呼び出すことができます。Spanner は統合されたワークフローを提供し、グラフ アルゴリズムの実行結果を Spanner Graph に直接書き戻すことができます。これにより、あるオペレーションの出力を次のオペレーションの入力として使用して、アルゴリズムと標準クエリを順番に呼び出せるほか、この結果を Cloud Storage バケットに保存することもできます。
例: 詐欺組織の首謀者を特定する
マネー ロンダリング対策のために金融取引を分析するシナリオを考えてみましょう。不正行為者は通常、互いにやり取りする一連の「運び屋」アカウント(マネー ロンダリングの中継アカウント)を操作して、集団で不正行為を行います。不正行為対策の専門家は、通常、検出した運び屋アカウントと隠れた運び屋アカウントの間の連携を把握するために、リンク分析やコミュニティ検出といったグラフ アルゴリズムを利用します。以下に、Spanner Graph でアルゴリズムとクエリを組み合わせて、不正行為を特定する方法を示します。
ステップ 1: アカウントのコミュニティを特定する(アルゴリズム)まず、モジュール性クラスタリング アルゴリズムを適用して、アカウントをコミュニティにクラスタリングします。次に、この結果で得られた community_id を Spanner Graph 内の Account に直接書き戻します。
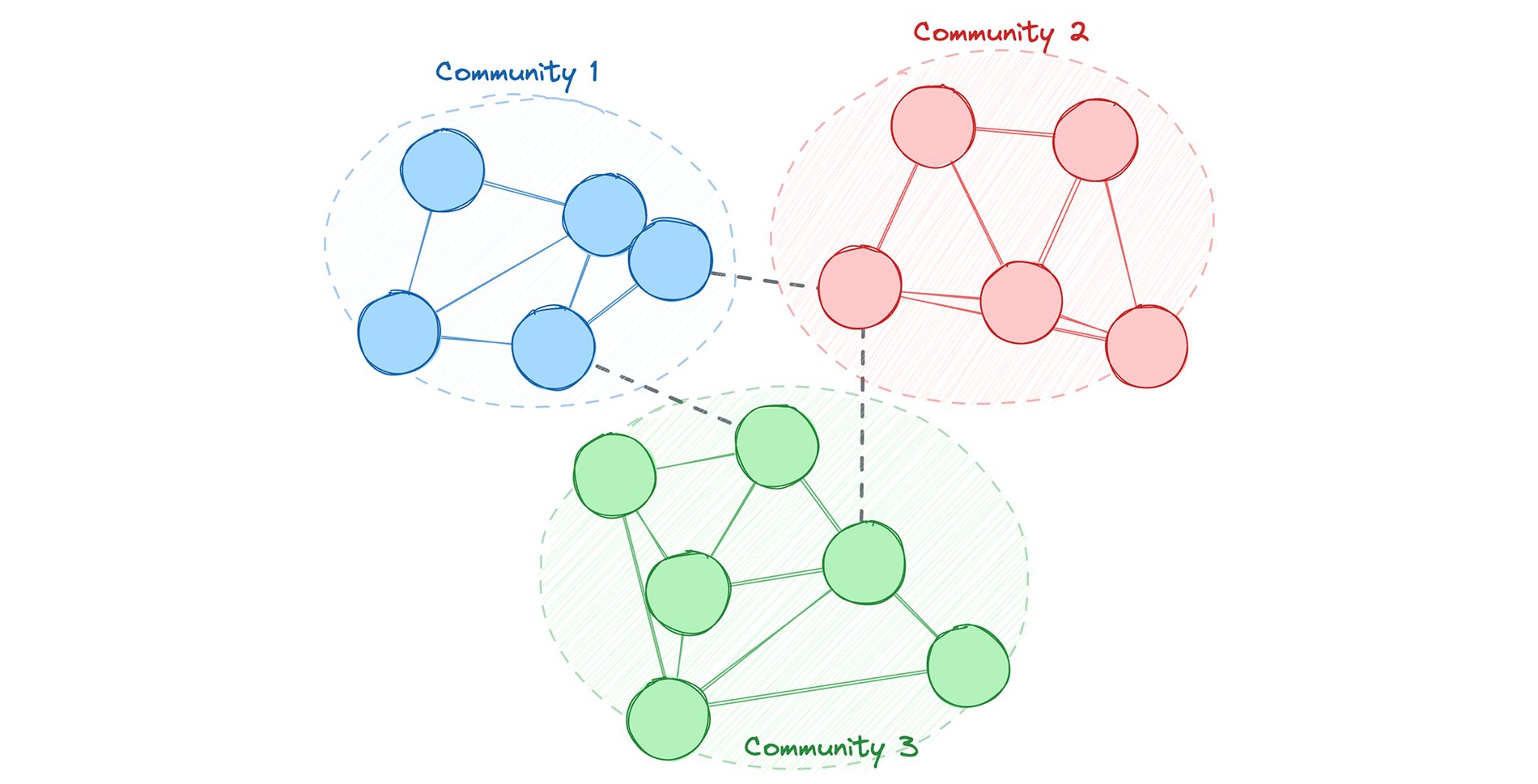
ステップ 2: 不審なコミュニティを特定する(クエリ)すべてのアカウントがコミュニティに属するようになったので、GQL クエリを使用して各コミュニティに対して分析クエリを実行して、異常な行動を明らかにできます。たとえば、各コミュニティ内の既知の不正アカウントの総数を確認できます。
ステップ 3: 影響力を算出して「首謀者」を特定する(サブグラフのアルゴリズム)上記のクエリにより、Community 2 で不正行為が急増していることが明らかになったとします。このステップでは、グラフをフィルタリングして、その特定のコミュニティのアカウントのみを抽出し、PageRank アルゴリズムを実行して、そのグループ内の中心的な首謀者を特定します。
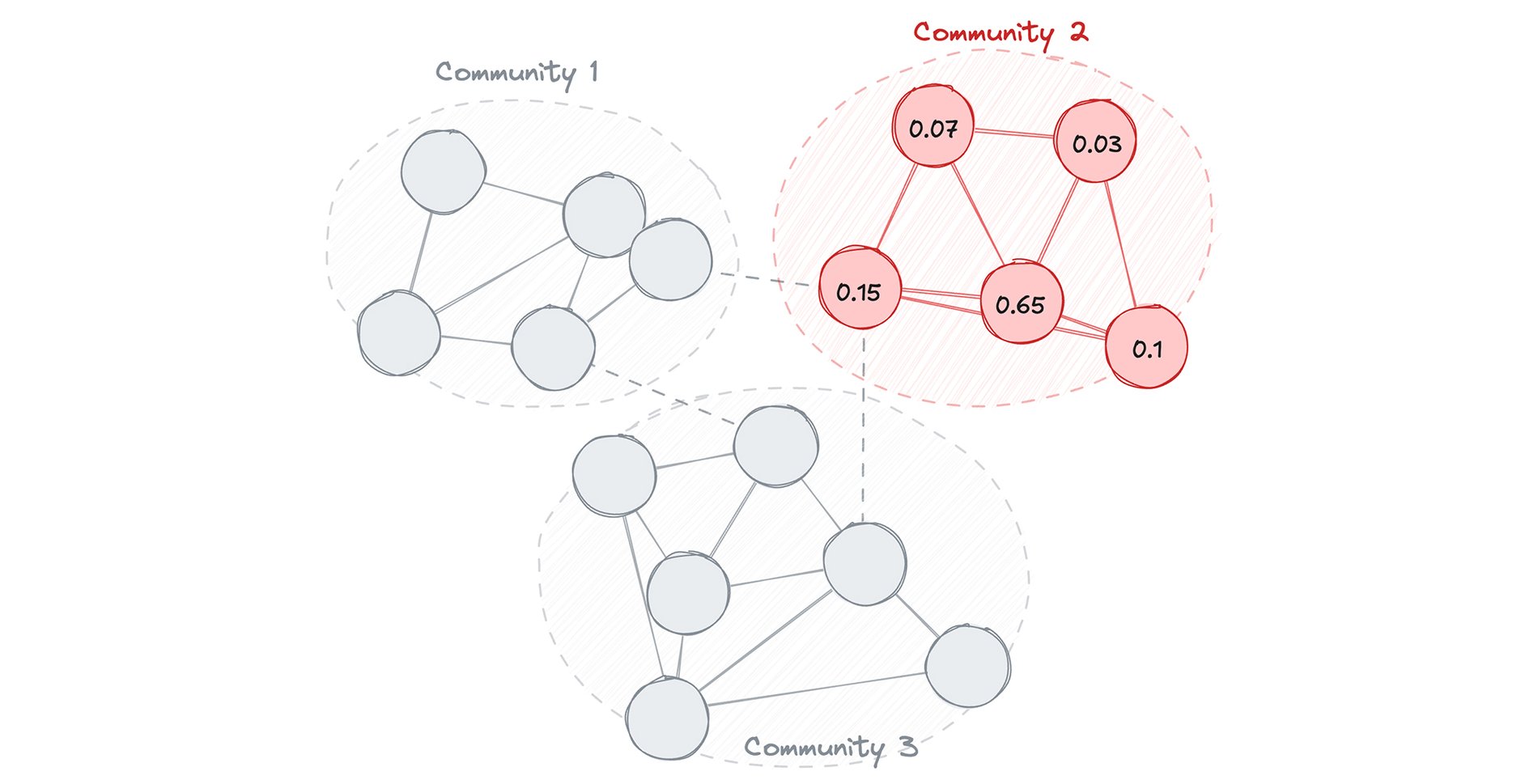
ステップ 4: ターゲットを調査する(クエリ)Community 2 のアカウントに pagerank_score が付与されたことで、最も中心的なアカウントを特定して、その首謀者が最近どこに資金を移動させたかを即座に追跡するクエリを作成できます。
Spanner Graph では、標準の GQL クエリと高性能なアルゴリズムを組み合わせることができるため、オペレーショナル データベースと外部分析エンジン間でデータをやり取りする必要がなくなります。この統合アプローチにより、データ アーキテクチャが大幅に簡素化され、分析情報を取得するまでの時間が短縮されます。
業界のリーダーからの信頼
DaVita、Yahoo!、SoundCloud、WPP といったお客様が、すでに Spanner Graph アルゴリズムを活用して、極めて複雑なデータの課題解決に取り組んでいます。
「当社の Patient 360 イニシアチブに Spanner Graph を活用することで、複雑な医療データを一つの統合ビューに集約できるようになりました。コミュニティ検出や中心性といったネイティブ グラフ アルゴリズムが追加されたことは大きな進歩であり、患者ネットワーク内の深い分析情報をより迅速かつ大規模に発見できるようになりました。これらのフルマネージド機能により、当社のチームは複雑なデータ パイプラインの管理という運用上の負担を負うことなく、患者ケアのイノベーションの推進に注力できます。」- DaVita Kidney Care、チーフ エンタープライズ アーキテクト、Sam Ghosh 氏
「Yahoo を象徴する消費者向けサービスをグローバル規模で運用するには、数十億のユーザー プロファイルを一つのリアルタイム ビューに統合する必要があります。当社の Unified User Profile(UUP)は、Spanner Graph によって一つのグラフとしてモデル化されており、これまで分散していたシステムを信頼できる一元的な情報源として統合しています。また、Spanner にフルマネージドのグラフ アルゴリズムが追加されたことで、大規模なパーソナライズを実現する能力がさらに増強されました。コミュニティ検出や PageRank などのアルゴリズムを活用してオーディエンスのセグメンテーションをより深く行い、プラットフォーム全体でより関連性が高く魅力的なユーザー エクスペリエンスを提供できるようになりました。」 - Yahoo、エンジニアリング担当ディレクター、Chris James 氏
「190 か国以上、4,000 万人以上のアーティストによる 5 億曲以上の楽曲を擁する SoundCloud は、新進気鋭のアーティストが自分のサウンドを見つけたり、隠れた名曲を発見したり、音楽文化をリアルタイムで形成したりする場所です。当社は長年にわたり、グラフ アルゴリズムをバッチモードで実行してきましたが、数十億エッジに及ぶ巨大な音楽グラフを分析するために、カスタム クラスタで数時間かかることもよくありました。Spanner Graph アルゴリズムの登場は、まさにゲーム チェンジャーです。当社が必要とする大規模なスケーラビリティを得られるだけでなく、複雑なカスタム Python ワークフローからフルマネージド サービスに移行することもできます。特に重要なのは、クリエイター ハブの特定やレコメンデーションの改善といったユースケースにおいて、最新のデータに対してグラフ アルゴリズムを実行できるようになったことです。複雑な ETL パイプラインを必要とせず、Spanner で実行されている低レイテンシのトランザクション ワークロードに影響を与えることもありません。」 - SoundCloud、エンジニアリング - データ基盤担当バイス プレジデント、Sergey Chekanskiy 氏
「私たちは、Open Intelligence(当社の基盤となるインテリジェンス レイヤ)に高度なグラフ アルゴリズムを活用することを切望していました。Open Intelligence は、クライアント、パートナー、WPP からの数兆ものライブ データポイントを、プライバシーを最優先にしながら安全に接続するものであり、現在は WPP のエージェント型マーケティング プラットフォームである WPP Open に統合され、その基盤を支えています。数十億ものエンティティにわたる複雑な関係性を即座に探索し、計画、モデリング、試験運用を推進するためには、詳細なグラフ走査、構造的パターン認識、高度なアルゴリズムに対するネイティブなサポートが必要となります。Spanner Graph のアルゴリズム サポートは、運用上のオーバーヘッドや高額なライセンス費用を伴わずに、極めて困難なグラフ分析の問題に取り組むためのパフォーマンスとスケーラビリティを提供してくれます。」 - WPP、データ&インテリジェンス担当戦略責任者、Rob Marshall 氏
よりインテリジェントなアプリケーションの構築
Spanner Graph でアルゴリズムがネイティブにサポートされるようになったことで、基本的な関係性の探索にとどまらず、最新のトランザクション データに対して、詳細な構造分析を直接実行できるようになりました。定番のグラフ アルゴリズムを大規模に適用することで、エンタープライズアプリケーションに新たな機能をもたらすことができます。
-
不正行為の事前検出とマネー ロンダリング対策: コミュニティ検出(モジュール性クラスタリングなど)を使用して、接続された運び屋アカウントを自動的にグループ化することで、詐欺組織を特定します。その後、中心性(PageRank など)を適用して、違法な資金の流れを統率している首謀者を特定します。
-
Customer 360 とエンティティ解決: ジャカードなどの類似性関数や、ラベル伝播などのコミュニティ検出を使用して、断片化されたクロスチャネル データを単一の正規プロファイルに統合します。これらのプロファイルは、各ノードに対して PageRank などのトポロジ特徴を生成することで、ダウンストリームの ML トレーニング用にさらに強化できます。
-
自律的なネットワーク運用とデジタルツイン: IT や通信インフラストラクチャをデジタルツインとしてモデル化し、類似性や経路探索(セット間の最短経路など)を使用して、重大な脆弱性をプロアクティブに特定し、連鎖的な障害を予測します。
-
高度にパーソナライズされたプロダクト レコメンデーション: 基本的な購入履歴にとどまらず、より広範にユーザー行動を分析します。類似性アルゴリズム(共通近傍など)を使用してエンティティ間の嗜好の重複を特定し、さらに、中心性(パーソナライズされた PageRank など)を使用することで、それらのグループにとって最も関連性の高いレコメンデーションを提示します。
-
レジリエンスに優れたサプライ チェーンとロジスティクス: 中心性(中間中心性など)を使用して、過度に依存している物流センターを特定し、経路探索を使用して、障害発生時に効率的な代替ルートを即座に計算することで、サプライ チェーンを隠れたボトルネックから保護します。
-
サイバーセキュリティの脅威ハンティングと影響範囲分析: コミュニティ検出(相関クラスタリングなど)を適用して異常なマシン通信を特定し、経路検出を使用して攻撃者の正確なラテラル ムーブメントと影響範囲を追跡することで、脅威ハンティングを加速します。
-
顧客離れの予測分析: コミュニティ検出を使用して結束の固いサブスクライバー グループを特定し、連鎖的な顧客離れを防ぎます。そのうえで、中心性を適用して影響力の大きいコアメンバーを特定し、離脱が拡大する前に定着を図る施策を実施します。
使ってみる
Spanner Graph アルゴリズムは、Spanner の Enterprise エディションと Enterprise+ エディションでサポートされています。詳細については、ドキュメントをご覧いただくか、こちらの Codelab をお試しください。また、こちらの動画では、Spanner Graph でのグラフ アルゴリズムのサポートについて概要を説明しています。
- シニア スタッフ ソフトウェア エンジニア、Bei Li
-Google Research、グラフ マイニング担当バイス プレジデント兼 Google Fellow、Vahab Mirrokni
