AlloyDB の仕組み: レプリケーションをリアルタイムに近づける

Google Cloud Japan Team
光の速さでデータを同期
※この投稿は米国時間 2023 年 9 月 1 日に、Google Cloud blog に投稿されたものの抄訳です。
AlloyDB は、要求の厳しいトランザクション ワークロードに適した PostgreSQL 互換のフルマネージド データベースです。PostgreSQL のスケーラビリティを拡張するとともに、分析クエリによって運用データからリアルタイムの分析情報を引き出せるようにカラム型エンジンを搭載しています。パフォーマンスも改善されていて、単一マシンでの読み書きパフォーマンスを線形にスケールアップできます。さらに、読み取りプールによって読み取りを水平方向にスケールすることもでき、最大 20 の読み取りノードをサポートします。
レプリケーション ラグは、PostgreSQL リードレプリカを利用しようとしたときに直面する大きな問題の一つです。ワークロードの中には、特にラグを気にしないものがあります。たとえば、ストリーミング サービスのメタデータ カタログは、ラグが問題になるほど頻繁には更新されません。しかし、注文管理のようなワークロードでは、商品の在庫状況やその他のエラーが正しく表示されない可能性があるため、大きなレプリケーション ラグは許容できません。この種のアプリケーションは読み取りクエリをプライマリ インスタンスで実行するよう強制されており、単一のプライマリにバインドされている Postgres はスケーラビリティが実用的な限界に達し始めています。
AlloyDB には、PostgreSQL の読み取り容量を拡張するために設計された機能がいくつか実装されています。AlloyDB の読み取りプールは、単一のエンドポイントの背後で読み取りを水平方向にスケールアウトする便利な手段です。ラグを効率的に低減できる仕組みを備えており、レイテンシに敏感なワークロードでも、読み取りクエリをオフロードできます。水平方向にスケール可能なコンピューティング能力は vCPU 1,000 個分を超えます。AlloyDB のインテリジェント ストレージ システムでは、すべてのインスタンスが 1 つのクラスタにまとめられており、新しい読み取りノードをすばやく起動できます。さらに、低レイテンシの読み取りノードは、プライマリのサイズに縛られない新たな運用データベースの分析能力を提供します。
このブログ投稿では、レプリケーション ラグを低く抑えるために AlloyDB に加えられた改善について説明します。これらの改善により、AlloyDB のリージョン レプリカでは、高スループットのトランザクション ワークロードのレプリケーション ラグが標準 PostgreSQL の 25 分の 1 以下に短縮され、これまでレプリケーション ラグが際限なく増え続けていたワークロードにおいてレプリケーション ラグが一定の限度内に収まるようになりました。
PostgreSQL の物理レプリケーションの背景
まず、Postgres のストリーミング物理レプリケーションについて簡単に復習しましょう。
標準 Postgres では、プライマリに対して読み取り / 書き込みトランザクションを行うと、データベースに加えられた変更を記録したログレコードが生成されます。このログレコードは、Write-Ahead Log(WAL)としてディスクに書き込まれます。リードレプリカが構成されている場合、WAL sender プロセスによってログがネットワークを介してレプリカに送信されます。各レプリカでは、WAL receiver プロセスがログを受信し、WAL replayer プロセスがこれらの変更をデータベースに連続的に適用します。通常のクエリ処理とは異なり、リプレイ プロセスはシングル スレッドで実行され、各ログを逐次的にリプレイします。
このプロセス全体を図示すると、次のようになります。
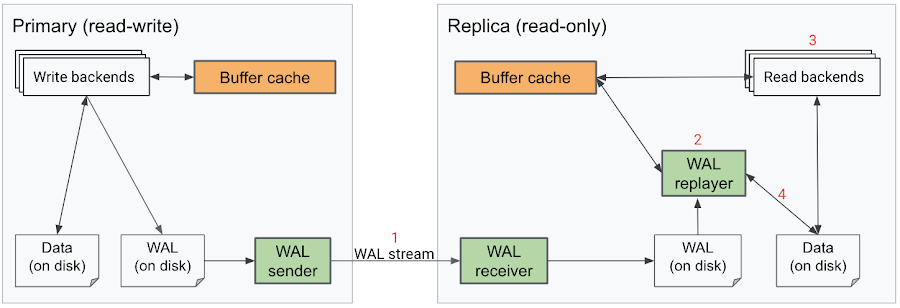
レプリケーション ラグ(「replay_lag」)とは、このプロセス全体に要した時間、すなわちトランザクションによる変更(「WAL」)がプライマリのディスクに書き込まれた時点(「flushed」)から、その変更がレプリカに適用された時点(「replayed」)までの時間を示します。この過程のいくつかのステップは非効率的であり、その結果レプリケーション ラグが大きくなります。
- 完全レプリケーション: レプリカをプライマリと完全に同じになるように更新する必要があるため、プライマリ内のすべてのデータベースのすべての変更をレプリカにストリーミングしてリプレイする必要があります。
- シングル スレッドでの WAL のリプレイ: シングル スレッドで WAL をリプレイするという設計により、レプリカはプライマリより不利な立場に置かれます。書き込み負荷が高い場合、プライマリで WAL が次々と生成されてレプリカでの適用が追いつかなくなり、その結果レプリケーション ラグが増大する可能性があります。
- 読み取りバックエンドとの競合: レプリカでの読み取りトラフィックが増大すると、CPU リソースが WAL replayer から読み取りバックエンドに割り当てられ、ログのリプレイ能力が低下する可能性があります。
- リプレイ中の I/O ボトルネック: 同様に、リプレイ処理と読み取りトラフィックの間で限られたリソース(I/O 容量)へのアクセス競合が起こります。
AlloyDB では、これらの非効率性を軽減するため、アーキテクチャ全体にわたって新機軸が取り入れられています。これにより、プライマリと読み取りプールの双方に過度の負荷がかかっている状況でも高速にレプリケーションできます。
AlloyDB におけるレプリケーション ラグの改善
AlloyDB は、インテリジェント ストレージ エンジン、階層的自動キャッシュ、リプレイ プロセスの改善によって前述の問題を解決しました。AlloyDB のリプレイ アーキテクチャは、見た目は標準 Postgres とよく似ていますが、レプリケーション ラグに実質的な違いをもたらすという点で決定的に異なります。
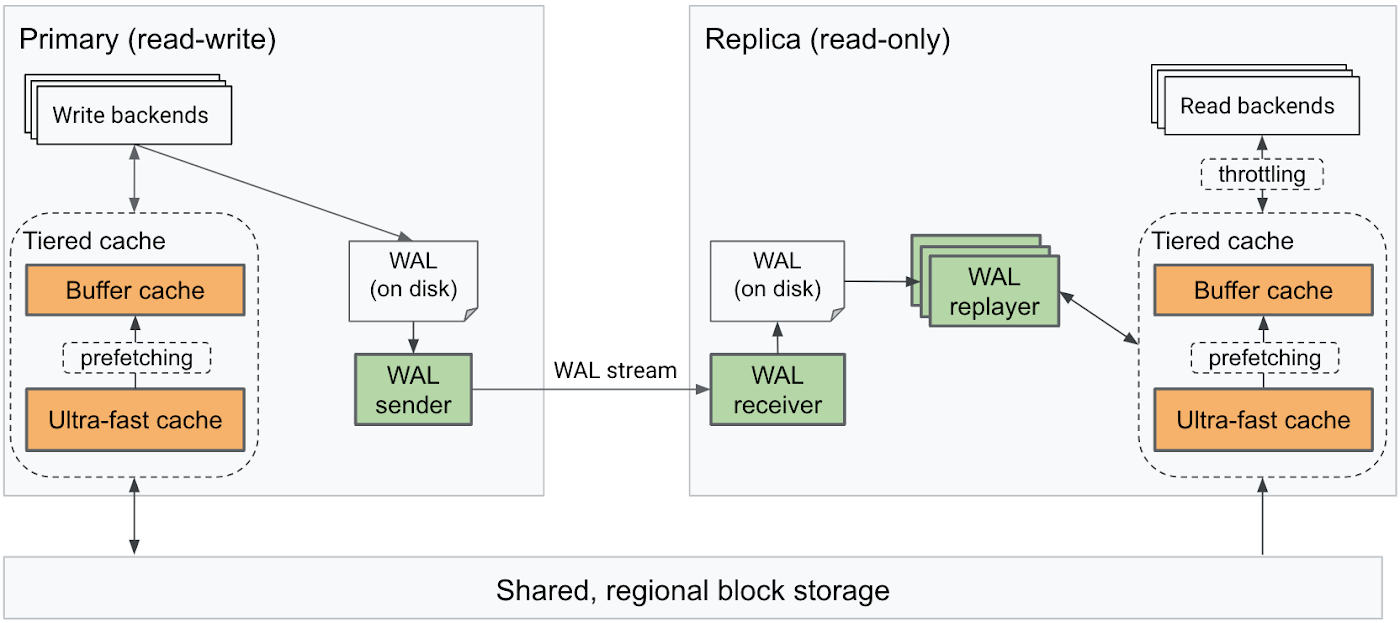
まず、インテリジェント ストレージ エンジンを利用して、一部のログレコードのリプレイをスキップしました。これにより、リプレイの負荷が下がります。AlloyDB クラスタ内のノードはすべて、Google Cloud リージョン内の同じ分散ブロック ストレージを共有しています。リージョン ストレージを使用して最新バージョンのブロックを必要に応じて取得できるため、読み取りノードはキャッシュ内のブロックを最新に保つことのみに従事すれば済みます。
2 つ目に、読み取りノードでのログのリプレイを並列化することで、リプレイ速度を大幅に向上させました。複数の WAL replayer プロセスを配備し、ログレコードを各 replayer プロセスにインテリジェントに分散させて、複数のワーカーが競合なしに同時にリプレイできるようにしました。これにより、プライマリ インスタンスから読み取りノードに大量のログレコードのストリームが送信されてきた場合でも、すばやく処理できます。
3 つ目に、読み取りノードで同時に発生した読み取りクエリの処理ができるだけレプリケーション ラグに影響しないように、WAL replayer プロセスへのリソースの割り当てを優先させました。レプリケーション ラグが大きすぎる場合は、読み取りノードでの読み取りクエリをスロットリングし、キャッシュから多数のデータブロックを読み取ろうとするクエリによって CPU 時間と I/O 帯域幅が独占されないようにします。
最後に、I/O ボトルネックを避けるため、階層的自動キャッシュに組み込んださまざまな改善を利用して、ブロックをインテリジェントにプリフェッチしました。この階層キャッシュ メカニズムは、WAL replayer によって変更されるブロックがウォーム状態になるように、バッファ キャッシュと超高速キャッシュの間でブロックを自動的に移動します。
これらの手法が連携して機能し、広範囲のワークロードにわたって読み取りノードのデータがプライマリとほぼ同じタイミングで更新されることを保証します。ただし、データベース ユーザーとして、レプリケーション ラグを低く抑えるうえで注意しなければならないシナリオがいくつかあります。特に、Postgres の MVCC 実行モデルが原因で、読み取りノードで長時間実行される一部のユーザークエリは、クエリが完了するまで読み取りノードのリプレイ プロセスの進行を妨げます。これはレプリケーション ラグの一時的な急増につながります。このようなトランザクションが完了した後すぐに、読み取りノードは遅れを挽回します。
パフォーマンス結果
AlloyDB をご利用のお客様はすでに、レプリケーション ラグの短縮とそれがアプリケーションにもたらすスケールアウト能力の恩恵を受けています。Character.ai(対話型 AI サービス)は、深くパーソナライズされた独自のスーパーインテリジェンスを消費者に提供しています。
「急速に成長している消費者製品のスケーリングには、常に新たな課題が伴います。かつて当社は、最大規模のデータベース インスタンスまでもが PostgreSQL の制限で壁に突き当たり、CPU ボトルネック、レイテンシの急増、ロック競合、リードレプリカでの際限なく増加するレプリケーション ラグに悩まされていました。AlloyDB に移行した後は、読み取りトラフィックを読み取りプールに安心してオフロードできるようになり、ユーザー エンゲージメントが著しく増加したときも、これらのボトルネックを排除し、半分のクエリ レイテンシで 2 倍の量のクエリを処理できています。AlloyDB の PostgreSQL との完全な互換性と低レイテンシの読み取りプールのおかげで、1 日あたり 10 億人のアクティブ ユーザーに対してスケールできる堅牢な基盤を手にすることができました。」 - Character.ai、研究エンジニア、James Groeneveld 氏
負荷の高い 2 つのシナリオにおいて、AlloyDB と標準 Postgres 14 を比較してみましょう。まずは高い書き込みスループット、次にプライマリでの高い書き込みスループットと読み取りノードでの激しい読み取り負荷の同時発生のシナリオを見ていきます。
これらについて評価するため、TPC-C-like ワークロードと pgbench ワークロードを実行し、レプリケーション ラグとトランザクション スループットを 1 時間測定しました。16 vCPU インスタンスを使用し、(1)100% キャッシュされたデータセット(全体が Postgres 共有バッファに格納されている)と(2)30% キャッシュされたデータセット(データの 30% だけが共有バッファに格納されている)でテストしました。各テストを 5 回ずつ実施し、その平均を以下にグラフ化しました。
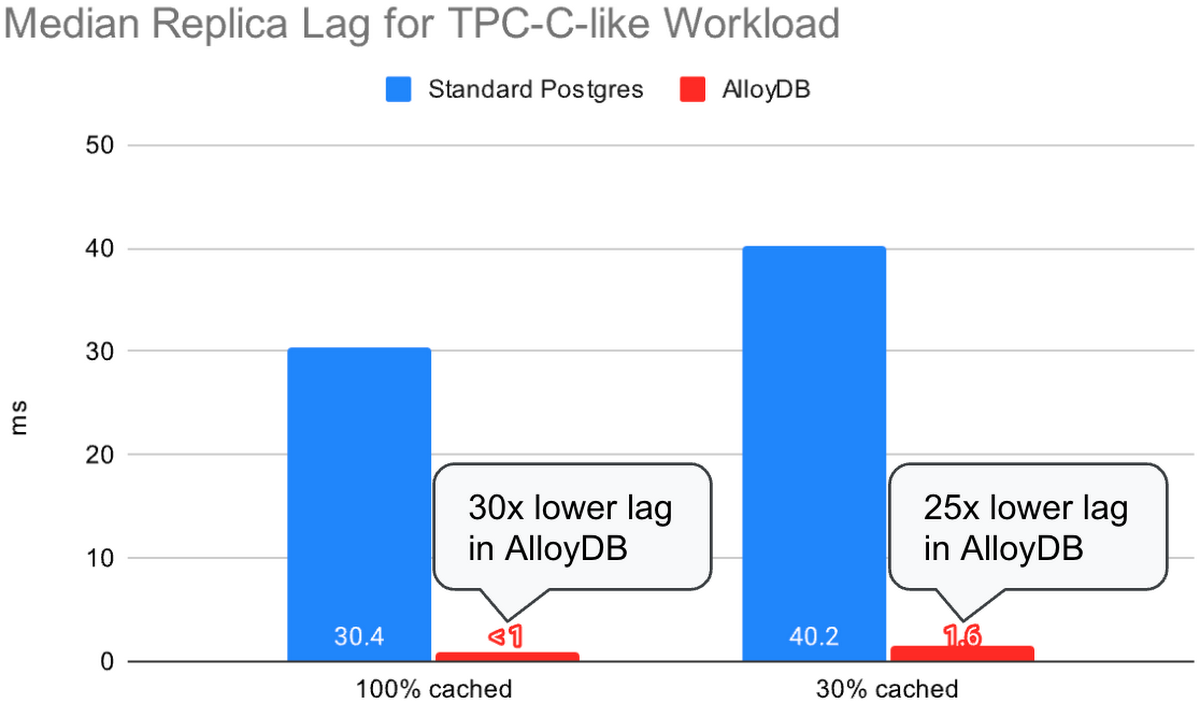
最初のテストでは、レプリカはアイドルにしたまま(レプリカで読み取りクエリを実行せずに)、プライマリで TPC-C-like ワークロードを実行しました。クライアントの数を調整し、1 分あたりのトランザクション数(TPM)が標準 Postgres と AlloyDB の間でほぼ同じになるようにしました。このテストの目的は、標準 Postgres から AlloyDB に移行したときの、同じワークロードに対するレプリケーション ラグの改善を測定することです。100% キャッシュ テストについては、クライアントの数を調整し、標準 Postgres と AlloyDB の TPM がどちらも約 35 万になるようにしました。30% キャッシュ テストについては、TPM は約 115,000 にしました。
同じワークロード(TPM)の場合、AlloyDB のレプリケーション ラグの中央値は標準 Postgres の 25 分の 1 以下でした。
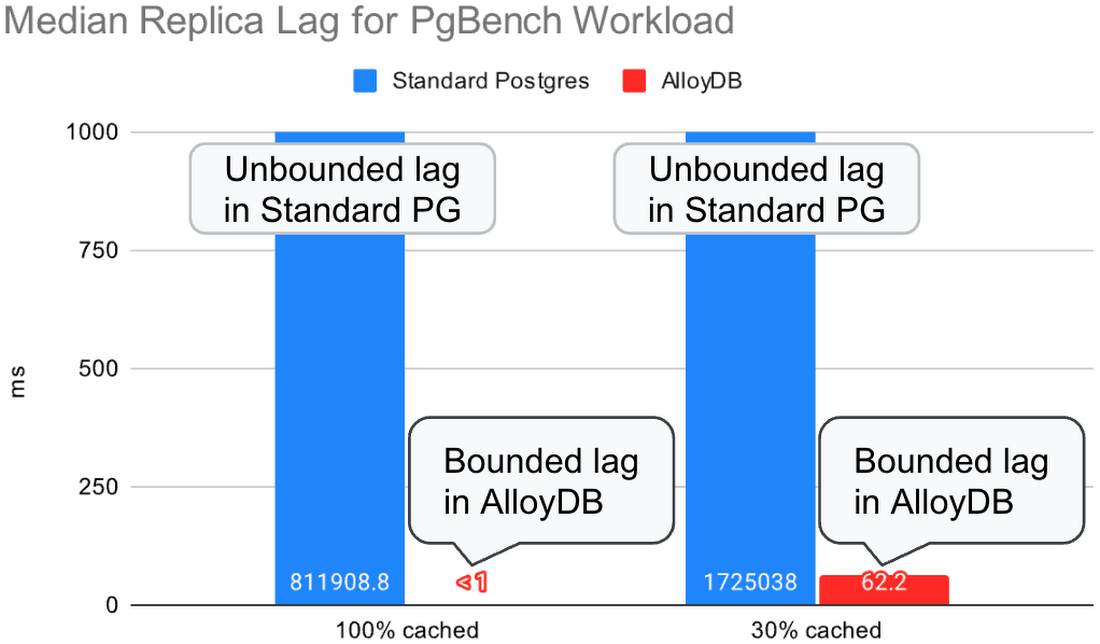
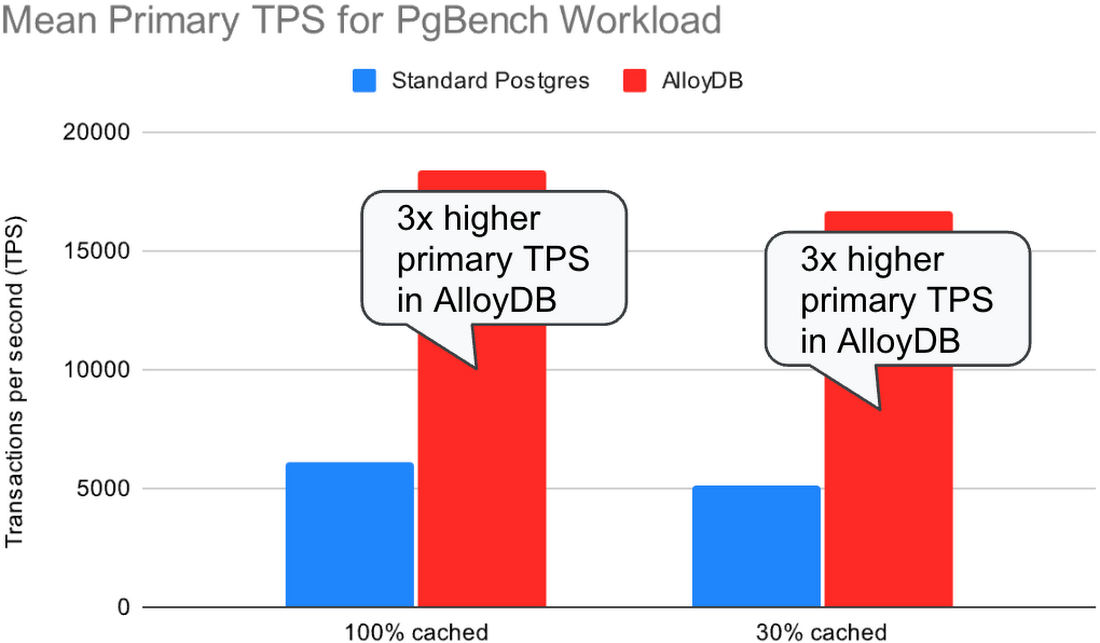
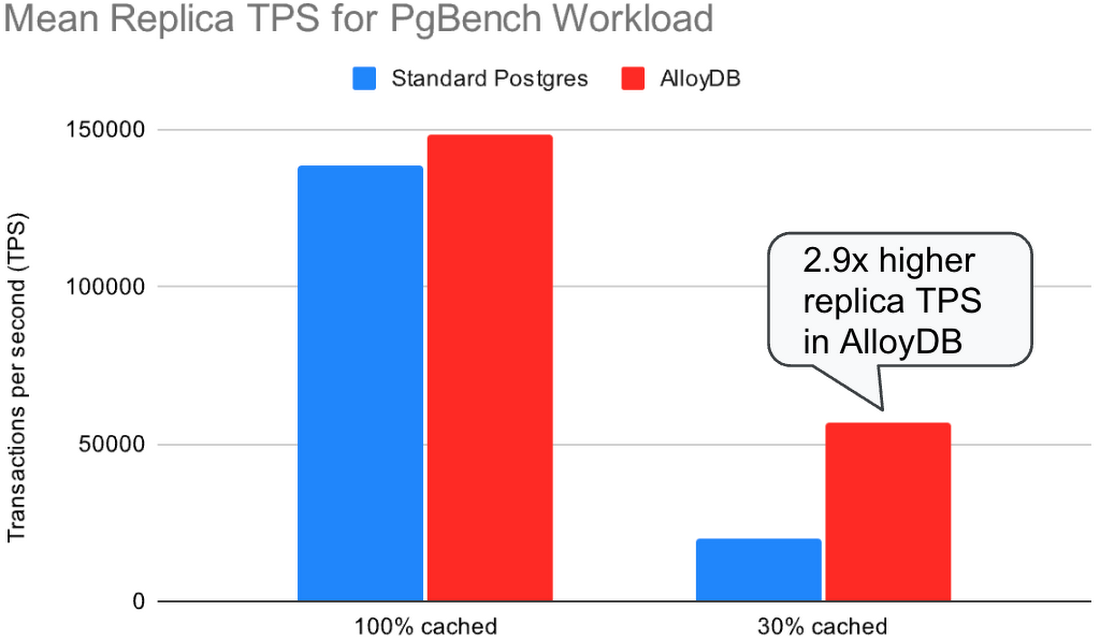
2 つ目のテストでは、プライマリで TPC-B-like pgbench ワークロードを実行しながら、レプリカで select-only pgbench ワークロードを同時に実行しました。レプリカでの読み取りクエリは、リプレイ プロセスとの間で CPU とディスク リソースを奪い合います。クエリのキャンセルと、ログレコードの競合によるレプリカでのログリプレイの停滞を避けるため、hot_standby_feedback=on で実行しました。このテストでは、標準 Postgres と AlloyDB に対して同じ数のクライアント(128 のプライマリ クライアント + 128 のレプリカ クライアント)を使用し、各クライアントが可能な限り高速にクエリを実行できるようにしました。
標準 Postgres では、レプリカは読み取りクエリを同時に処理しながらログストリームに追いつくことができず、レプリケーション ラグは際限なく増加しました。さらに、レプリケーション ラグが増加したことでテーブルとインデックスが肥大化し(遅れているレプリカが読み取りクエリを実行するために古い行バージョンをまだ必要とする可能性があるため、バキュームによって古い行バージョンを削除できない)、その結果プライマリのスループットは低下しました。
AlloyDB では、レプリカはほぼ同じ量の同時読み取りクエリを処理しながら、ログストリームに遅れずについていくことができました。レプリケーション ラグは一定の限度内に収まり、プライマリで処理された 1 秒あたりのトランザクション数は標準 Postgres の 3 倍でした。
まとめ
PostgreSQL ベースのアプリケーションの多くは大きなレプリケーション ラグを許容できません。レプリカを利用できないケースもあり、その場合はスケーラビリティが制限されます。AlloyDB ではこれらの問題が改善されており、標準 Postgres であればレプリケーション ラグが際限なく増加するようなケースでも、読み取りプールで準リアルタイムのレイテンシが実現されます。AlloyDB のベンチマークでは、標準 Postgres の数倍のプライマリ TPS を維持しながら、レプリカラグの中央値は 100 ms 以下に抑えられました。
AlloyDB の低レイテンシ レプリカは、水平方向のスケーラビリティを新たなレベルに引き上げ、レイテンシに非常に敏感なワークロードでも、読み取りクエリの大部分を読み取りプールにオフロードできます。水平方向にスケール可能なコンピューティング能力は vCPU 1,000 個分を超えます。
詳しくは、Google Cloud Next のブレイクアウト セッション DBS210、Google だけが提供できる PostgreSQL: AlloyDB の詳細をご覧ください。AlloyDB を試してみるには、cloud.google.com/alloydb にアクセスしてください。新規のお客様には、ワークロードの実行、テスト、デプロイができる無料クレジット $300 分も差し上げます。こちらから登録して、AlloyDB を無料でお試しください。
ー ソフトウェア エンジニア Anthony Hsu
ー シニア プロダクト マネージャー Emir Okan


