ペタバイトから予測へ: Google スプレッドシートで簡単に BigQuery の分析情報を取得
Tarak Parekh
Sr. Product Manager, BigQuery
Laura Gagliano
Sr. Product Manager, Workspace
※この投稿は米国時間 2026 年 5 月 30 日に、Google Cloud blog に投稿されたものの抄訳です。
多くの組織において、信頼できる唯一の情報源となるデータは、Google の管理された安全なペタバイト規模のデータ プラットフォームである BigQuery に保存されています。しかし、アドホック分析、モデリング、レポート作成の「ラスト ワンマイル」は、多くの場合、ビジネス ユーザーが最も使い慣れた Google スプレッドシートで行われています。
このギャップを埋めるには、通常はデータを CSV 形式でエクスポートする必要があります。しかし、この方法は非効率的であり、データサイロ、バージョン管理の問題、セキュリティとガバナンスのリスクをもたらします。コネクテッド シートは、このトレードオフを解消する機能です。使い慣れた Google スプレッドシートのインターフェースが、BigQuery データ プラットフォームにリアルタイムで直接つながるウィンドウに変わり、ペタバイト単位のデータを迅速、安全、かつ簡単に分析できるようになります。
この投稿では、コネクテッド シートの概要を簡単に説明し、実際のユースケースを紹介します。また、Google スプレッドシートで BigQuery を直接使用して、エンタープライズ グレードのデータ分析を行う方法も説明します。
信頼できる唯一の情報源をリアルタイムで確認
ビジネス ユーザーは、簡単なレポートを数日間や数週間も待つことがよくあります。コネクテッド シートを使用すると、SQL を使わずに、数十億行のライブデータへの安全な直接接続を介して重要なデータを分析できるため、この問題を解決できます。
データ管理者にとって、このアーキテクチャの魅力は、強力なセキュリティとガバナンスの体制を維持できる点です。基盤となるデータをコネクテッド シートから変更することはできないため、特定のテーブルやビューへのアクセス権を安心してプロビジョニングできます。また、管理者は Google Workspace のエンタープライズ データ保護を利用して、データのライフサイクル全体にわたってデータの読み取り、共有、コピーを管理することもできます。
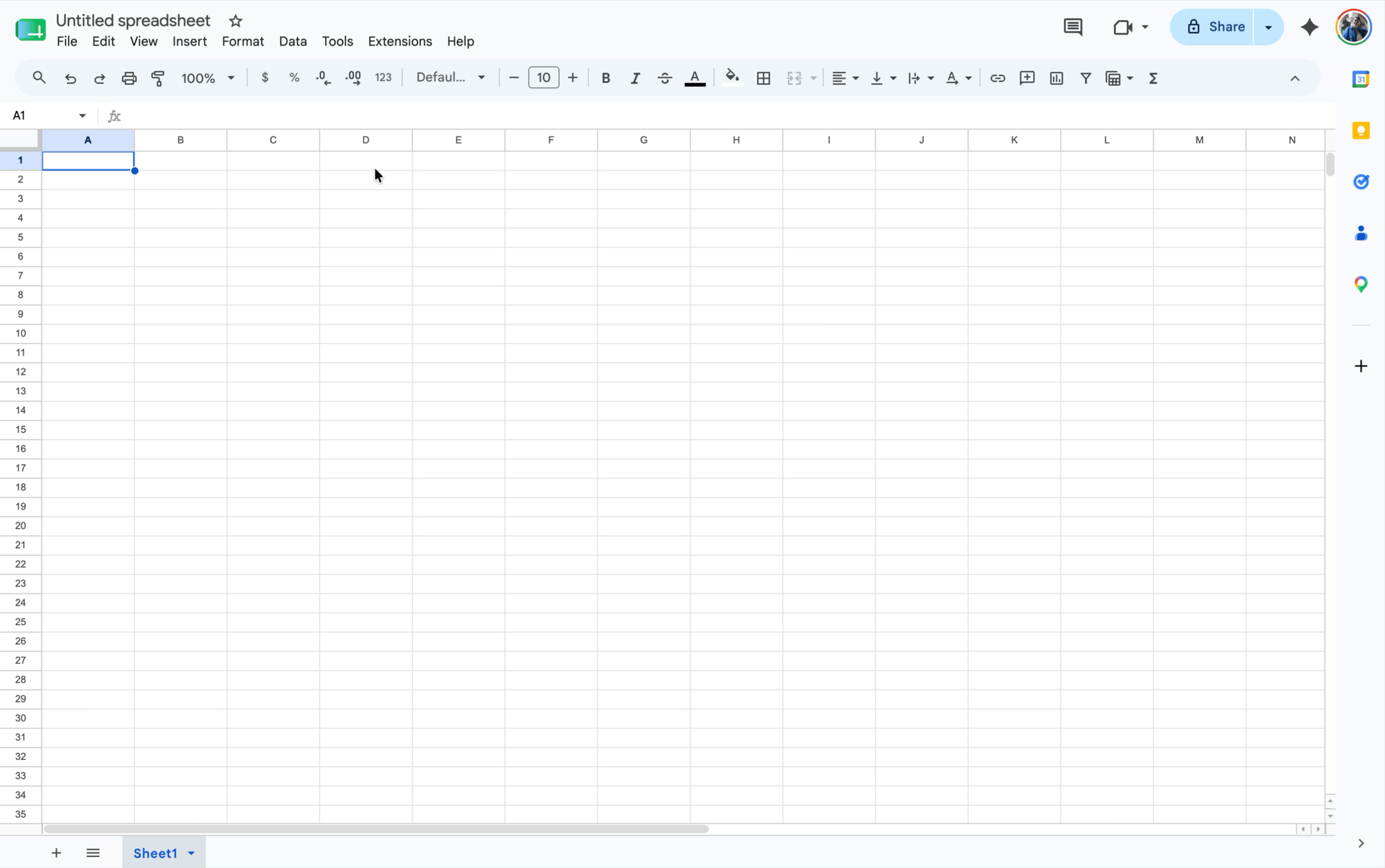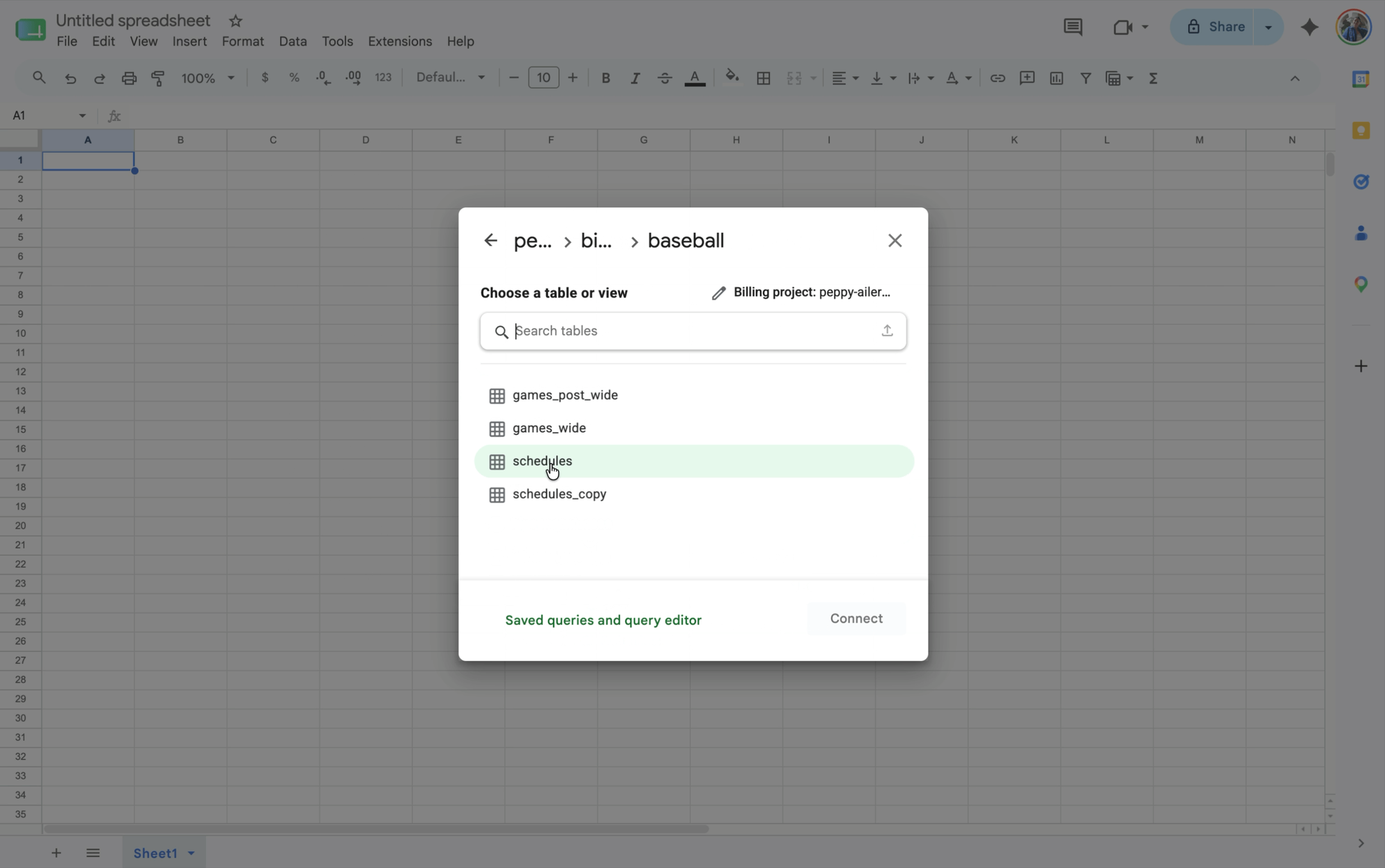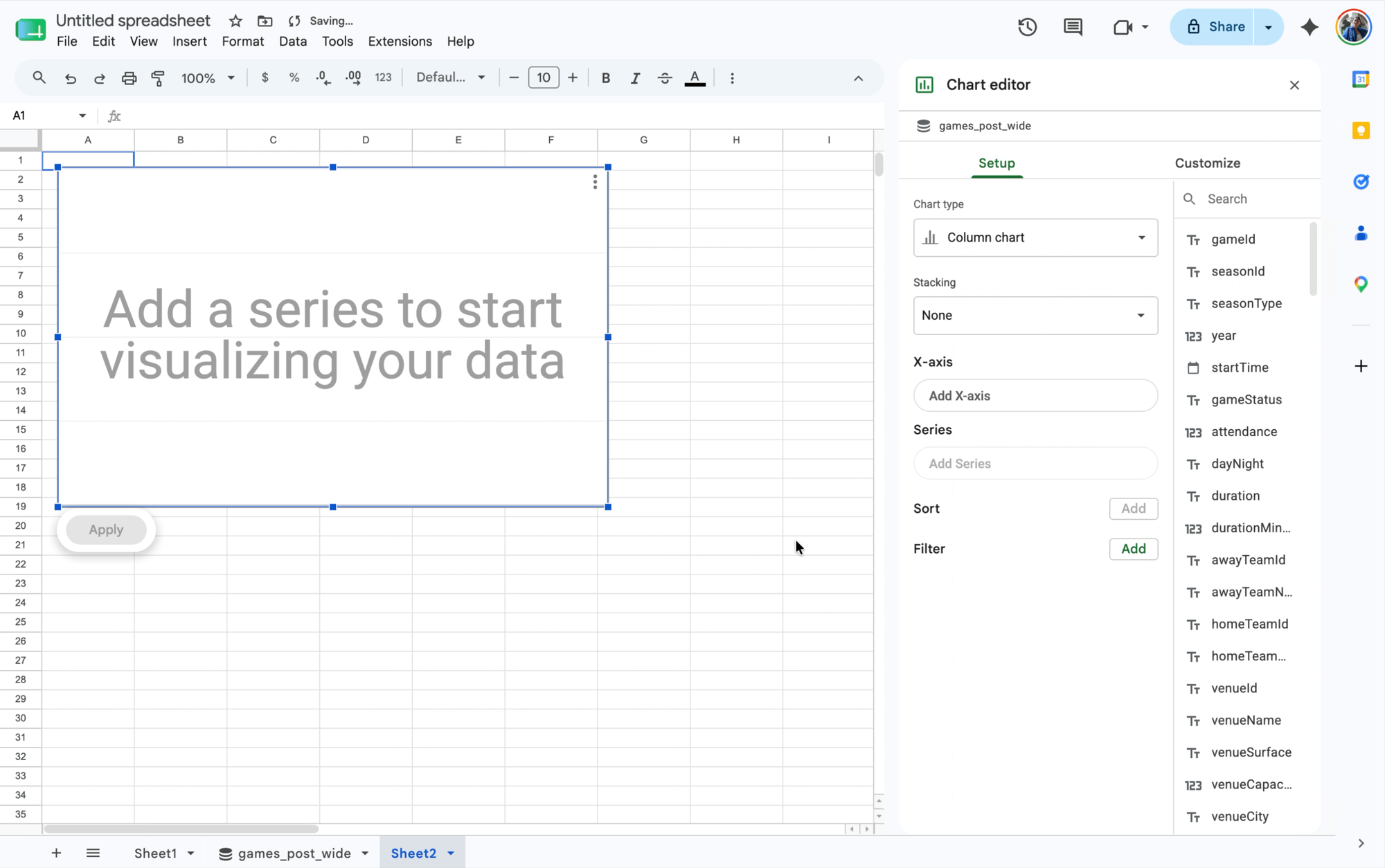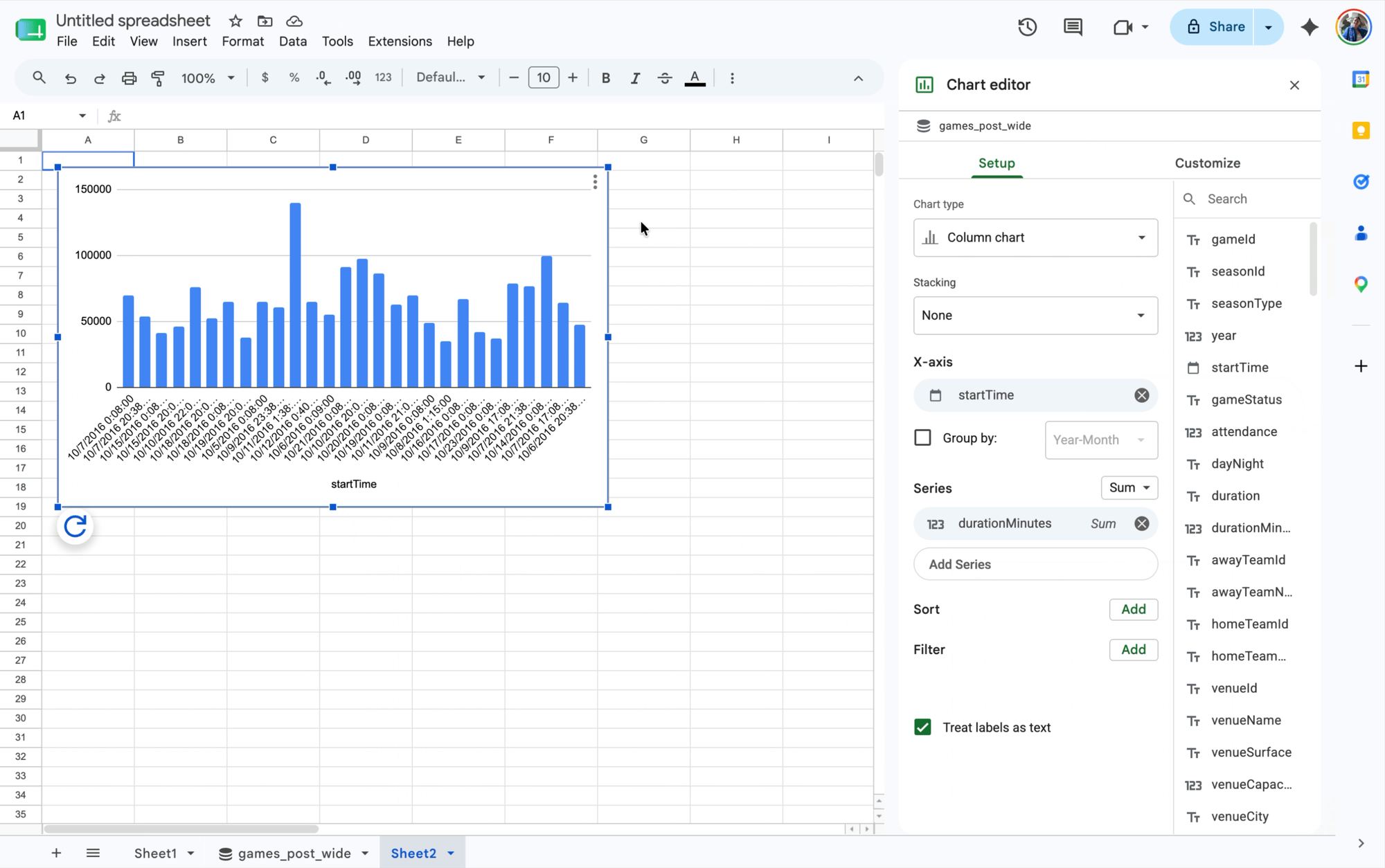
エンドユーザーにとってのメリットは、即座にアジリティを確保できる点と使いやすい点です。ピボット テーブル、グラフ、計算された列、数式などの使い慣れたツールを使用して、数十億行のライブデータをローカル ファイルのように分析できるため、一元管理と、ビジネスに求められるスピードのバランスがとれます。エンドユーザーは、データベース、スキーマ、テーブル、SQL などのクエリ言語といった技術的な概念を学ばずに、データのアクセス、分析、可視化が可能です。
主なユースケースと取り組み
業界を問わず、コネクテッド シートの主なユースケースとして、よく聞くのは次の 3 つです。
1. セルフサービスの探索的分析: データチームが、BigQuery 内のキュレートされたテーブルとデータセットへのアクセスを提供します。セールス、オペレーション、財務、マーケティングのビジネス アナリストは、独自のピボット テーブルやグラフを作成し、スプレッドシートから直接、ライブ データソース全体に対して実行してから、データをフィルタして日常的な問題について確認できます。これにより、データチームは、リクエストが随時、絶え間なく届き、たまっていく状況から解放されます。
例: 詳細な調査
-
シナリオ: 営業マネージャーが、世界中の数百万件の取引を分析して四半期のパフォーマンスを確認します。
-
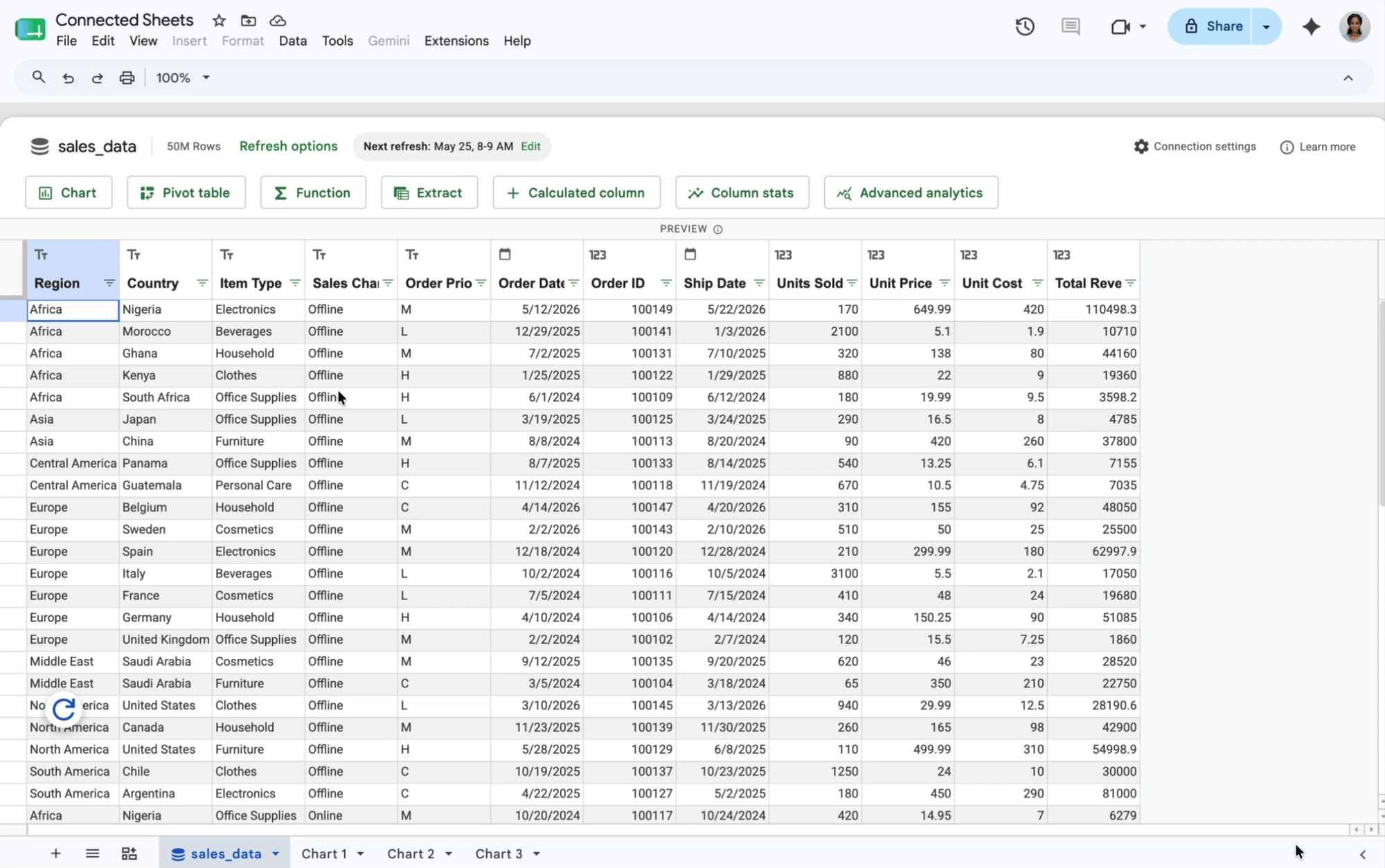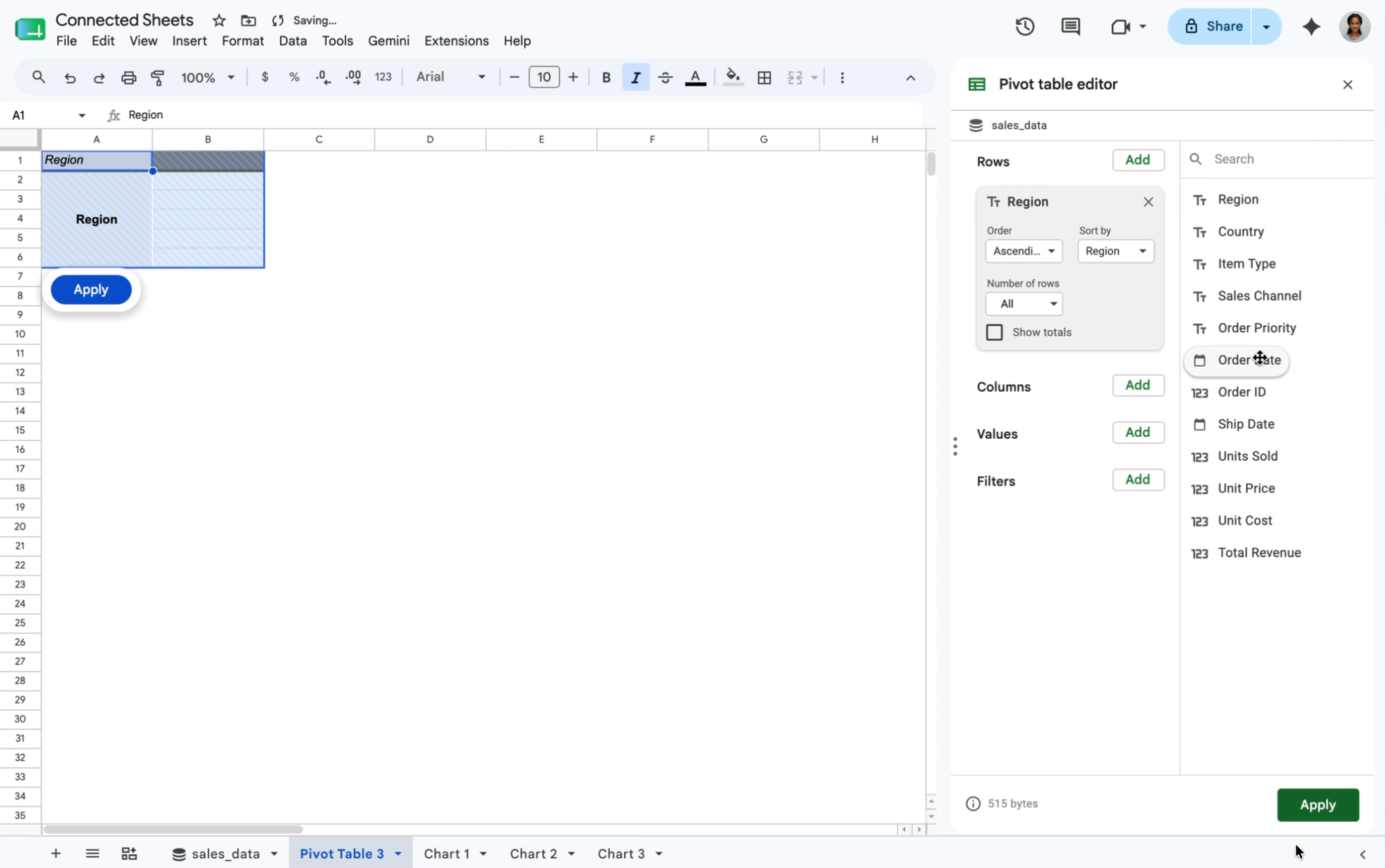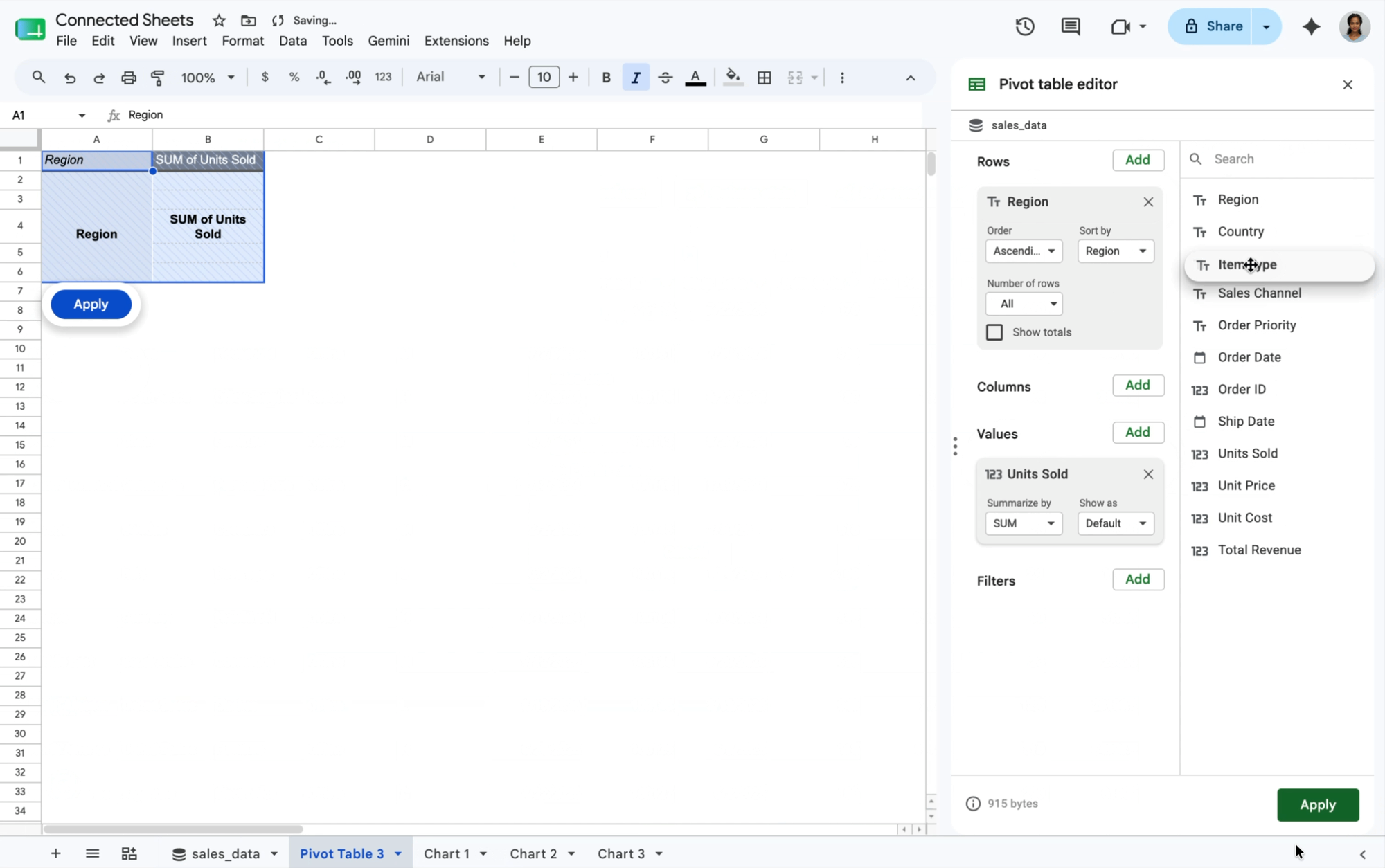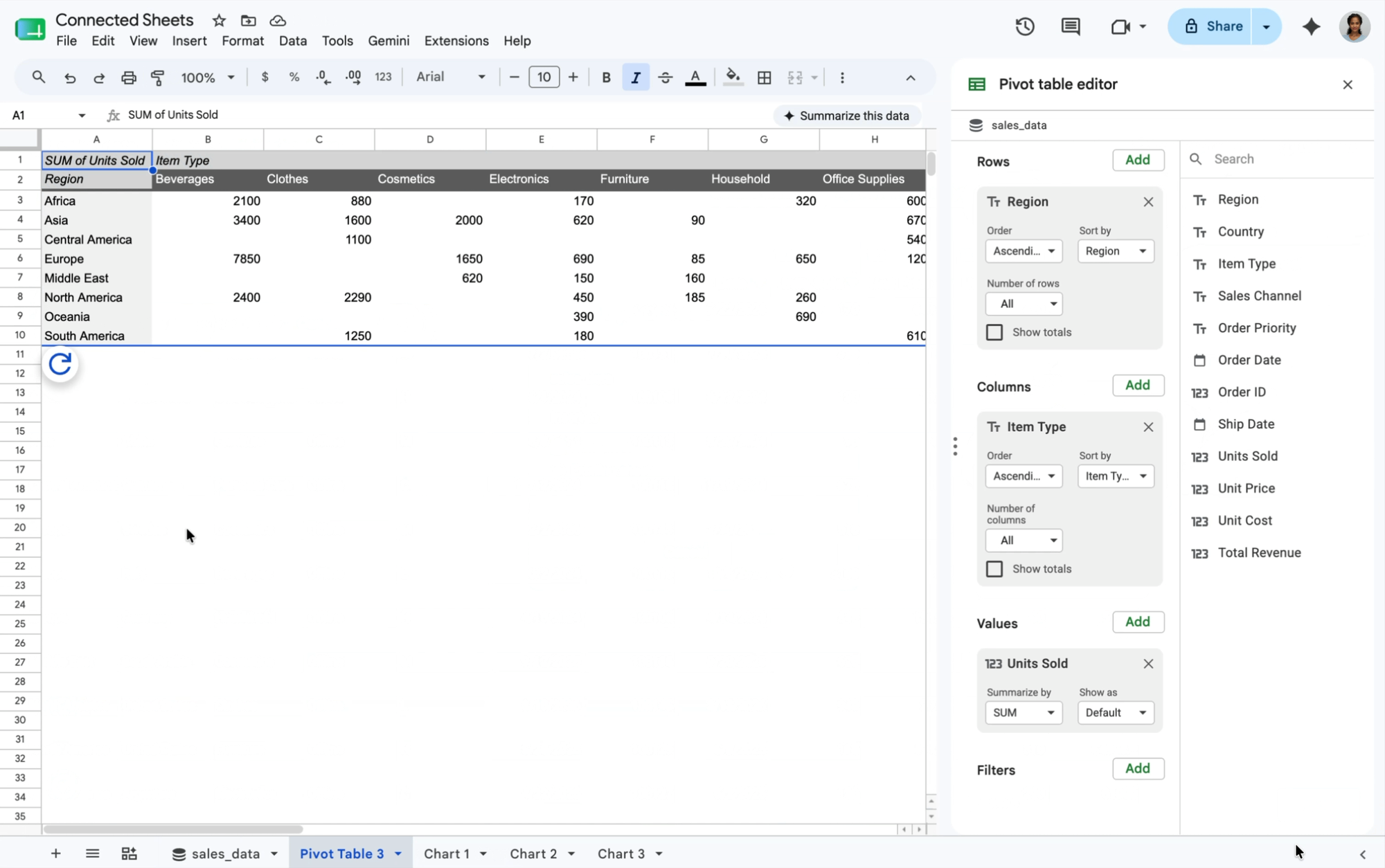
アクション: コネクテッド シートのピボット テーブルを使用して、地域別と商品ライン別の収益を要約するピボット テーブルをすばやく作成します。異常(たとえば、EMEA での予期しない収益の急増)を発見した場合は、要約値をダブルクリックするだけで、ドリルダウンして、その値につながった原因を正確に把握できます。
-
成果: コネクテッド シートが、要約値の根拠となった正確で詳細な取引の行を即座にクエリして取得するため、根本原因の特定が簡単かつ迅速になります。
2. 運用レポート: ビジネス ユーザーが、ライブデータを表示、更新できる、わかりやすいダッシュボードのようなデータビューを作成できます。パートナー チームはこれを信頼し、経営幹部やリーダーと共有できます。
例: エグゼクティブ サマリーの自動化
-
シナリオ: 運用責任者が、数百万行の BigQuery データセットに基づいて、販売請求書に関する状況報告を経営陣に毎週提出します。
-
アクション: 運用責任者は、コネクテッド シートを作成し、請求書の経時的な傾向を可視化する一連のグラフを作成します。次に、毎週月曜日の朝に自動的に更新されるようにシートを構成し、経営陣によるレビューに備えます。
-
成果: データをエクスポートしてワークブックに貼り付けるという手作業が完全に不要になります。経営陣は、最新のウェアハウス データを利用した信頼性の高いレポートと分析を入手できます。
3. ハイブリッド データ モデリング: データの実務担当者は、多くの場合、管理されたデータ ウェアハウスのデータと、リアルタイムの手動入力やアノテーションを融合する必要があります。たとえば、財務チームが BigQuery から収益データを抽出し、それを別のタブで ERP システムに手動で入力された調達データと組み合わせ、VLOOKUP を使用して月末レポート用の統合ビューを作成する場合が考えられます。
例: カスタム ビジネス指標
-
シナリオ: 財務アナリストが、CRM システムのライブ販売データに基づいてカスタムのコミッション支払い額を計算します。コミッションの階層ロジックは頻繁に変更され、中央のデータ ウェアハウスでモデル化されていません。
-
アクション: アナリストは、データチームに新しいデータ パイプラインをリクエストする代わりに、コネクテッド シート内に計算列を直接追加できます。このとき、標準的なスプレッドシートの数式(IF や IFS など)を使用して、カスタム ビジネス ロジックを BigQuery データに直接適用します。
-
成果: アナリストは、管理された BigQuery データを信頼できる唯一の情報源として維持しながら、シナリオをモデル化し、指標を迅速に計算できる柔軟性を確保できます。
ご利用にあたって
Google スプレッドシートと BigQuery の接続は簡単で、Google Workspace アカウントと、課金が有効な Google Cloud プロジェクトがあれば可能です。接続を確立してコネクテッド シートを作成する方法は、主に 2 つあります。
パス 1: スプレッドシートから始めるこれは、主にスプレッドシートで作業するユーザー向けの一般的なワークフローです。
-
新しい Google スプレッドシートを開きます。
-
[データ] > [データコネクタ] > [BigQuery に接続] を選択します。
-
課金が有効になっている Google Cloud プロジェクトを選択します。
-
利用可能なデータセットをブラウジングします。カスタム SQL クエリを入力するか、すぐに接続するには保存済みクエリを選択します。
-
[接続] をクリックします。
パス 2: BigQuery から始めるこのワークフローは、Google Cloud コンソールから開始するデータ アナリストに一般的です。
-
コンソールで BigQuery の UI を開きます。
-
[エクスプローラ] ペインで、分析するテーブルまたはクエリ結果を見つけます。
-
アセットの横にある [エクスポート] メニュー(またはその他メニュー)をクリックします。
-
[次で開く] > [コネクテッド シート] を選択します。
コネクテッド シートでペタバイト単位のデータから予測を生成
コネクテッド シートは、クラウドのスケーラビリティとスプレッドシートの柔軟性のギャップを埋めるために設計されました。コネクテッド シートを使用することで、組織はこれまで以上に簡単にデータを必要な人に提供できるようになります。
これらの機能を試すには、今すぐ BigQuery データを Google スプレッドシートに接続してください。技術的な詳細については、コネクテッド シートのドキュメントをご覧ください。
- BigQuery シニア プロダクト マネージャー Tarak Parekh
- Workspace シニア プロダクト マネージャー Laura Gagliano



