Firestore のコスト効率を COUNT() で強化
Google Cloud Japan Team
※この投稿は米国時間 2022 年 10 月 20 日に、Google Cloud blog に投稿されたものの抄訳です。
アプリケーションが特定のクエリに対して一致数をカウントする必要があるケースが多々あります。たとえば、ソーシャル アプリケーションを開発している場合、個人の友だちの数をカウントする必要があるかもしれません。
本日プレビュー リリースされた count() なら、Firestore で簡単かつコスト効率よく count() を直接実行できます。すべての Google のサーバー、クライアント SDK、Google Cloud、Firebase コンソールからアクセス可能です。
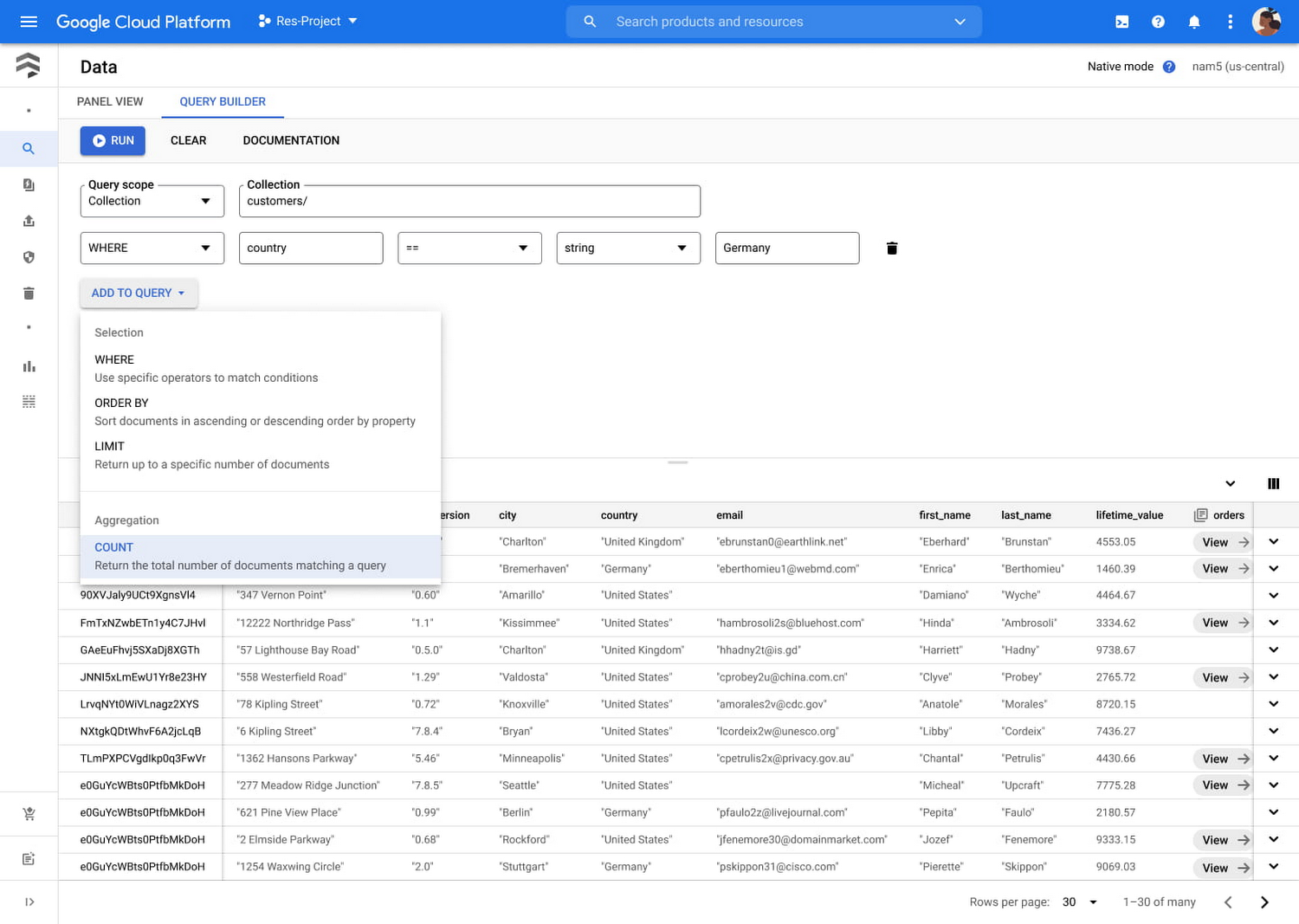
ユースケース
count() がサポートされるようになったことにより、Firestore を使って、すべてのドキュメントを読み込むことなく集計が必要なアプリケーションを構築できるようになりました。これには、ゲームアプリのダッシュボードにアクティブなプレーヤーの人数を表示したり、ソーシャル メディア アプリで友だちの数をカウントしたりといった用途があります。
count() は、コレクション内のアイテムの数や、あらゆるアプリケーションで特定の条件に基づく結果をカウントするために活用できます。
たとえば、「employees」というコレクションがあるとします。
従業員の合計人数の count() を取得するには、以下のクエリを実行します。
それでは、従業員のうち「developers」の合計数を得たい場合はどうでしょうか。
従業員の中からデベロッパー合計のカウントを取得するには、以下のクエリを実行します。
COUNT の仕組み
Firestore は、インデックス エントリの一致に基づいて count() を計算します。
クエリ プランナーが使用する手法についてご説明する前に、2 つの新しい用語を理解しておいてください。
スキャンされたインデックス エントリ: クエリを実行するためにスキャンされたインデックス エントリの数。
一致するインデックス エントリ: クエリに一致するインデックス エントリの数。
count() 関数を使ったクエリを実行すると、関連するインデックス エントリのスキャンが行われ、クエリに一致するインデックス エントリがサーバーでカウントされます。一致するドキュメントを取得する必要がないため、クエリのパフォーマンスは主にスキャンされるインデックス エントリ数の規模に依存します。
COUNT() の料金
Firestore の count() は簡単に使えるだけでなく、コスト効率に優れています。
計算中に一致したインデックス エントリの数に対して課金されます。
インデックス エントリの一致は、既存の Doc Reads SKU にマッピングされ、最大 1,000 件のインデックス エントリの一致が 1 回のドキュメントの読み取り、1,001~2,000 件のインデックス エントリの一致が 2 回のドキュメントの読み取り、のようになります。
たとえば、カウント集計関数を使用するクエリで 1,500 件のインデックス エントリの一致が返された場合は、2 回のドキュメントの読み取りとして課金されます。
count () は無料枠ユーザーの皆様にもご利用いただけます。ドキュメントの読み取りとして課金されるため、既存の無料枠割り当てに従います。
COUNT() の動作
プレビュー期間中、ウェブユーザーとモバイル ユーザーは、オンラインでのみ count() をご利用いただけます。オンラインですべてのクエリに count() 関数を使用できます。現在、リアルタイム リスナーのサポートと、オフラインでの count() 関数へのアクセスには対応していません。
count() 関数は、トランザクションを含むすべての Google の既存クエリパターンで使用できます。
次のステップ
さらに詳しく知りたい方は、ドキュメントをご覧ください。
このコスト効率に優れた使いやすい機能が、カウントに欠かせないことを実感していただければ幸いです。さっそくカウントしてみましょう。
- ソフトウェア エンジニア Joseph(JD)Batchik
- ソフトウェア エンジニア Denver Coneybeare



