カスタム ML モデルを Google Cloud に移行するための 3 つのステップ
Google Cloud Japan Team
※この投稿は米国時間 2020 年 9 月 25 日に、Google Cloud blog に投稿されたものの抄訳です。
多くの企業において、エンドツーエンドのパイプラインの構築が重視されるようになってきています。これは、機械学習モデルを持つことは、機械学習に基づくアプリケーションの本番環境の稼働に向けて、小さな一歩を踏み出したにすぎないという認識によるものです。
Google Cloud は、モデルの大規模なトレーニングとデプロイを行うツールである Cloud AI Platform を提供しています。このツールは、TensorFlow Extended や KubeFlow Pipelines(KFP)などの複数のオーケストレーション ツールと統合できます。ただし、scikit-learn や xgboost のようなフレームワークを使用して独自のエコシステムで構築されたモデルを持っている企業も多く、こうしたモデルをクラウドに移行するには複雑で時間がかかる場合があります。
Google Cloud Platform(GCP)の ML の扱いに慣れていたとしても、scikit-learn モデル(または同等モデル)を AI Platform に移行する作業には時間がかかります。その原因は、関連するボイラープレートにあります。ML Pipeline Generator は、ユーザーが既存の ML モデルを GCP に簡単にデプロイできるようにするツールであり、サーバーレス モデルのトレーニングとデプロイや、ソリューションの市場投入までの時間短縮といったメリットが得られます。
本ブログでは、このソリューションが機能する仕組み、ユーザーに必要な操作、AI Platform で TensorFlow のトレーニング ジョブをオーケストレーションするための手順について紹介します。
概要
ML Pipeline Generator を使用すると、scikit-learn、XGBoost、TensorFlow の構築済みのモデルを持つユーザーが、独自のコードとデータを使用して、GCP 上でエンドツーエンドの ML パイプラインをすばやく生成して実行できます。
そのためには、コードのメタデータを記述する構成ファイルに値を入力する必要があります。ライブラリはその構成ファイルを受け取り、テンプレート エンジンを使用して必要なすべてのボイラープレートを生成します。これにより、クラウド上でオーケストレーションされた方法でモデルのトレーニングとデプロイが行えるようになります。さらに、TensorFlow モデルをトレーニングしたユーザーは、Explainable AI 機能を使用してモデルをより深く理解することができます。
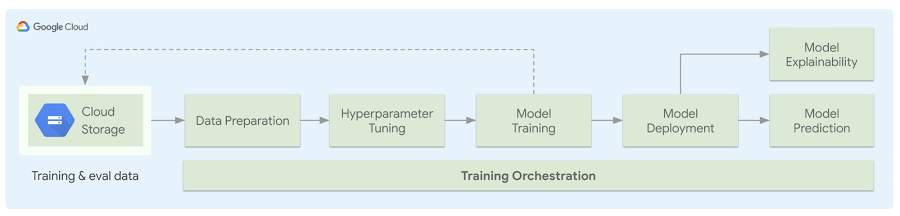
以下の図は、生成されたパイプラインのアーキテクチャを示しています。ユーザーが独自のデータを持ち込み、データの前処理を実行する方法を定義し、ML モデルのファイルを追加します。構成ファイルへの入力が完了すると、単純な Python API を使用して自己完結型のボイラープレート コードが生成されます。これにより、指定された前処理の実行、Google Cloud Storage(GCS)へのデータのアップロード、ハイパーパラメータ調整を使用したトレーニング ジョブの開始が行われます。これが完了すると、モデルがデプロイされて提供されるようになり、モデルタイプに応じてモデルの説明可能性が実行されます。このプロセス全体を Kubeflow Pipelines を使用してオーケストレーションできます。
手順ガイド
モデル構成パラメータとモデルコードを指定し、モデルをトレーニングして提供するエンドツーエンドの Kubeflow Pipelines を構築する方法を説明します。ここでは、パイプラインを構築して、国勢調査所得データセットで浅い TensorFlow モデルをトレーニングします。モデルは Cloud AI Platform でトレーニングされ、Kubeflow UI でモニタリングできます。
準備
ソリューションを完全に使用できるようにするために、GCP でいくつかの項目を設定する必要があります。
1. このデモを実行するには Google Cloud プロジェクトが必要です。そのため、新しいプロジェクトを作成し、プロジェクトで次の API が有効になっていることを確認してください。
- Compute Engine
- AI Platform Training and Prediction
- Cloud Storage
2. Google Cloud SDK をインストールして、コマンドラインから必要な GCP サービスにアクセスできるようにします。SDK をインストールしたら、上記で作成したプロジェクトのプロジェクト ID を使用して、アプリケーションのデフォルト認証情報を設定します。
gcloud auth login
gcloud auth application-default login
gcloud config set project [PROJECT_ID]
3. このソリューションを使用して Kubeflow Pipelines に ML モデルをデプロイする場合は、プロジェクトの AI Platform Pipelines に新しい KFP インスタンスを作成します。インスタンスのホスト名([vm-hash]-dot-[zone].pipelines.googleusercontent.com という形式のダッシュボード URL)をメモします。
4. 最後に、データとモデルを GCS に保存できるようにバケットを作成します。バケット ID をメモします。
ステップ 1: 環境を設定する
デモコードの GitHub リポジトリのクローンの作成と、Python 仮想環境の作成を行います。
ml-pipeline-gen パッケージをインストールします。
pip install ml-pipeline-gen
モデルを利用できるようにするうえで、以下の重要なファイルがあります。
1. examples/ ディレクトリには、sklearn、TensorFlow、XGBoost の各モデル用のサンプルコードが含まれています。TensorFlow モデルを Kubeflow Pipelines にデプロイするために、examples/kfp/model/tf_model.py を使用します。独自のモデルを使用している場合には、そのモデルコードで tf_model.py ファイルを変更できます。
2. examples/kfp/model/census_preprocess.py は、国勢調査所得データセットをダウンロードして、それをモデル用に前処理します。カスタムモデルの場合、必要に応じて前処理スクリプトを変更できます。
3. このツールは、パイプラインのアーティファクトを作成するために必要なメタデータに、config.yaml ファイルを使用しています。examples/kfp/config.yaml.example テンプレート ファイルを開くとメタデータ パラメータのサンプルを確認できます。また、詳細なスキーマについてはこちらで見つけることができます。
4. Cloud AI Platform のハイパーパラメータ調整機能を使用する場合、パラメータを hptune_config.yaml ファイルに含め、そのパスを config.yaml に追加します。hptune_config.yaml のスキーマについては、こちらでご確認いただけます。
ステップ 2: 必要なパラメータを設定する
1. kfp/ サンプル ディレクトリのコピーを作成します。
cp -r examples/kfp kfp-demo
cd kfp-demo
2. config.yaml.example テンプレートを使用して config.yaml ファイルを作成し、以下のパラメータをプロジェクト ID、バケット ID、先ほどメモした KFP ホスト名、モデル名で更新します。
ステップ 3: パイプラインを構築してモデルをトレーニングする
構成パラメータの設定が完了したら、TensorFlow モデルをトレーニングするためのパイプラインを構築するモジュールを生成します。demo.py ファイルを実行します。
python demo.py
Kubeflow Pipelines デモの初回実行時に、ツールはダッシュボード URL を変更する GKE クラスタの Workload Identity をプロビジョニングします。モデルをデプロイするには、config.yaml の URL を更新して、デモを再実行します。
demo.py スクリプトは、国勢調査データセットを Cloud Storage の公開バケットからダウンロードし、examples/kfp/model/census_preprocess.py に従ってトレーニングと評価のために準備してから、config.yaml に指定されている Cloud Storage URL にデータセットをアップロードします。次に、トレーニング用のパイプライン グラフを作成して、Kubeflow Pipelines アプリケーション インスタンスにテストとしてアップロードします。
グラフが実行のために送信されたら、Kubeflow Pipelines UI で進捗状況をモニタリングできます。Cloud AI Platform Pipelines ページを開き、Kubeflow Pipelines クラスタのダッシュボードを開きます。
注:
Scikit-learn または XGBoost の例を使用する場合は、上記と同じ手順で実行できます。ただし、Kubeflow Pipelines インスタンスを作成する追加の手順を行わずに、上記と同様の変更を examples/sklearn/config.yaml に加えます。詳しくは、公開リポジトリの手順をご参照いただくか、Jupyter ノートブックに記載されているエンドツーエンドのチュートリアルに従ってください。
まとめ
このブログでは、トレーニングとデプロイ用のカスタム ML モデルを 3 つの簡単な手順で Google Cloud に移行する方法について紹介しました。面倒な作業のほとんどをソリューションが行うため、ユーザーはデータの持ち込み、モデルの定義、トレーニングとサービスをどのように処理するかを提示するだけです。
ここでは、1 つの例を詳しく取り上げましたが、公開リポジトリにはサポートされている他のフレームワークの例が含まれています。このツールを活用して、機械学習ワークロードにおける Google Cloud の数多くのメリットを実現しましょう。詳細については、公開リポジトリをご覧ください。Kubeflow Pipelines とその機能について詳しくは、Google Cloud Next ‘19 のこちらのセッションをご覧ください。
謝辞
この投稿に尽力していただいた、Chanchal Chatterjee、Stefan Hosein、Michael Hu、Ashok Patel、Vaibhav Singh(姓のアルファベット順)に感謝します。
-AI エンジニア Stefan Hosein
-AI エンジニア Michael Hu





{kind=link}