Google Cloud TPU と GPU で AI 推論を高速化

Google Cloud Japan Team
※この投稿は米国時間 2024 年 4 月 11 日に、Google Cloud blog に投稿されたものの抄訳です。
AI を取り巻く状況が急速に進化するなか、高パフォーマンスで費用対効果の高い AI 推論(サービング)への需要がかつてないほど高まっています。今週、JetStream と MaxDiffusion という 2 種類の新しいオープンソース ソフトウェア プロダクトを発表しました。
JetStream は XLA デバイス向けの新しい推論エンジンです。まずは Cloud TPU からのご提供となります。大規模言語モデル(LLM)に特化した設計で、パフォーマンスと費用対効果の両面が飛躍的に向上しています。以前の Cloud TPU 推論エンジンと比べると、LLM での料金あたりの推論回数が最大 3 倍になりました。JetStream は PyTorch / XLA を通じて PyTorch モデルをサポートしているほか、MaxText を通じて JAX モデルもサポートしています。MaxText は Google が提供する LLM 向けのリファレンス実装で、優れたスケーラビリティと高パフォーマンスが特長です。お客様は MaxText をフォークして開発をスピーディーに進めることができます。
MaxDiffusion は MaxText に類似した、潜在拡散モデル向けのリファレンス実装です。XLA デバイスで高パフォーマンスを実現するように最適化された拡散モデルのトレーニングとサービングを簡単に行えるようになります。まずは Cloud TPU からのご提供となります。
また、大変誇らしいことに、MLPerf™ Inference v4.0 の最新のパフォーマンス結果では、NVIDIA H100 GPU を使用した Google Cloud の A3 仮想マシン(VM)のパワーと汎用性が示されました。
JetStream: 高パフォーマンスで費用対効果の高い LLM 推論
LLM は AI 革命の最前線として注目を集めており、自然言語理解、テキスト生成、翻訳など幅広い用途で活用されています。LLM 推論を利用する際の費用を少なく抑えるために、Google は JetStream という推論エンジンを開発しました。以前の Cloud TPU 推論エンジンと比べると、LLM での料金あたりの推論回数が最大 3 倍になります。
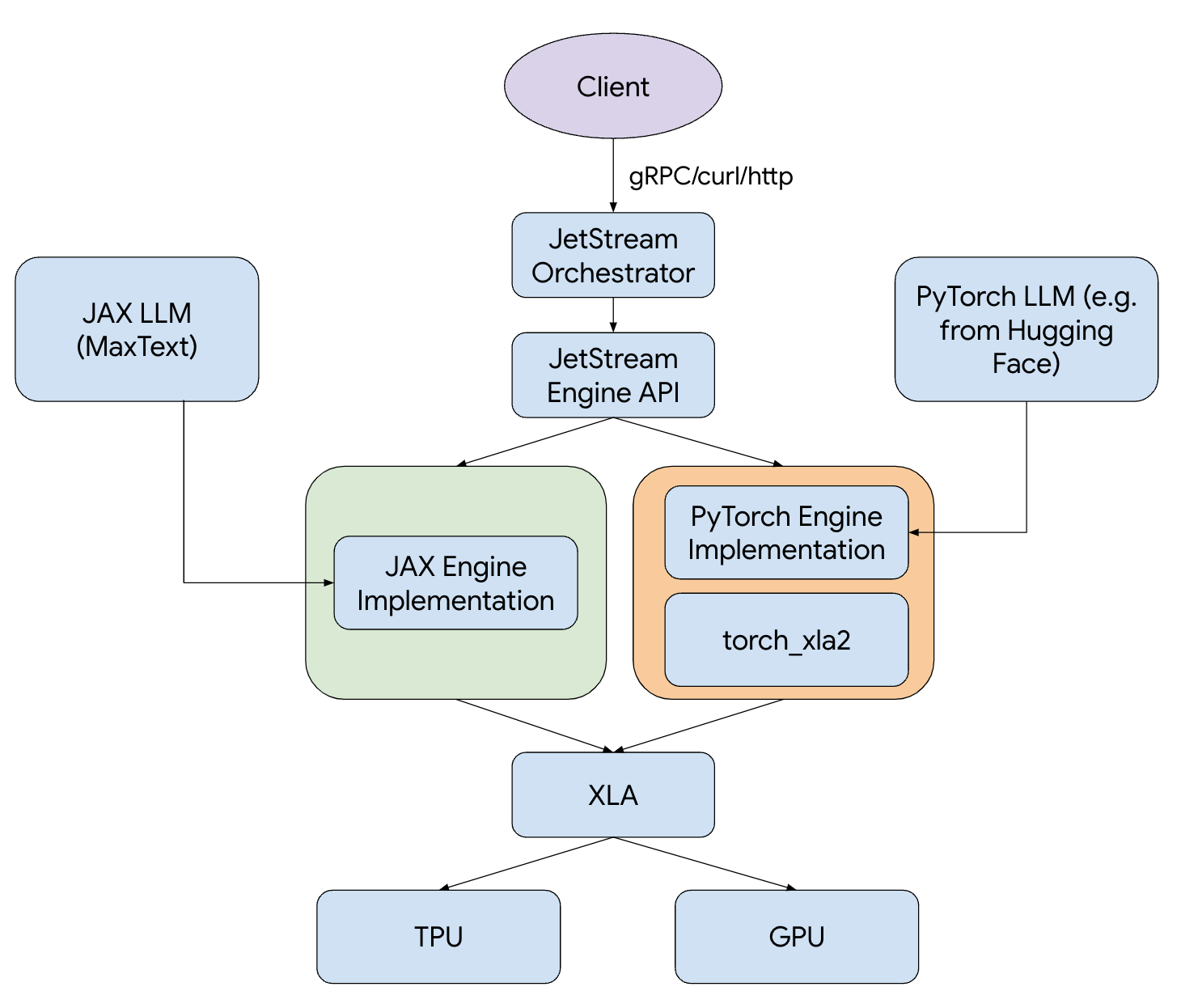
図 1: JetStream スタック
JetStream には、連続的なバッチ処理、Sliding Window Attention、重み、アクティベーション、Key-Value(KV)キャッシュの int8 量子化など、高度なパフォーマンス最適化機能が含まれています。JAX と PyTorch のどちらを利用する場合でも、JetStream は利用者が希望する任意のフレームワークをサポートします。LLM 推論ワークフローをさらに効率化するために、Gemma や Llama などの主要なオープンモデルに対応した MaxText と PyTorch / XLA の実装も提供しています。費用対効果とパフォーマンスを最大限に高めるように最適化されたものです。
Cloud TPU v5e-8 では、JetStream は MaxText での Gemma、PyTorch / XLA での Llama 2 などのオープンモデルで最大 4,783 トークン/秒を実現しています。
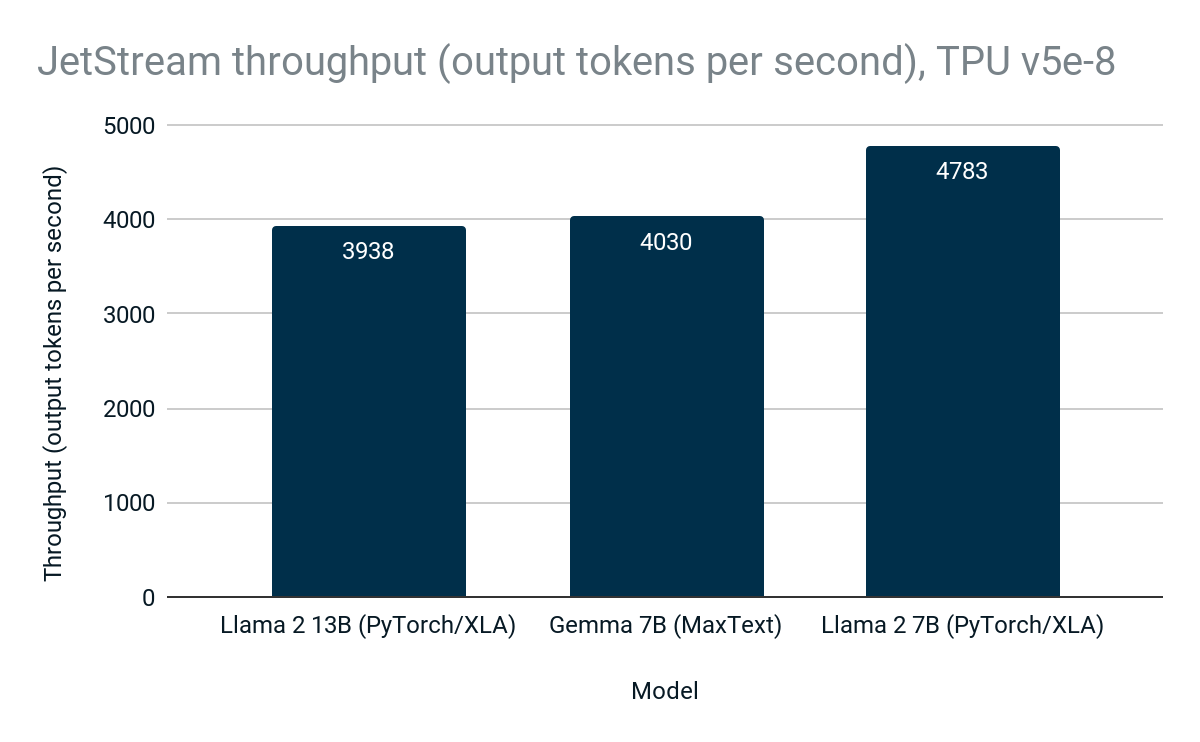
図 2: JetStream のスループット(出力トークン/秒)。Google 内部データ。Cloud TPU v5e-8 で Gemma 7B(MaxText)、Llama 2 7B(PyTorch/XLA)、Llama 2 13B(PyTorch / XLA)を使用して測定。入力最大文字数: 1024、出力最大文字数: 1024。連続的なバッチ処理、重み、アクティベーション、KV キャッシュの int8 量子化。PyTorch / XLA は Sliding Window Attention を使用。2024 年 4 月時点。
JetStream は高パフォーマンスで高効率であるため、Google Cloud 利用者が推論に支払う費用が少なくなり、LLM 推論がさらに安価で利用しやすくなります。
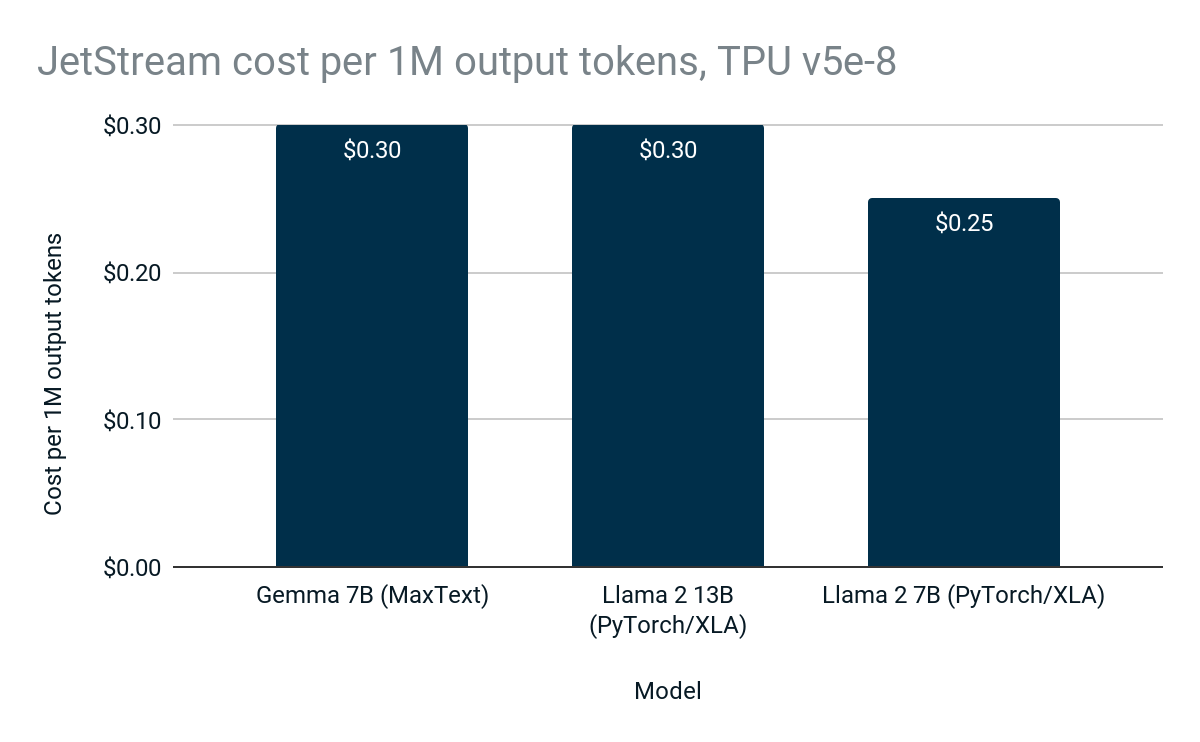
図 3: 100 万出力トークンを生成する際の JetStream の費用。Google 内部データ。Cloud TPU v5e-8 で Gemma 7B(MaxText)、Llama 2 7B(PyTorch/XLA)、Llama 2 13B(PyTorch / XLA)を使用して測定。入力最大文字数: 1024、出力最大文字数: 1024。連続的なバッチ処理、重み、アクティベーション、KV キャッシュの int8 量子化。PyTorch / XLA は Sliding Window Attention を使用。JetStream(100 万トークンあたり 0.30 ドル)は、Gemma 7B を利用する場合、以前の Cloud TPU LLM 推論スタック(100 万トークンあたり 1.10 ドル)と比べると、料金あたりの推論回数が最大 3 倍。費用は米国における Cloud TPU v5e-8 の CUD 3 年の価格に基づきます。2024 年 4 月時点。
Osmos をはじめ、さまざまなお客様が JetStream を利用して LLM 推論ワークロードを高速化しています。
「Osmos はさまざまな企業がデータ処理の自動化を通じてビジネスの関係性を発展させることができるよう支援するために、AI によるデータ変換エンジンを開発しました。お客様やビジネス パートナーから受信したデータは乱雑としていて標準化されていないことが多いため、データの各行に AI を適用してマッピング、検証、変換を行い、使いやすい良好なデータにする必要があります。そのためには、トレーニング、ファインチューニング、推論を行えるように、高パフォーマンスでスケーラビリティに優れ、費用対効果の高い AI インフラストラクチャが必要でした。当社がエンドツーエンド AI ワークフロー向けに、MaxText、JAX、JetStream を搭載した Cloud TPU v5e を選んだのは、まさにそうした理由からです。Google Cloud のおかげで、MaxText を使用して Google の最新の Gemma オープンモデルを数十億のトークンですばやく簡単にファインチューニングし、そのモデルを JetStream を使用した推論用にデプロイできました。Cloud TPU v5e 上ですべて行えたのです。Google が提供している最適化された AI ハードウェア スタックとソフトウェア スタックのおかげで、数日もかからず数時間で成果を達成できました。」 – Osmos、CEO、Kirat Pandya 氏
Google は研究者や開発者に、LLM 推論のためのパワフルで費用対効果の高いオープンソースの基盤を提供することによって、次世代 AI アプリケーションを促進しています。経験豊富な AI 実務担当者も、LLM を始めたばかりの人も、JetStream を利用すると目的を短期間で達成でき、自然言語処理の新たな可能性を切り開くことができます。
JetStream で、LLM 推論の未来を今すぐ体験してみてください。Google の GitHub リポジトリにアクセスして JetStream の詳細をご覧になり、新たな LLM プロジェクトにさっそく取りかかりましょう。Google は Google Cloud カスタマーケアを通じて、GitHub で JetStream の開発とサポートを長期的に行ってまいります。当社との共同開発や、最先端技術のさらなる発展に貢献できるコミュニティにぜひご参加ください。
MaxDiffusion: 高パフォーマンスの拡散モデル推論
LLM が自然言語処理を変革しているのと同様に、拡散モデルもコンピュータ ビジョンの分野を変革しています。これらのモデルをデプロイするためにお客様が支払う費用を削減するため、Google はオープンソースの拡散モデルのリファレンス実装をまとめた MaxDiffusion を開発しました。これらの実装は JAX で記述されており、高パフォーマンスでスケーラビリティに優れ、カスタマイズ可能です。MaxText のコンピュータ ビジョン版だとお考えください。
MaxDiffusion は Cross Attention、畳み込み、高スループットの画像データ読み込みなど、拡散モデルのコア コンポーネントの高パフォーマンスな実装を取り揃えています。MaxDiffusion は適応性が高く、カスタマイズできるように設計されているため、画像生成の限界を押し広げようとしている研究者にも、最先端の生成 AI 機能をアプリケーションに導入しようと模索している開発者にも、成果を達成するために必要な基盤を提供します。
新しい SDXL-Lightning モデルの MaxDiffusion 実装では、Cloud TPU v5e-4 で 6 画像/秒を達成しました。スループットは直線的にスケールして、Cloud TPU v5e-8 では 12 画像/秒となるため、Cloud TPU の高パフォーマンスとスケーラビリティを最大限に活用できます。
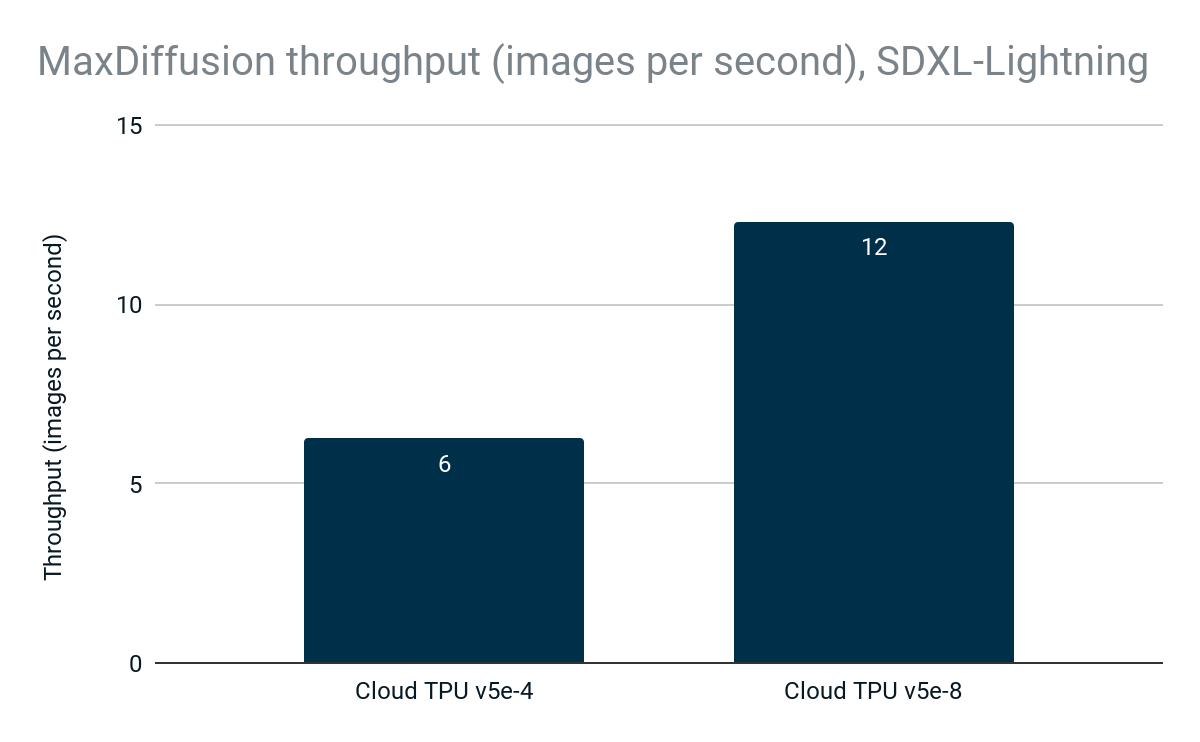
図 4: MaxDiffusion のスループット(1 秒あたりの画像数)。Google 内部データ。Cloud TPU v5e-4 と Cloud TPU v5e-8 で SDXL-Lightning モデルを使用して測定。解像度: 1024x1024、デバイスあたりのバッチサイズ: 2、デコード ステップ数: 4。2024 年 4 月時点。
MaxText や JetStream と同様に MaxDiffusion も費用対効果が高く、Cloud TPU v5e-4 または Cloud TPU v5e-8 で 1,000 枚の画像を生成する際の費用はわずか 0.10 ドルです。

図 5: 1,000 枚の画像を生成する際の MaxDiffusion の費用。Google 内部データ。Cloud TPU v5e-4 と Cloud TPU v5e-8 で SDXL-Lightning モデルを使用して測定。解像度: 1024x1024、デバイスあたりのバッチサイズ: 2、デコード ステップ数: 4。費用は米国における Cloud TPU v5e-4 および Cloud TPU v5e-8 の CUD 3 年の価格に基づきます。2024 年 4 月時点。
Codeway などのお客様は、Google Cloud を利用して大規模な拡散モデル推論の費用対効果を最大限に高めています。
「Codeway は世界 160 か国の 1 億 1,500 万人以上が利用する人気のアプリやゲームを開発しています。たとえば、言葉からデジタルアートワークを作り出す AI 搭載のアプリ『Wonder』や、いろいろな楽しいアニメーションで顔をダンスさせる『Facedance』などは当社のプロダクトです。1 億人もの利用者の手元で簡単に AI を利用できるようにするには、スケーラビリティと費用対効果の高い推論インフラストラクチャが必要です。Cloud TPU v5e を利用したところ、他の推論ソリューションと比べて、拡散モデルのサービングにおけるサービング時間が 45% 短縮され、1 時間あたりにサービングできるリクエスト数が 3.6 倍になりました。それによって、当社の規模だとインフラストラクチャ費用の大幅な削減になりますし、費用対効果の高い方法で AI 搭載アプリをさらに多くの利用者に提供できるようにもなります。」 – Codeway、DevOps 責任者、Uğur Arpacı 氏
MaxDiffusion は画像生成用の高パフォーマンスでスケーラビリティに優れた柔軟な基盤を提供します。経験豊富なコンピュータ ビジョンの専門家も、画像生成の世界に足を踏み入れたばかりの人も、MaxDiffusion が大いに助けになるでしょう。
Google の GitHub リポジトリにアクセスして、MaxDiffusion の詳細をご覧になり、新たなクリエイティブ プロジェクトの構築を今すぐ始めましょう。
A3 VM: MLPerf™ Inference 4.0 で優れた結果を発揮
2023 年 8 月に、A3 VM の一般提供開始について発表しました。A3 は単一の VM で 8 基の NVIDIA H100 Tensor Core GPU を使用しており、要求の厳しい生成 AI ワークロードや LLM のトレーニングとサービングに特化して構築されています。NVIDIA H100 GPU を使用した A3 Mega は、来月から一般提供を開始する予定で、GPU 間のネットワーキング帯域幅が A3 と比べて 2 倍になります。
MLPerf™ Inference v4.0 ベンチマーク テストでは、Google は A3 VM を使用して、新しい Stable Diffusion XL や Llama 2(70B)のベンチマークを含め、7 種類のモデルで 20 件の結果を提出しました。
-
RetinaNet(サーバーおよびオフライン)
-
3D U-Net: 99% および 99.9% の精度(オフライン)
-
BERT: 99 および 99% の精度(サーバーおよびオフライン)
-
DLRM v2: 99.9% の精度(サーバーおよびオフライン)
-
GPT-J: 99% および 99% の精度(サーバーおよびオフライン)
-
Stable Diffusion XL(サーバーおよびオフライン)
-
Llama 2: 99% および 99% の精度(サーバーおよびオフライン)
どの結果も、NVIDIA が提出した結果で実証されているピーク時のパフォーマンスから 0~5% 以内に収まるものでした。これらの結果はまさに、Google Cloud が NVIDIA と密接に連携し、ワークロードに最適化されていて LLM や生成 AI に特化したエンドツーエンド ソリューションを開発していることの証です。
Google Cloud TPU と NVIDIA GPU で AI の未来を切り拓く
Google Cloud TPU と NVIDIA GPU のハードウェアの進歩によって実現した、AI 推論分野における Google のイノベーションと、JetStream、MaxText、MaxDiffusion などのソフトウェアのイノベーションによって、AI アプリケーションの構築とスケーリングを簡単に行えるようになりました。JetStream を利用すると、開発者は LLM 推論のパフォーマンスと費用対効果を新たなレベルに引き上げ、自然言語処理アプリケーションの新たな可能性を見出すことができます。MaxDiffusion は、研究者や開発者が拡散モデルが秘めている潜在能力を探り、画像生成を高速化するための基盤を提供します。NVIDIA H100 Tensor Core GPU を使用した A3 VM が MLPerf™ Inference 4.0 で優秀な結果を発揮したことも、Cloud GPU のパワーと汎用性を示す証拠です。
Google のウェブサイトで、Google Cloud TPU と GPU 推論の詳細をご覧になり、今すぐ利用を始めましょう。
ー グループ プロダクト マネージャー、Alex Spiridonov

