BigQuery でコードを使わずに ML ワークフローを簡単に構築
Google Cloud Japan Team
※この投稿は米国時間 2023 年 6 月 6 日に、Google Cloud blog に投稿されたものの抄訳です。
企業のデータ量が爆発的に増加し続け、企業が予測分析や自動化された意思決定への依存度をいっそう高めるなか、ML や AI 機能を使用してこれまで以上に複雑でスケーラブルなワークロードを実装しようとしている組織にとって現実的な選択肢は、多くの場合、Google BigQuery などのクラウド データ ウェアハウス以外にはありません。
大規模分析の手段となるクラウド
BigQuery は、コンピューティングとストレージを分離することで、比類ないスケーラビリティ、柔軟性、費用対効果を実現します。このサーバーレス データ ウェアハウスは、各種のクラウドで機能し、データに合わせたスケーリングも可能で、BI、ML、AI が組み込まれています。信頼できる単一のデータソースと、ML を活用した真にスケーラブルな分析を求める企業にとって、BigQuery を選択することが事実上のスタンダードになりつつあります。
この投稿では、Google のパートナーである CARTO の革新的なビジュアル分析ツールと BigQuery ML を組み合わせて使用して、より幅広いユーザーベースがクラウド ネイティブ分析を利用できるようにする方法をご紹介します。
CARTO ワークフローは、分析ワークフローを自動化する柔軟性に優れたプラットフォーム ツールで、BigQuery にネイティブに組み込まれた使いやすいコード不要のインターフェースを使用します。
従来のビジュアル自動化ツールはクラウドを十分に活用しておらず、総じて高価
今日のデータドリブンな世界において、企業はより高度な分析やデータドリブン アプリケーションの開発を効率的に行う方法を模索しています。BigQuery を利用すると、アナリストやデータ サイエンティストは使い慣れた SQL コマンドを使用して大量のデータを処理できますが、他のビジュアル分析ツールの多くは完全なクラウドネイティブではなく、十分とは言えません。これらのソリューションは、柔軟性がない高価なデスクトップやサーバーベースのインフラストラクチャに依存しているため、多くの場合、包括的なデータ ガバナンスに欠けており、パフォーマンスの制限が生じたり、オンデマンドでスケールすると費用が高くなる場合があります。
BigQuery のネイティブなビジュアル分析である CARTO ワークフローの紹介
CARTO ワークフローでは、コンポーネントとデータ ソースをドラッグ&ドロップして、分析を視覚的に設計できます。その後、ワークフローは自動的に SQL にコンパイルされ、BigQuery にプッシュダウンされます。ユーザーは、BigQuery SQL の機能とその拡張機能すべてを使用して、高度な分析ワークフローを設計、実行、自動化、共有できます。
必要に応じて、分析パイプライン全体を作成して可視化し、個別のステップを実行してデバッグできます。ワークフローで作成されたものはすべて、BigQuery でネイティブに計算されます。このシンプルなツールにより、チーム全体で広範に分析を導入して迅速にオンボーディング可能になり、専門知識がなくても幅広いユーザーが高度な ML 機能を利用できます。
CARTO ワークフローで BigQuery ML を活用
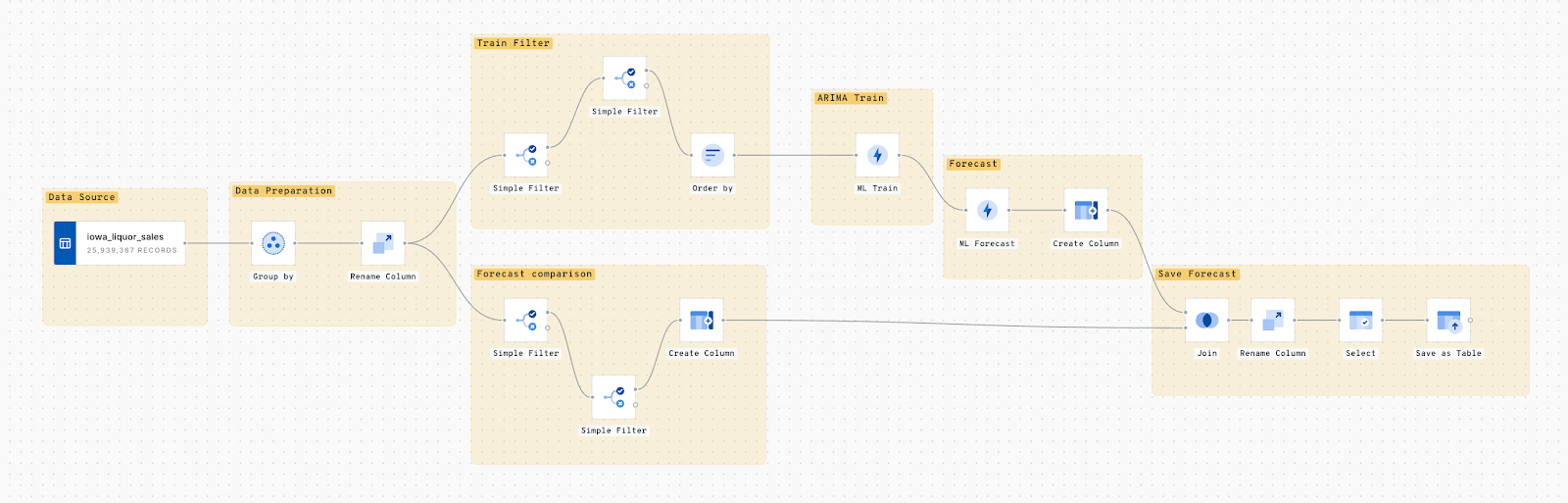
CARTO ワークフローと BigQuery の組み合わせの強みを示すために、実際の例を見てみましょう。このシナリオでは、BigQuery ML で利用可能な ARIMA ファミリーに基づくモデルを使用して、消費者ブランド カテゴリの店舗における毎日の売上を予測するワークフローを構築します。
手順 1 - データを入力する
この例では、一般公開されている、アイオワ州の酒類売上のデータセットを使用します。このデータセットには、こちらの Google Cloud Marketplace からアクセスできます。この分析を複製するには、CARTO の 14 日間の無料トライアルにご登録ください。BigQuery へのネイティブ接続を使用して、CARTO Data Explorer を介してこのデータセットにアクセスし、データセットをワークフロー キャンバスにドラッグするだけで複製できます。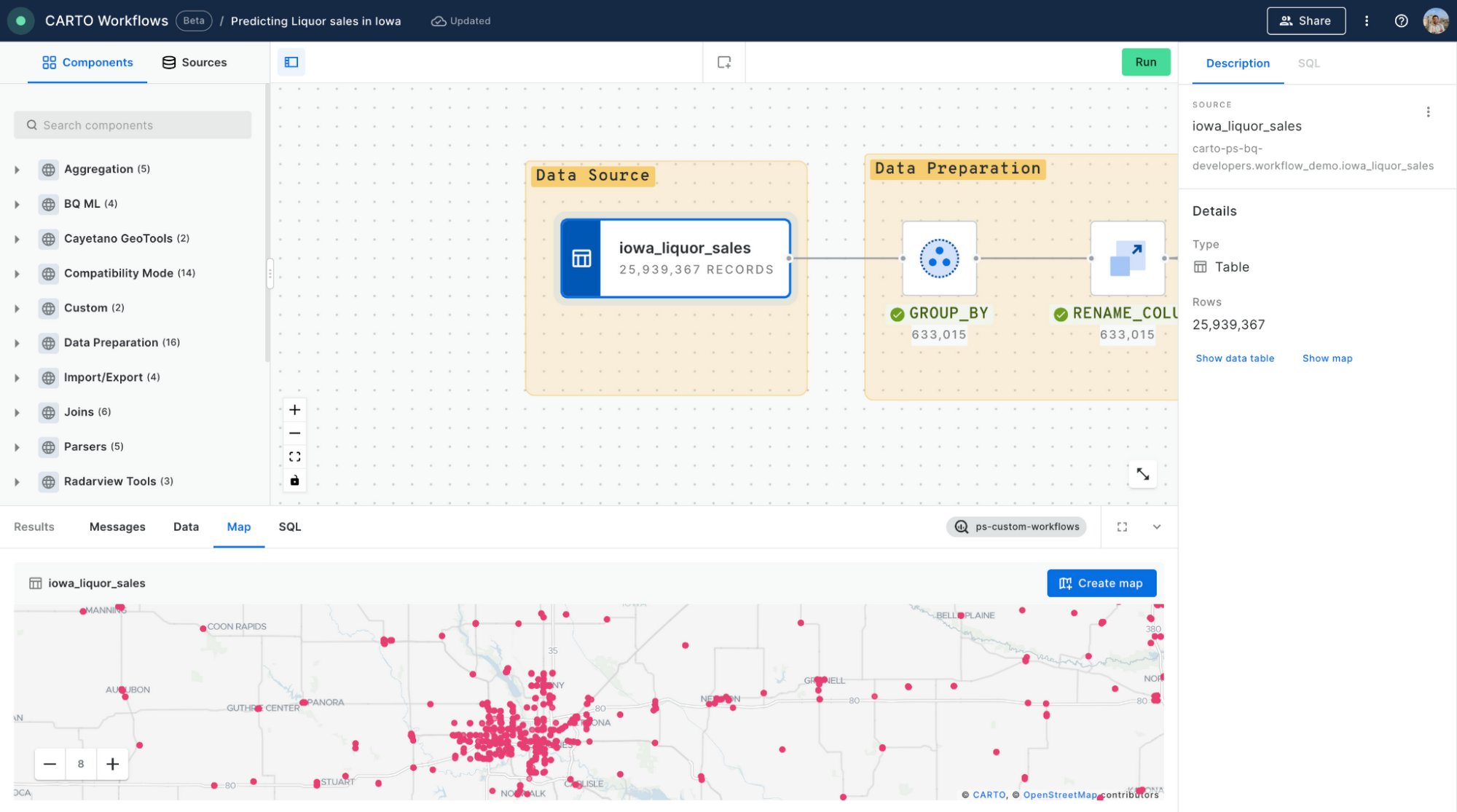
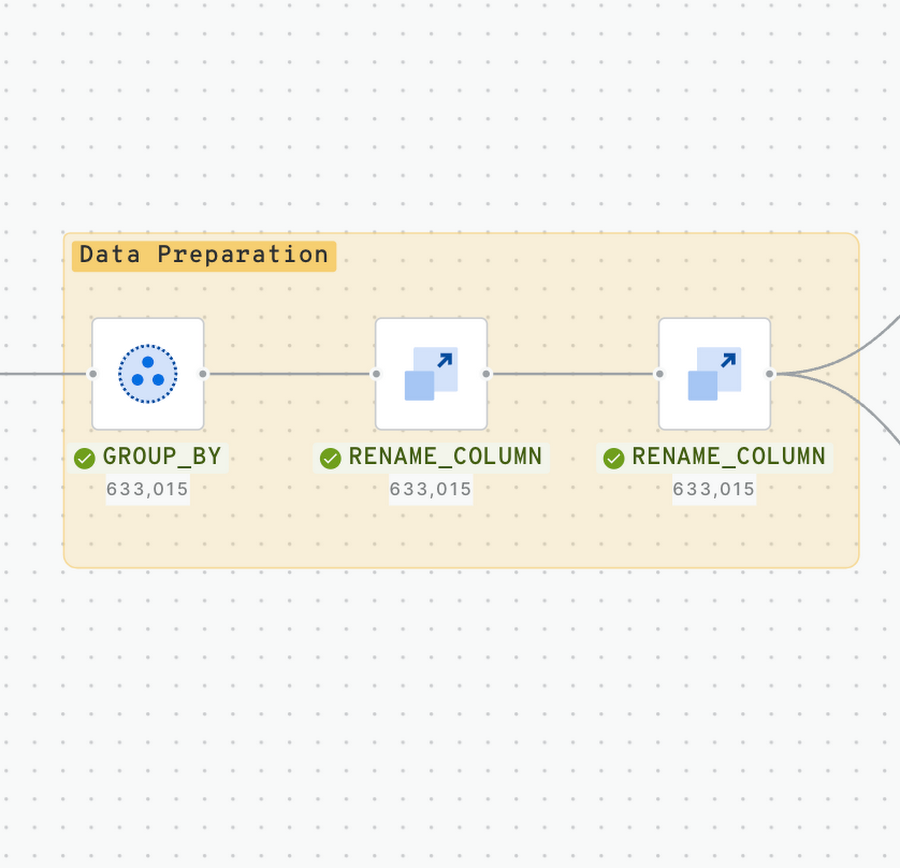
手順 2 - データの準備
日々の酒類売上の全トランザクションが含まれているため、トランザクションを店舗ごとおよび日付ごとにグループ化する必要があります。これにより、POS ごとの 1 日の売上高が得られます。
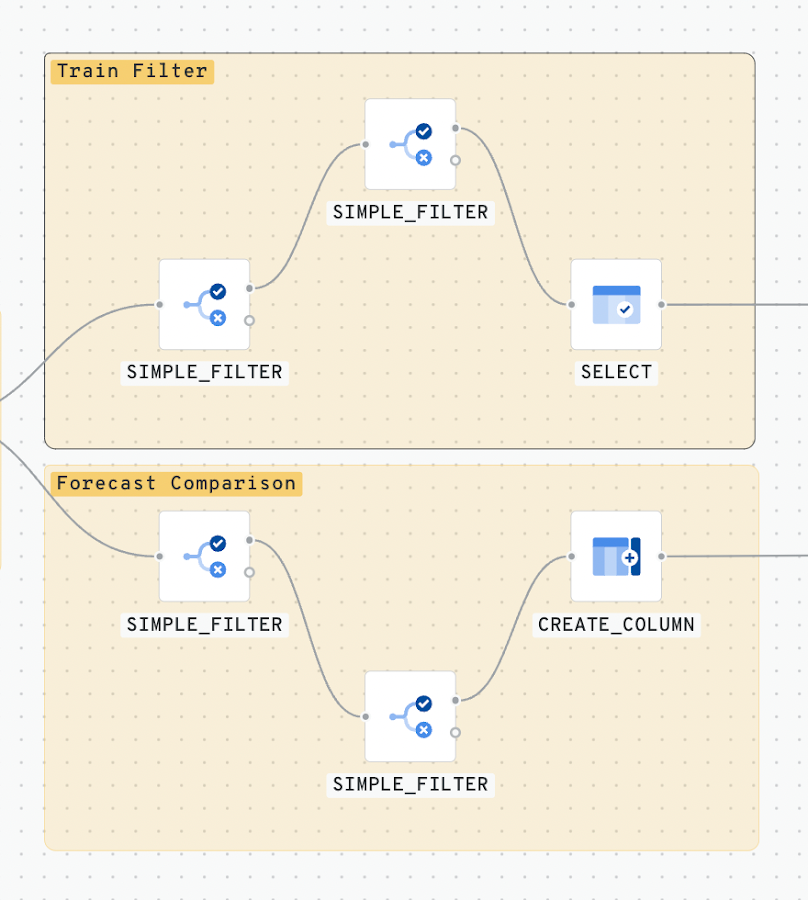
手順 3 - モデル トレーニング フィルタ
モデルの期限は 2020-06-01 です。モデルをトレーニングには、それ以前の日次データを使用します。そのためには、Simple_Filter を実行する必要があります。さらに、過去 1 年間のデータを使用して予測するため、2019-06-01 の日付で追加の Simple_Filter を適用します。
次に、データセットから目的の列を選択し、最新データのみが表示されるように並べ替えます。
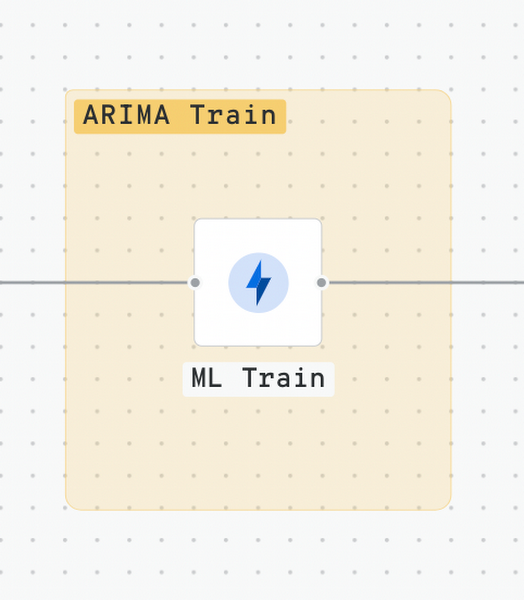
手順 4 - ARIMA モデルのトレーニング
ARIMA モデルでのデータのトレーニングでは、1 つのクエリで 1,802 店舗の変数を使用し、10 分足らずで完了しました。BigQuery から CREATE_MODEL ステートメントを使用します。米国の祝日が選択されています。頻度は毎日で、さまざまな季節性も考慮されます。係数推定とパラメータ選択のタスクは BigQueryML に任せます。ワークフローで定義される BigQuery オプションは次のようになります。
手順 5 - 予測
また、ML.FORECAST を使用して、毎日の売上予測を行います。予測値のための入力を選択するだけで、信頼区間も設定できます。このプロセスでは、新しくトレーニングされたモデルを使用して、設定された期間に従って将来の予測を行います。また、index(CONCAT DATE WITH STORE NUMBER) という名前の列を追加します。この列は、予測データとその実際の値を結合して結果を比較するために使用されます。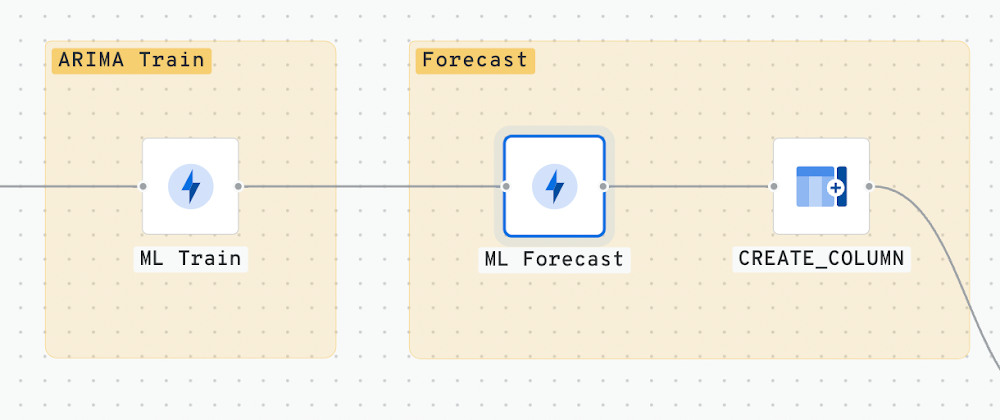
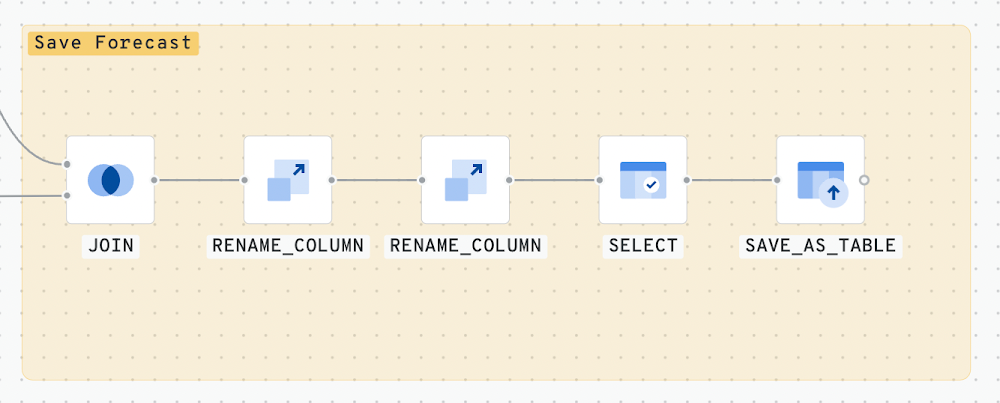
手順 6 - 予測の保存
この最後の手順では、予測の結果を BigQuery テーブルに保存します。保存した結果をさらに分析したり、CARTO Builder を使用して出力を可視化したりすることもできます。
このワークフローの実際の手順全体を確認するには、次の動画をご覧ください。
BigQuery が分析の分野をリードしているのには十分な理由があります。BigQuery は信頼できる単一のデータソースを提供し、より優れたデータ ガバナンスを可能にしながら、重複を回避し、ワークロードの需要に基づいて自動的にスケールします。CARTO ワークフローとその使いやすいビジュアル インターフェースを組み合わせることで、高度なデータ パイプラインを自動化して、クラウドネイティブな ML 機能をビジネス ユニット全体で最大限に活用できるようになり、ユースケースの幅が無限に広がります。
CARTO ワークフローを試すには、こちらをクリックしてください。
- プロダクト マーケティング担当バイス プレジデント Matt Forrest

