エッジで AI ユースケースを構築・実行する方法
Google Cloud Japan Team
※この投稿は米国時間 2023 年 8 月 4 日に、Google Cloud blog に投稿されたものの抄訳です。
ビジョン ML モデルをエッジで実行して処理すると、さまざまなユースケースをサポートできます。たとえば、スタッフの個人用防護具(PPE)着用の徹底、店頭や倉庫の在庫管理、組み立てラインでの予測メンテナンスなど、カスタマー エクスペリエンスを向上させることが可能です。しかし、AI の最新化と活用、ミッション クリティカルなデータの管理、複雑な複数のエッジへのデプロイ管理が、越え難い障壁になる可能性があります。
人工知能(AI)と機械学習(ML)テクノロジーは、予測メンテナンス、工場の安全対策、音声認識などの産業用ユースケースで広く利用されています。これらのユースケースでは、製造施設、医療施設、小売店、車両などのエッジ ロケーションに AI モデルをデプロイする必要があります。パブリック クラウドとエッジ ロケーション全体に大規模に AI ワークロードをデプロイして管理することは、多くのお客様にとって簡単なことではありません。Google Cloud は、パブリック クラウド、エッジ ロケーション、デバイス上で AI アプリケーションを大規模に実行および管理するための一連のテクノロジーとプラットフォームを提供します。
Google Cloud でエッジのデータと AI を最適化
Google Cloud により、Vertex AI Platform を使用して産業用 AI アプリケーションを簡単に開発、デプロイ、運用できるようになりました。Vertex AI Platform は、製品認識、タグ認識、その他の Vision AI モデルや Video AI モデルなど、高品質の事前トレーニング済みモデルを提供します。デベロッパーは、Vertex AI Platform を使用してモデルをトレーニングし、さまざまなユースケースに合わせて画像推論サービスを呼び出せます。エッジの AI アプリケーションでは、オブジェクト認識などのカスタムモデルの開発が必要になる場合もあります。Vertex AI Platform では、カスタムモデルを作成・トレーニングして、エッジ ロケーションにデプロイできます。
Google Distributed Cloud(GDC)を利用することで、デベロッパーは Google の最高水準の AI、セキュリティ、オープンソースを活用し、お客様がどこにいてもミッション クリティカルなデータの独立性を維持しながら制御できます。これには、小売、製造、輸送などのエンタープライズ ワークロードに対応したフルマネージド ソフトウェアおよびハードウェア プロダクトである Google Distributed Cloud Edge(GDC Edge)や、行政機関や規制対象企業が厳格なデータ所在地とセキュリティ要件に対応できるようにするエアギャップ型プライベート クラウド ソリューションの Google Distributed Cloud Hosted(GDC Hosted)が含まれています。
Edge TPU は AI をエッジで実行する目的に特化して Google が設計した専用 ASIC です。低消費電力、小フットプリントで高パフォーマンスを実現し、高精度の AI をエッジにデプロイできます。Edge TPU は、Cloud TPU と Google Cloud サービスを補完し、エンドツーエンド(クラウドツーエッジ、ハードウェア + ソフトウェア)のインフラストラクチャを提供します。これにより、お客様の AI ベース ソリューションのデプロイが簡単になります。単なるハードウェア ソリューションではなく、カスタム ハードウェアやオープン ソフトウェア、最先端の AI アルゴリズムを組み合わせて、エッジ向けの高品質でデプロイしやすい AI ソリューションを提供します。Edge TPU により、Coral のさまざまなプロトタイピング用プロダクトと本番環境用プロダクトを使用して、高品質な ML 推論をエッジにデプロイできます。Edge TPU は、エッジで AI を実行するための CPU、GPU、FPGA などの ASIC ソリューションを補完します。
今回の投稿では、Google Vertex、Google Distributed Cloud、Edge TPU を使用してエッジでビジョンベースの ML モデルを構築、トレーニング、デプロイし、在庫検出、PPE 検出、予測メンテナンスなどの業界事例をサポートする方法を学びます。
エッジでの学習
AI ワークロードをエッジ ロケーションにデプロイする場合、すべてのユースケースで、パブリック クラウドを拡張した適切なトポロジにトレーニング済みモデルをデプロイする必要があります。それらはハイパーバイザを使用する大規模サーバー ファームであったり、センサーやカメラなどのデバイスであったり、多岐にわたります。 これらの場所にまたがってアプリケーションを開発し、実行する際に、デベロッパーには一貫性のあるエクスペリエンスが必要になります。プラットフォーム オペレーターは、アプリケーションが実行されている場所に関係なく、アプリケーションを簡単に管理、モニタリングできる必要があります。
GDC プラットフォームを使用することで、お客様は Google Cloud Edge TPU または GPU に ML モデルをデプロイできます。GPU と TPU は AI ワークロードを可能にするだけでなく、コンピューティングの高速化、グラフィック アプリケーションのパフォーマンス強化、ディープ ラーニング、エネルギー効率、スケーラビリティなどの利点も提供します。ML モデルは、Cloud TPU または Cloud GPU を使用してトレーニングし、GDC にデプロイできます。 このブログでは、エッジ ワークロード用に GPU と Edge TPU の両方を構成する方法について説明します。
GPU は、Google Distributed Cloud(GDC)デプロイメントを使用してエッジ ネットワーク上で AI / ML ワークロードを実行するために使用できます。NVIDIA T4 および A100 GPU をサポートしており、エッジ ロケーションやデータセンターで AI ワークロードを実行できます。お客様は、NVIDIA の GPU デバイス プラグインをハードウェアに直接デプロイし、高性能 ML ワークロードを実行できます。
エッジ ネットワーク上で本番環境用モデルをデプロイおよび管理する ML ワークフローは、以下の段階を経て進行します。
データの準備
モデルの開発
モデルのトレーニング
モデルのデプロイ
予測のモニタリング
バージョン管理
Vertex AI と GDC はこのプロセスを合理化し、エッジ ネットワーク上で AI ワークロードを大規模に実行できるようにします。Google Kubernetes Engine(GKE)を使用すると、Google Cloud での ML 推論、トレーニング、データの処理に TPU または GPU を必要とするコンテナ化された AI ワークロードを実行できます。これらの AI ワークロードは、GDC を使用してエッジ ネットワーク上の GKE で実行できます。「マジックミラー」による小売ビジョン AI のユースケースをサポートした Google Distributed Cloud Edge の詳細をご覧ください。「マジックミラー」は、T-Mobile と Google Cloud のパートナーシップにより生まれた、クラウドベースの処理とエッジでの画像レンダリングを活用したインタラクティブ ディスプレイで、小売商品に「魔法のように」命を吹き込みます。 次のセクションでは、AI モデルのデプロイと管理のエンドツーエンドのアーキテクチャについて説明していきます。
エンドツーエンドの ML
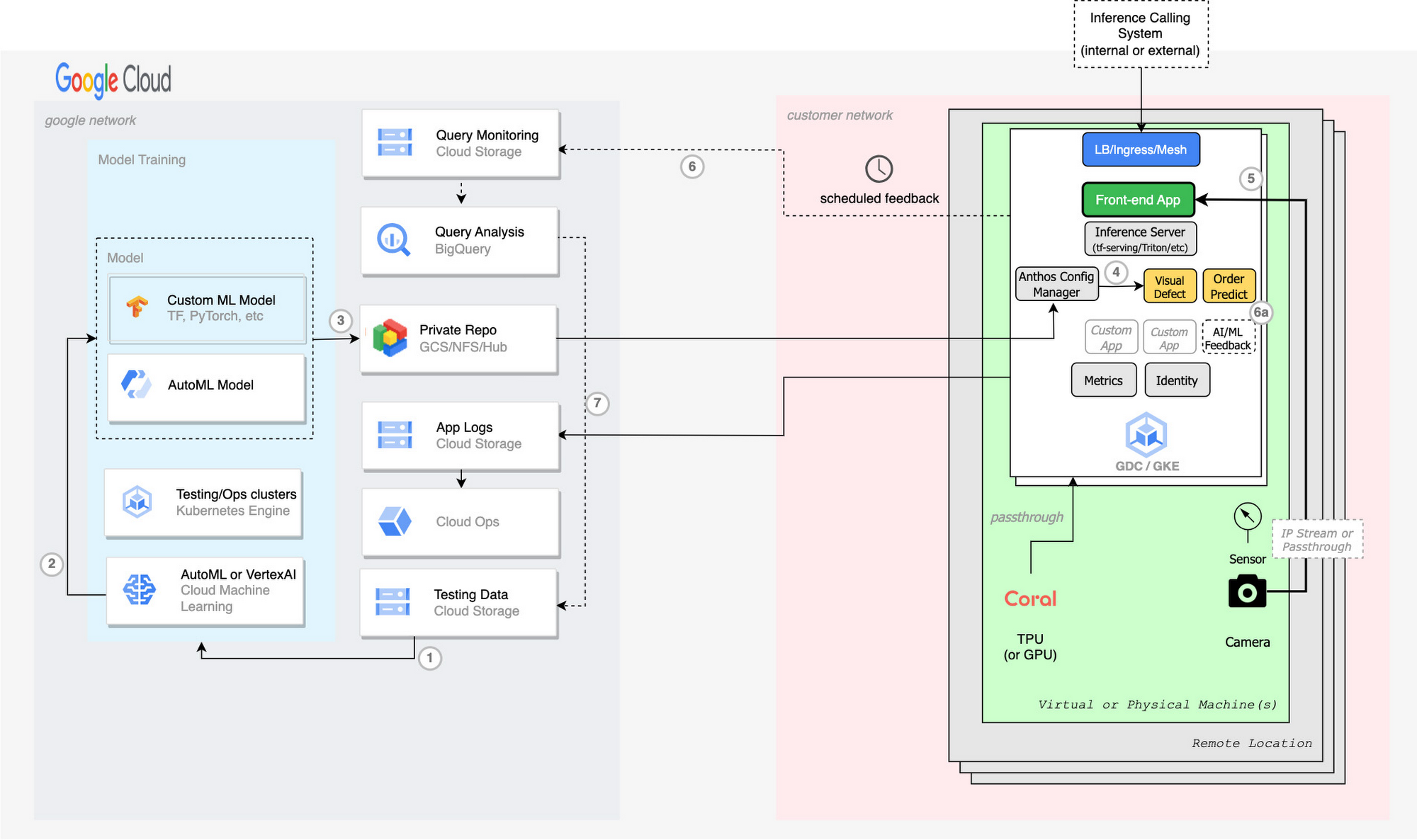
- Vertex AI 上のラベル付きデータまたはアノテーション付きデータを使用してモデルをトレーニングする
- Vertex AI からモデルをエクスポートする
- エクスポートされたモデルを GCS バケットまたはプライベート AI Hub リポジトリに push する
- 各クラスタは、Anthos Config Manager(ACM)を介して、TF Serving または Inference Server デプロイ上の KRM(YAML K8s 構成)を使用して新しいモデルを pull する
- (省略可)パーセンテージ結果(6)またはカスタムの人間による検証アプリケーション(6a)を介してフィードバックをエクスポートする。GCS バケットへエクスポートする
- BigQuery を使用して ML モデルの効率を分析し、ラベル、アトリビューション、分類器、品質などへの変更を特定して、テストデータに push する(7)
次のセクションでは、vGDC で Edge TPU と GPU を構成する手順について説明します。
Edge TPU の構成
Linux、Windows、macOS を実行しているプラットフォーム向けに開発している場合は、Python または C/C++ のいずれかで TensorFlow Lite を使用するよう選択できます。
選択した言語にかかわらず、各 Coral デバイスのセットアップに記載されているように、Edge TPU ランタイム(libedgetpu.so)をインストールする必要があります。次に、適切な TensorFlow Lite ライブラリとオプションの Coral ライブラリが必要になります。
モデルのコンテナ化にはカスタム開発が必要です。
GPU の構成
以下では、GDC Virtual または Edge Anthos GKE プラットフォームで K8s ワーカー用に NVIDIA T4 GPU を構成する方法をご紹介します。
前提条件:
1. ロールと権限の構成。
1. SELinux を無効にする
3. SELinux が有効な場合は、特権の Security Context を使用してプラグイン DaemonSet を実行する
2. 依存関係:
1. OS にインストールされている Cuda 依存関係
2. スクリプトまたは手動でNVIDIA-Linux ドライバをインストールする
3. Nvidia Docker ランタイムをインストールする
4. nvidia を指すように Kubernetes コンテナ ランタイムを構成する(* ほとんどの場合、containerd)
5. 各ノード上の Nvidia DaemonSet
6. サポートされているオペレーティング システム
3. テスト
1. nvidia-smi cli ツールを使用する
2. クラスタで gpu ワークロード テストを実行する
3. cmd check gpu: kubectl describe nodes を実行する
インストール:
1. セキュリティを構成する(SELinux, AppArmor)
SELinux を無効にするには、/etc/selinux/config 構成ファイルを開き、プロパティを SELINUX=disabled に変更します。
2. VM 上で bmctl コマンドを実行して、Anthos Bare Metal をセットアップする(使用するプロジェクトの所有者または編集者である必要があります)
3. Docker
ユーザーを Docker グループに追加する
VM を再起動して、Docker ユーザー グループの変更を有効にします。
4. Nvidia ドライバと cuda をインストールする
VM に ssh で接続し、次のコマンドを実行します。
エラーが発生した場合、または詳細が知りたい場合は、こちらのページを参照してください。
5. Nvidia Docker をインストールし、kubernetes のデフォルトのコンテナ ランタイムを nvidia に指定する
6. daemonset をインストールする(特権ユーザーとして実行する必要がある場合があります)
7. nvidia-smi cli を使用して確認し、kubectl describe node をチェックする。割り当て可能なリソースの下に、値 1 以上の「nvidia/gpu」が表示されているはずです。
次のステップ
エッジ コンピューティングは、これまでにないやり方で企業のデジタル トランスフォーメーションを加速させています。フルマネージド ハードウェアおよびソフトウェア ソリューションの包括的なポートフォリオを備えた Google Distributed Cloud では、Google Cloud の AI および分析ソリューションを、お客様のデータが生成、使用される場所の近くで提供できるため、デプロイ全体でリアルタイムの分析情報を活用できます。GKE は、AI ワークロードに対してクラウドとエッジ ネットワーク全体で一貫した管理エクスペリエンスを提供します。
Google Distributed Cloud Edge を使用した、Google の最新 AI によるエッジでのデータ活用方法について、詳細はこちらをご覧ください。
Google Distributed Cloud は、エッジ、プライベート データセンター、エアギャップ、ハイブリッド クラウド デプロイから最新の AI を使用してデータの潜在力を引き出せるプロダクト ファミリーです。企業や公共機関向けに提供されており、デベロッパーは、お客様がどこにいても、必要な独立性と制御のもとに Google の最高水準の AI、セキュリティ、オープンソースを活用できるようになりました。
2023 年 8 月 29~31 日にサンフランシスコのモスコーン センターで開催される Google Cloud Next で、Google Distributed Cloud によるデータの活用について詳しく学びましょう。
エッジで AI を実行して最新のカスタマー エクスペリエンスを提供セッション ARC 101
エアギャップに注意: クラウドは今日の主権ニーズにどのように対応しているのかセッション ARC100
アーキテクトと IT プロフェッショナルの次のステップ スポットライト SPTL202
Hardwareverse で Google Cloud ハードウェア上の AI のパワーを最大限に引き出します。
Hardwareverse: エッジでのリアルタイムの外観検査を体験インタラクティブ デモ HWV-101
Hardwareverse: エアギャップ型プライベート クラウドで主権のニーズに対応 - インタラクティブ デモ HWV-102
Hardwareverse: Cloud TPU で生成 AI モデル開発を強化 インタラクティブ デモ HWV-103
GPU リファレンスの構成に関する上記の詳細については、次の手順ガイドを参照してください。
- スタッフ テクニカル ソリューション コンサルタント、Abdul Haseen Kinadiyil
- カスタマー エンジニア、Yanni Peng



