Gemini で教師ありファインチューニングをいつ使用するか
Erwin Huizenga
AI engineering and evangelism manager
May Hu
Product Manager
※この投稿は米国時間 2024 年 10 月 5 日に、Google Cloud blog に投稿されたものの抄訳です。
基盤モデルに特定のスタイルで応答させたい、分野固有の専門知識を発揮させたい、特定のタスクで優れた成果を上げさせたい、と思ったことはありませんか?Gemini のような基盤モデルは、すぐに使える優れた機能を発揮しますが、その一方で一般的な知識と特定の用途に必要な微細な理解との間にギャップが生じることがあります。
教師ありファインチューニング(SFT)は、このギャップを埋めるオプションの一つとして生まれました。特殊なタスク、分野、さらには文体のニュアンスに合わせて、これらの強力なモデルをカスタマイズする機能を提供します。開発者の方々からは、SFT を使用するタイミングや、プロンプト エンジニアリング、コンテキスト内学習、RAG などのオプションとの比較についてよく質問を受けます。
この記事では、SFT とは何か、SFT をいつ採用すべきか、そしてモデル出力の最適化において他の方法とどのように違うかについて詳しく説明します。
教師ありファインチューニングとは
多くの場合、大規模言語モデル(LLM)の開発は事前トレーニングから始まります。この段階では、モデルは大量のラベルなしテキストから一般的な言語理解を学習します。事前トレーニングの主な目的は、モデルに幅広い言語理解力を身につけさせることです。こうした事前トレーニング済み LLM は、多くのタスクで卓越したパフォーマンスを示しています。この事前トレーニング済みモデルを適合させて、財務文書の要約など、より具体的な理解が必要となるダウンストリームのユースケースにおいてパフォーマンスを向上させることが可能です。
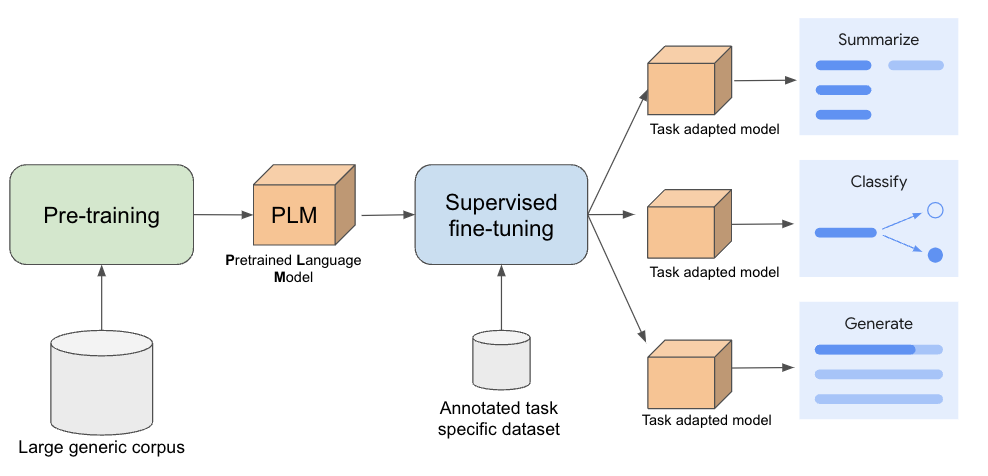
これらのユースケースにモデルを適合させるために、タスク固有のアノテーション付きデータセットを使用して事前トレーニング済みモデルをファインチューニングします。このデータセットには、入力例(収益レポートなど)とそれに対応する望ましい出力(要約など)が含まれています。入力を正しい出力に関連付けることで、モデルは特定のタスクの実行方法を学習します。アノテーション付きデータセットをファインチューニングに使用する場合、それを教師ありファインチューニング(SFT)と呼びます。
モデル パラメータは、モデルの動作を調整する主要なメカニズムであり、トレーニング プロセス中に学習した数値です。ファインチューニング中に更新するモデル パラメータ数は異なる場合があります。一般的な 2 つの教師ありファインチューニングのアプローチを次に示します。
-
フル ファインチューニング: すべてのモデル パラメータを更新します。ただし、フル ファインチューニングを行うと、チューニングとサービングのためのコンピューティング リソースが大量に必要になり、全体的な費用が高くなります。
-
パラメータ エフィシエント ファインチューニング(PEFT): 元のモデルを固定して、新しく追加された少数のパラメータのみを更新する手法群を指し、より高速でリソース効率の高いファインチューニングを可能にします。PEFT は、大規模なモデルを適合させる場合やコンピューティング リソースが限られている場合に特に有効です。
フル ファインチューニングと PEFT はどちらも教師あり学習手法と見なされますが、実行するパラメータ更新の範囲が異なり、ユースケースによってはどちらか一方が適している場合があります。たとえば、Vertex AI の Gemini モデルの教師ありファインチューニングでは、PEFT 手法である LoRA(Low-Rank Adaptation)が使用されています。
教師ありファインチューニングをいつ使用するか
明確に定義されたタスクでモデルのパフォーマンスを向上させることを目標としていて、高品質なアノテーション付きサンプルのデータセットにアクセスできる場合は、SFT の使用を検討してください。事前トレーニング済みモデル内にすでに存在する関連知識を効率的に活性化、改良するには教師ありファインチューニングが効果的です。特にタスクが元の事前トレーニング データと整合性がある場合に効果が顕著になります。SFT が効果を発揮するシナリオをいくつかご紹介します。
-
特定分野の専門知識: 専門知識をモデルに注入し、法律、医療、金融などの分野における専門家に変貌させます。
-
形式のカスタマイズ: 特定の構造または形式に準拠するようにモデルの出力をカスタマイズします。
-
タスク固有の能力: 短い要約など、明確に定義されたタスクに合わせてモデルを最適化します。
-
エッジケース: 特定のエッジケースや珍しいシナリオへの対応能力を向上させます。
-
動作制御: 簡潔な応答をすべき時と詳細な応答をすべき時がいつであるかなど、モデルの動作をガイドします。
SFT の強みの一つは、高品質なトレーニング データの量が限られていても改善を実現できることであり、多くの場合、フル ファインチューニングよりも費用対効果の高い代替手段になります。さらに、ファイン チューニングされたモデルは操作しやすくなる傾向があります。SFT を通じて、モデルはタスクを効果的に実行する方法を学習し、推論時における長く複雑なプロンプトの必要性が低減します。それが、費用削減と推論レイテンシの低減につながります。
SFT は既存の知識を強化するのに最適ですが、すべての課題を解決できるわけではありません。リアルタイム データの組み込みなど、動的な情報や変化し続ける情報を含むシナリオには、最適なソリューションではないかもしれません。このようなケースでは他の手法の方が適している場合もあるので、そうした他のオプションについても見ていきましょう。
LLM カスタマイズのその他のオプション
SFT は効果的な手法ですが、LLM の出力をカスタマイズする唯一の、または最適なソリューションであるとは限りません。他にもモデルの動作を適合させる効果的な手法はいくつかありますが、それぞれに長所と短所があります。
プロンプト エンジニアリングは、簡単に始められて出力を制御できる、低コストで利用しやすい方法です。ただ、複雑なタスクや繊細なタスクを処理するには信頼性が低く、専門知識とテストが必要になります。
コンテキスト内学習(ICL)は、プロンプト内の例を活用して LLM の動作を導くもので、プロンプト エンジニアリングと同様に簡単に始められます。ICL は、少数ショット プロンプトとも呼ばれ、プロンプトで提供される例とその順序に左右される場合があります。また、うまく一般化できないこともあります。
検索拡張生成(RAG)は、Google 検索やその他のソースから関連情報を取得し、それを LLM に提供することで品質と精度を向上させます。これには十分なナレッジベースが必要であり、追加の手順により複雑さとレイテンシが増大します。
関数呼び出しは、ユーザーのリクエストを満たすために外部システムが必要かどうかを識別し、これらのツールとやり取りし、機能を高めるための構造化された関数呼び出しを生成する言語モデルの機能です。使用すると、レイテンシと複雑さが増す可能性があります。
どこから始めるべきか
ここまで学習してきて、何が適切な方法であるのか気になっているのではないでしょうか。最適な進め方は、ユースケース固有のニーズ、リソース、目的によって異なることを理解することが重要です。これらの手法は相容れないものではなく、組み合わせて使用されることも多々あります。ここで、意思決定の指針となるフレームワークについて考えてみましょう。
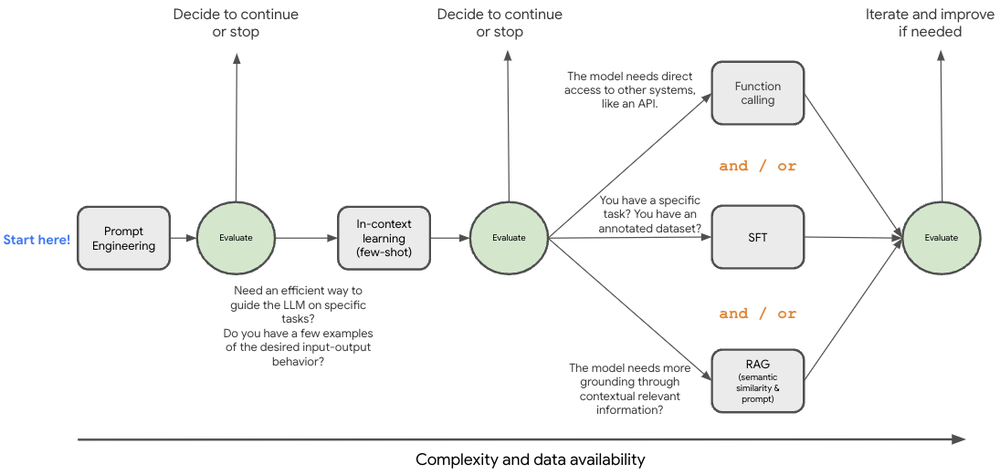
まず、プロンプト エンジニアリングと少数ショットのコンテキスト内学習を試して、モデルが特定の専門分野のニュアンスを理解できるかどうかを確認します。Gemini の大きなコンテキスト ウィンドウは、この段階でさまざまな可能性を提供します。プロンプト戦略に磨きをかけたら、検索拡張生成(RAG)や教師ありファインチューニング(SFT)を試して、さらに改良を加えることが可能です。この図は最新の手法の一部を表していますが、生成 AI の分野は急速に変化しており、今後も進化していく可能性があります。
Vertex AI の Gemini で教師ありファインチューニングの威力を最大化
教師ありファインチューニング(SFT)は、特定のタスクを念頭に置いており、モデルをガイドするためのラベル付きデータを持っている場合に最適です。SFT はより効率的なモデルを実現し、費用の削減や応答時間の短縮につながる可能性があり、すでに試している他の手法と組み合わせて使用することもできます。
ご関心をお持ちの場合は、生成 AI リポジトリにアクセスし、教師ありファインチューニングの使用方法などのノートブックをご覧ください。Vertex AI で SFT の変革の可能性を体感し、AI アプリケーションをカスタマイズして最高のパフォーマンスを実現してください。
Gemini モデルのファインチューニングが目的の方は、Vertex AI ドキュメントでカスタマイズ可能なモデルをご確認ください。
今回協力してくれた Google Cloud の Bethany Wang、Mikhail Chrestkha、Christos Aniftos、Elia Secchi に感謝します。
— Google、ML 担当エンジニア Erwin Huizenga
— Google、プロダクト マネージャー May Hu


